独家:神经架构搜索研究指南
本指南列举了解决神经网络设计自动化这一富有挑战性任务的系列研究性论文。
从训练到不同参数的调整实验,神经网络的设计过程是劳动密集型的,富有挑战性,而且常常繁琐。但是想象一下,是否有可能实现这个过程的自动化?本指南将这一想象性的飞跃转化为现实。
在这里,我们将探索一系列的研究论文,试图解决自动化神经网络设计这一具有挑战性的任务。在本指南中,假设读者已经参与过采用Keras或TensorFlow等框架设计神经网络的过程。
基于强化学习的神经架构搜索(2022)
本文描述了如何利用递归神经网络(RNN)生成神经网络模型。而后,对RNN进行强化学习训练,以提高其在验证集上的准确性。该方法在CIFAR-10数据集上实现了3.65的误差率.
基于强化学习的神经架构搜索
神经网络是一种功能强大、灵活的模型,可以很好地处理图像、语音等方面的高难度学习任务...
本文提出一种基于梯度的神经架构搜索。利用可变长度的字符串来描述神经网络的结构和互联。一种称为控制器的神经网络用来生成可变长度的字符串,然后对字符串指定的子网络进行实际数据的训练,并在验证集上得到一个初始的准确性度量。然后使用此度量计算更新控制器的策略梯度,具备较高准确度的结构被赋予更高的概率。

图1,:神经架构搜索概略
在神经网络结构搜索时,控制器生成网络中的超参数。在下图中,控制器用于生成卷积神经网络。控制器预测过滤器的高度、宽度和步长,预测由Softmax分类器执行,然后作为输入,输入到下一时间步长。控制器完成了生成结构的过程之后,一个具有这种结构的神经网络便训练好了。
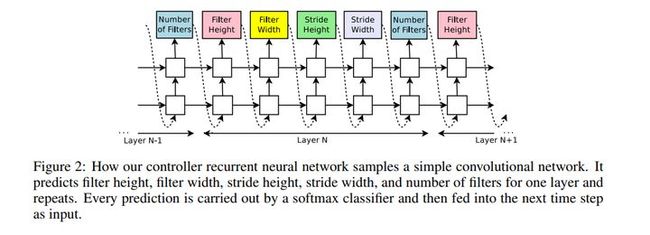
图2:循环神经网络的控制器对简单的卷积网络进行采样,预测过滤器的高度、宽度和步长。预测每一层过滤器的数目。预测由softmax 分类器执行,预测结果输入到下一个时间步长。
由于子网络的训练可能需要花费几个小时,为了加快控制器的学习过程,作者采用了分布式训练和异步参数更新。
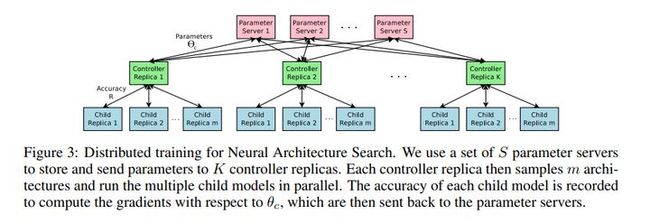
图3:神经结构搜索的分布式训练,采用S参数集存储和发送发给K控制器的参数,每个控制器对m架构采样后在各个子模型中并行运行。记录每个子模型的准确度,计算出精度,回送给参数服务器。
与其他模型相比,该模型的误差率如下所示:

表1 :神经架构搜索与其他模型在CIFAR-10测试集上的性能比较
当在移动环境下使用机器学习时,找出正确的神经网络结构的难度可能会更大一些。FritzAI拥有专业知识和工具,助力在正确的时间,在正确的设备上安装正确的模型。
可伸缩图像识别的学习转换架构(2022)
由于使用大型数据集将非常繁琐和耗时,所以,在本文中,作者首先构建在小数据集上的架构块,然后将该块转换到大型数据集中。
作者在CIFAR-10数据集上找出最佳卷积层,并将其应用于ImageNet数据集,通过堆叠叠加层的更多副本来实现。每个层都有自己的参数,用于设计卷积结构。作者将此架构称为NASNet架构。
此外,作者还引入了一种正则化技术-路径调度-改进了NASNet模型中的泛化。这种方法的误差率可达2.4%。最大的NASNet模型的平均精度可达到了43.1%。
可伸缩图像识别的学习转换架构
开发一个神经网络图像分类模型往往要求有重要的架构工程。在本文中...
和前面的文章类似,本文也使用了神经架构搜索(NAS)框架,文中提出的卷积网络的总体架构为手动预置,多次重复用到卷积单元。每个卷积单元具有相同的结构,但权重不同。
网络有两种类型的单元:标准单元——返回同维特征映射的卷积单元;还原单元 -返回特征映射的卷积单元,特征映射的高度和宽度减少了2倍。

图2:图像分类的可伸缩架构包括标准单元和还原单元,在本图中将CIFAR-10和ImageNet 模型架构高亮显示,根据经验选择标准单元和还原单元堆叠的层数
在本文提出的搜索空间中,每个单元接收两个初始隐藏状态作为输入,这两个初始隐藏状态是前两层的输出或是输入图像。RNN控制器在这两个初始隐藏状态下递归地预测卷积单元的其余结构。

图3:循环构建卷积单元的控制器模型架构,每个块需要选择5个离散参数,对应softmax 层的输出。右图是构建块的样例,一个卷积单元包含B个块,所以控制器包含5B 个softmax 层,根据经验,B 的数目取5。
下表是CIFAR-10数据集上神经架构搜索(NAS)的性能:
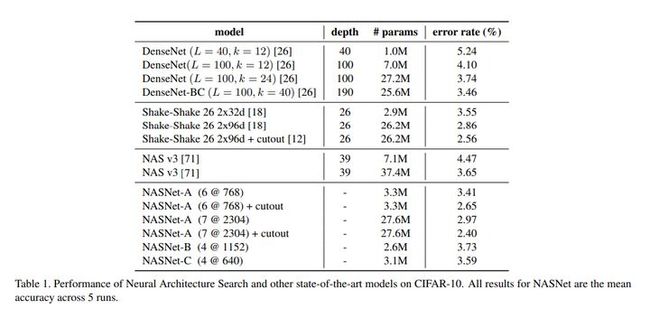
表1:神经架构搜索模型和其它模型之间的CIFAR-10测试性能比较。NASNet 的所有结果为运行5次的准确度的均值
基于参数共享的高效神经架构搜索(2022)
作者在文中提出了一种称为高效神经架构搜索(ENAS)法。在该方法中,控制器通过在大型计算图中搜索最优子图来查找神经网络结构,训练控制器试图选择一个在验证集上获得最佳准确度的子图。
然后以“最小化标准交叉熵损失”的标准对与所选子图对应的模型进行训练。为使ENAS能够获得更优的性能,通常在子模型之间共享参数。在CIFAR-10测试中,ENAS的误差率为2.89%,而神经结构搜索(NAS)的误差率为2.65%。
基于参数共享的高效神经结构搜索
作者提出了一种高效的神经网络架构搜索方法,为自动模型设计提供一种快速、经济的方法。在……
本文通过强制所有子模型共享权值来提高NAS的效率,以避免每个子模型从无到有训练。
文中用单有向无圈图(DAG)表示NAS的搜索空间。递归单元的设计采用具有N个节点的DAG,它代表局部计算,边缘表示N个节点之间的信息流。
ENAS的控制器是RNN,其决定在DAG中的每个节点处执行哪些计算,并且哪些边缘被激活。控制器网络为具备100个隐藏单元的LSTM。
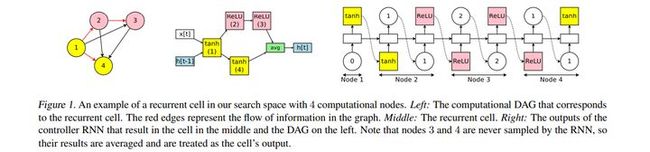
图1:带有四节点的搜索空间循环单元。左边是循环单元对应的计算DAG。红色边沿代表图形的信息流。中间是循环单元。右边:RNN 控制器的输出,为中间循环单元和左边DAG的输出结果。注意:节点3和4 未被RNN 采样,其结果平均后视为单元的输出。
图2:本图代表整个搜索空间,红色箭头定义了搜索空间的模型,该模型取决于控制器。在这里,节点1是模型的输入,节点3和6是模型的输出。
在ENAS中,需要学习两组参数:控制器LSTM的参数和子模型的共享参数。在训练的第一阶段,训练出子模型的共享参数;第二阶段,对控制器LSTM的参数进行训练。在ENAS训练中,这两个阶段交替进行。

图2:本图代表整个搜索空间,红色箭头定义了搜索空间的模型,该模型取决于控制器。在这里,节点1是模型的输入,节点3和6是模型的输出。
在ENAS中,需要学习两组参数:控制器LSTM的参数和子模型的共享参数。在训练的第一阶段,训练出子模型的共享参数;第二阶段,对控制器LSTM的参数进行训练。在ENAS训练中,这两个阶段交替进行。
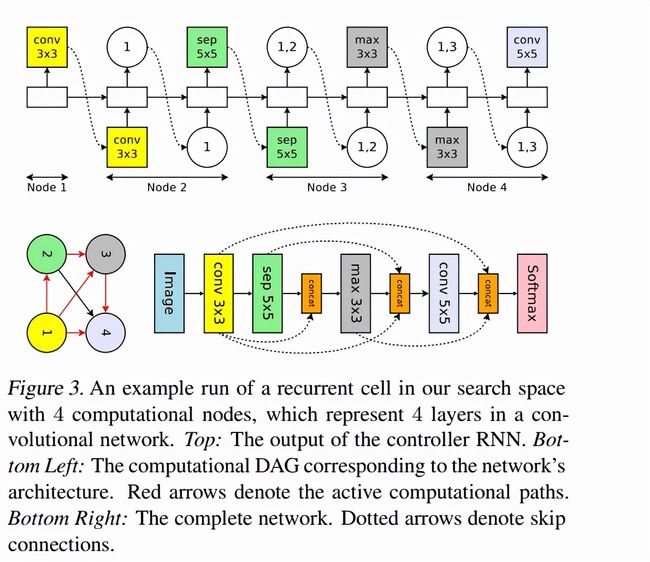
图3: 带有四个计算节点,运行在搜索空间的循环单元,代表了4层的卷积网络。顶部的图:控制器RNN 的输出。底部左图:对应网络架构的计算DAG,红色箭头代表活跃的计算路径。底部右图:完整的网络,虚线箭头为跳过的连接。
以下是ENAS在 CIFAR10数据集执行后的性能结果:

表2:ENAS 在CIFAR-10 测试中的分类误差率。在该表中,第一块为数据专家设计的DenseNet;第二块代表整个网络的实现方法;最后一块代表构建网络的模块单元的实现技术。
高效架构搜索的分层表示(ICLR 2022)
该算法在CIFAR-10上的最大误差率为3.6%,传输到ImageNet时的误差率为20.3%。作者介绍了描述神经网络结构的层次表示,证明了通过简单的随机搜索可以获得具有竞争力的图像分类架构,并给出了一种可伸缩的进化搜索变体。
用于高效架构搜索的分层表示
本文探讨了高效的神经体系架构搜索方法,并证明了一个简单而又强大的进化算法…
在查找了一系列多个神经网络之后,利用平铺结构来表示构成一个单源单汇计算图,该图将源端的输入转换为接收器的输出。图中的每个节点对应于一个特征映射,每个有向边缘都与某些操作相关联,例如:池化或卷积。此操作对输入节点中的特征映射进行转化并将其传递给输出节点。
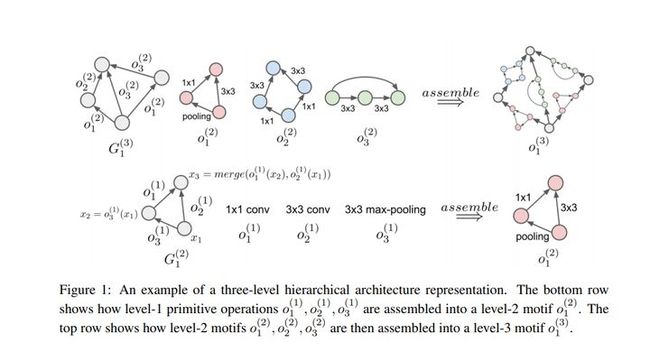
对于这种分层架构,计划是在不同层次上有多个主题。较低层次的母题在建造较高层次的母题时被当作积木用。
以下是CIFAR-10测试集上不同模型的误差率:

表2:CIFAR-10 测试集上的分类误差率,模型从顶至底分为以下三组:分层架构,采用增强学习架构和随机进化搜索架构。
深度学习-专家们正利用他们几十年的丰富经验,每周向您的收件箱推送最好的深度学习资源。
渐进神经架构搜索(ECCV2022)
本文提出一个神经架构搜索(NAS)的方法:采用序列模型的优化(SMBO)策略学习卷积神经网络(CNNS)。
渐进神经架构搜索
本文提出了一种新的更为高效的学习卷积神经网络(CNN)架构的方法...
在本文中,搜索算法的任务是识别出一个好的卷积单元,而不是一个完整的CNN。每个单元包含B个块,其中,块是带有两个输入的组合算子。每个输入都可以在被组合之前进行卷积变换。然后根据训练集的大小和最终CNN所需的运行时间来堆叠单元的结构。

图1: 左边:带有5个块的渐进神经结构搜索的最优单元结构。右边:采用与在CIFAR-10 和ImageNet 上构建CNN 单元相似的策略。注意:在这里,采用了单个单元,而不区分标准单元和还原单元。
如上面图所示,通过使用步幅-1或步幅-2堆叠基本单元的预定数量的副本,将单元转换为CNN。然后用最多N个重复次数对步幅-1单元之间的步幅-2单元数进行修正。在网络的顶部实现平均池化和SoftMax分类层。
下图显示了该模型在CIFAR测试集上的性能:

表3: CIFAR 测试集上不同CNN之间的性能比较。所有模型均在参数相等的情况下进行比较。
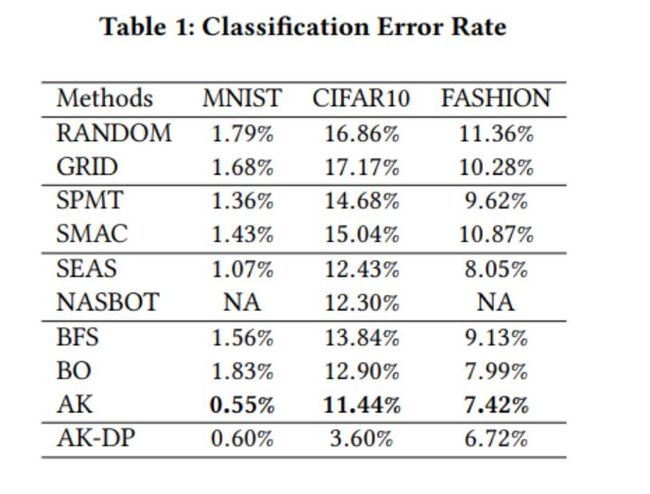
Auto-Keras:高效的神经架构搜索系统(2022)。
本文提出了一种支持贝叶斯优化的框架,以指导高效NAS网络的态射。在此基础上,作者构建了一个称为Auto-Keras的开源AutoML系统。
Auto-Keras:一种高效的神经架构搜索系统
提出了一种高效的神经架构搜索系统- (NAS),用于对深层神经网络进行自动整定,但现有的搜索算法……
本方法的主要组成部分是利用贝叶斯优化(BO)算法,通过神经架构渐变来探索搜索空间。由于NAS空间不是欧氏空间,作者通过设计神经网络核心函数来解决这一难题。核心函数是用于将一个神经结构渐变到另一个神经结构的编辑距离。
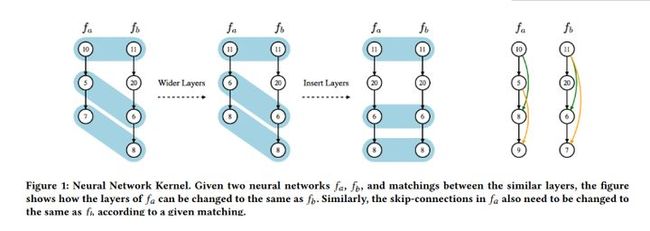
图1:神经网络核心,给定两个神经网络fa,fb,以及二者相似层之间的匹配,本图显示了fa的层如何变换到fb 层,同样,fa中的跳越连接在fb中需要有相同的变换
利用贝叶斯优化指导网络态射的第二个挑战是采样函数的优化。这些采样函数的优化方法不适用于树形结构搜索。可以通过对树结构空间上的采集功能进行优化,以解决该问题,需要选定采样函数的上置信界限(UCB)。
该架构的搜索器模块包含贝叶斯优化器和高斯过程,搜索算法在CPU上运行,模型训练器模块负责GPU上的计算。
该模块将神经网络与训练数据并行地训练,图形模块对神经网络的图进行计算,并由Searcher模块控制,进行网络态射运算。模型存储为包含训练好的模型的池,由于模型规模很大,所以它们必须存储在存储设备上。
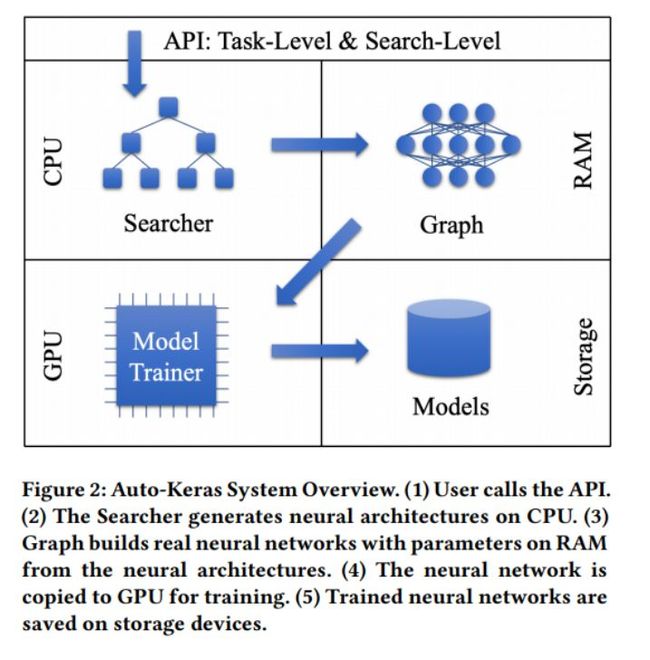
图2: Auto-Keras 系统概述:(1) 用户调用API。(2) 搜索器在CPU上生成神经网络架构(3)Graph在RAM 中构建实时网络的参数。(4)将神经网络复制到GPU 中进行训练。(5)训练好的神经网络保存到存储设备中去。
与其他模型相比,该模型在不同数据集上的性能如下:
基于贝叶斯优化和最优转换的神经架构搜索(2022)
本文提出了一种基于贝叶斯优化 (Bayesian Optimisation)的神经网络架构搜索BO框架,它通过计算神经网络架构空间中最佳转换程序的距离来实现。
基于贝叶斯优化和最优转换的神经架构搜索
贝叶斯优化(BO)是指用于全局优化函数$f$的一类方法,它只是…
作者提出了一种神经网络架构的伪距离,称之为神经网络架构的最优传输度量(OTMANN),该距离可以通过最优传输程序有效地计算出来。此外,作者还开发了一个用于优化神经网络架构函数的BO框架,称之为NASBOT(贝叶斯优化和最优传输的神经架构搜索)。
为了实现BO方案,定义了一个内核,以及优化这些架构的采样方法。采用进化算法对采样函数进行优化。
从初始网络池开始,再对网络采样进行评估,然后生成该池的一组Nmut 集合。第一种方法是随机地从被评估的网络集合中选取候选Nmut,那些具有较高采样函数的网络更有可能被选中,再对每个候选对象进行修正,以生成新的架构。
可以增加或减少每个层中的计算单元数量,添加或删除层,或者更改现有层的连接性。
最后一步是对Nmut采样进行评估,将其添加到初始池中,按照预定的次数重复迭代。在实验中,作者采用NASBOT来优化采样。通过这个实验,得出以下结论:NASBOT的性能优于用于优化采样的进化算法。

图1:CNN架构示例:在每一层:i:层指数,后随标签(如:conv3),之后是单元的数目(如:过滤器的数目),输入和输出层为粉红色,决策层(softmax)为绿色。
与其他模型相比,NASBOT的性能如下所示:

表3:第一行给出每个数据集的采样点数N和维数D,(N,D).后续行数为测试集每个方法的回归MSE和分类误差率(值越小越好)。最后一列为CIFAR10 测试,经过24K 次迭代后获得每个方法的最优模型,再进行120K 次迭代对它训练。当采用本训练流程对VGG-19架构进行训练之后,得到60K次迭代后误差率为0.1718;150K次迭代后的误差率为0.1018.
SNAS:随机神经架构搜索(ICLR 2022)
本文提出了随机神经架构搜索(SNAS)。SNAS是NAS的端到端解决方案,它在同一轮反向传播中训练神经操作参数和结构分布参数。在此过程中,它维护NAS管道的完整性和可微性。
SNAS:随机神经网络架构搜索
本文提出了随机神经架构搜索(SNAS),一种经济的端到端的神经架构搜索解决方案...
作者将NAS问题重新表述为单元内搜索空间联合分布参数的优化问题。利用搜索梯度,提取结构搜索中损失的梯度信息。这种搜索梯度优化与基于强化学习的NAS的目标是一致的,但它更高效地分配了结构决策的分值。
如下所示,搜索空间使用有向无圈图(DAG)表示,称为父图。在这个图中,节点xi代表信息表示。Edges (i, j)表示在节点之间选择的信息流和操作。
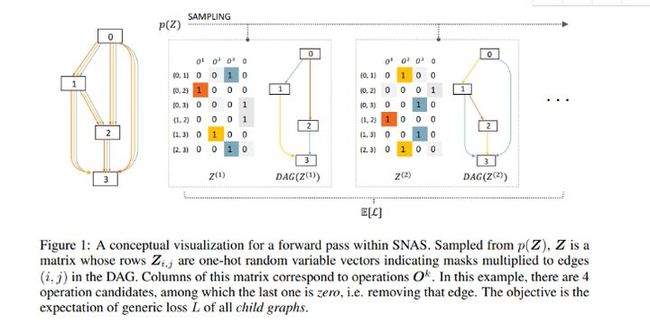
图1: SNAS 的前向可视化图。对p(Z)进行采样,Z 是一个矩阵,Zi,j是指示DAG 边际的随机变量。
以下是SNAS在 CIFAR-10测试集上图像分类器的分类误差率:
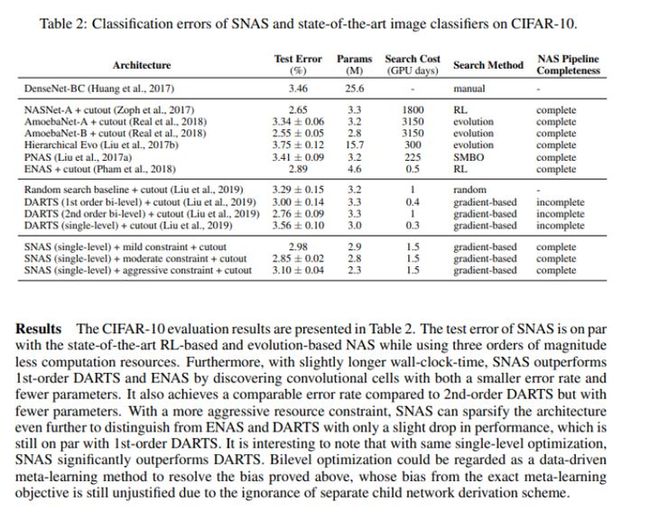
结果:CIFAR-10评估结果如表2示。SNAS的测试误差与基于RL的和基于进化的NAS的测试误差相当,同时使用的计算资源减少了三个数量级。此外,随着挂钟时间的增长,SNAS卷积单元的错误率较小,参数的数目也比较少,比一阶DARTS和ENAS性能更好。与二阶DARTS 相比,误差率相当。在资源限制性更高的情况下,SNAS可以进一步分散体系结构,以区别于ENAS,与DARTS 相比,性能只略有下降,这仍与一阶DARTS持平。有趣的是:在单层优化相同的情况下SNAS 性能明显优于DARTS。双层优化可被视为一种数据驱动的元学习方法来解决上述的偏差,由于对单独的子网络推导方案缺乏了解,其对精准元学习目标的偏差仍然存在。
DARTS:可微架构搜索(ICLR 2022)
本文以一种可微的方式来描述该任务,从而解决了架构搜索的可扩展性挑战。
DARTS:可微分的架构搜索
本文讨论如何解决来自以可微分为主架构搜索的可扩展性的挑战...
本文不再对一组离散集合架构进行搜索,而是将搜索空间放宽为连续的。因此,该架构可以通过梯度下降对其验证集性能进行优化。基于梯度优化的数据更为高效,从而使DARTS能够利用较少的计算资源来实现示范性性能。该模型的性能也优于ENAS。DARTS既适用于卷积网络,也适用于递归网络。
作者寻找一个计算单元作为最终架构的构建块。通过递归连接,可以将所学习的单元叠加成卷积网络或递归网络。单元是由N个节点的有序序列组成的有向无圈图。每个节点都是一个潜在的表示(例如,一个特征映射),每个有向边缘都与转换该节点的一些操作相关联。假定单元有两个输入节点和一个输出节点,卷积单元的输入节点定义为前两层的单元输出。在最近的单元格中,它们被定义为当前步长的输入和前一步长携带的状态。对所有中间节点应用缩减操作(例如级联)生成输出单元。

图1: DARTS 概述:(a)起初,边缘上的操作未知。(b)通过在每条边缘放置一个候选操作的混合来连续放松搜索空间。(c) 通过求解双层优化问题,对混合概率和网络权值进行联合优化。(d) 从学习的混合概率中归纳出最终的架构。
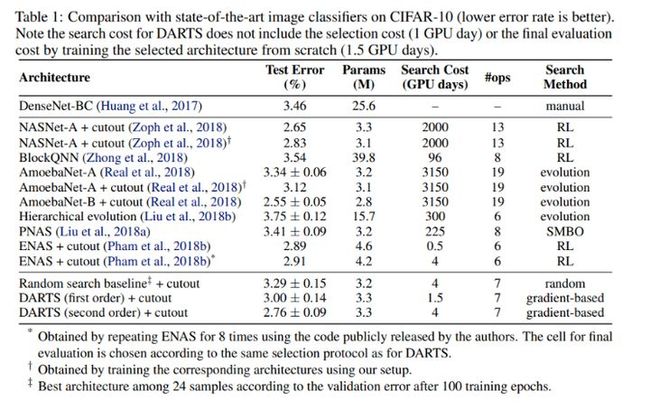
该模型在CIFAR-10测试集上与其它图像分类器的性能比较如下:
结论
本文对一些最常见的方法,以及一些非常近期的技术进行提速,以期在各种上下文中执行神经架构搜索。