pandas基础操作
pandas基础操作
- 1.Series
-
- 1.Series的创建
-
- 1.由列表或numpy数组创建
- 2.由字典创建
- 2.Series的常用属性以及常用方法
-
- 1.Series的常用属性
- 2.Series的常用方法
- 2.DataFrame
-
- 1.DataFrame的创建
-
- 1.由数组/list组成的字典创建
- 2.由Series组成的字典创建
- 3.ndarray二维数组创建
- 2.DataFrame的属性
- 3.DataFrame的索引和切片操作
-
- 1.DataFrame的索引操作
- 2.DataFrame的切片操作
- 3.DataFrame的算术运算
- 4.时间数据类型的转换
前面已经学习了numpy,numpy能够帮助我们处理 数值型数据,而 pandas就能很好的帮助我们处理除了数值型的其他数据。
pandas中有两个常用的类:
- Sersies
- DataFrame
1.Series
Pandas Series 类似表格中的一个列(column),类似一维数组,由下面两个部分组成:
- values:一组数据(数据类型要求统一)
- index:相关数据的索引标签
1.Series的创建
1.由列表或numpy数组创建
import pandas as pd
import numpy as np
data=[1,2,3,4]
#使用列表创建
s1=Series(data)
s2=Series(data=[1,2,3,'four'])
#自定义索引(显示索引可以增强series的可读性)
s3=Series(data=[1,2,3,'four'],index=['a','b','c','d'])
#使用np数组创建
s4=Series(np.random.randint(0,100,size=(3,)))

2.由字典创建
from pandas import Series
#使用字典创建
dic={
'语文':90,
'数学':100,
'英语':88
}
s=Series(data=dic)
print(s)
#可直接通过索引读取内容
print(s.语文)
#Series的切片操作和numpy数组的一致
print(s[0:2])

2.Series的常用属性以及常用方法
1.Series的常用属性
- shape:返回series的形状
- size:返回元素个数
- index :返回索引
- values :返回值
- dtype:返回元素类型
2.Series的常用方法
- head(),tail() :默认显示前5个或后5个
- unique():去重
- isnull(),notnull():判断每个元素是否为空
- add(),sub(),mul(),div():加减乘除运算操作
- Series的算术运算:
索引一致的元素进行算术运算,否则补空
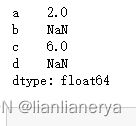
s1=Series(data=[1,2,3],index=['a','b','c'])
s2=Series(data=[1,2,3],index=['a','d','c'])
s=s1+s2
2.DataFrame
DataFrame是一个表格型的数据结构。可以理解为将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:vlalues
1.DataFrame的创建
Dataframe 有三种常用的创建方式:由数组/list组成的字典;由Series组成的字典;由二维数组直接创建
#DataFrame的参数
DataFrame(
data=None,
index: Union[Collection, NoneType] = None,
columns: Union[Collection, NoneType] = None,
dtype: Union[str, numpy.dtype, ForwardRef('ExtensionDtype'), NoneType] = None,
copy: bool = False,
)
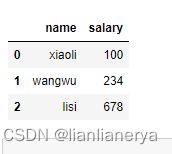
1.由数组/list组成的字典创建
数组/List的维度要一致
dic={
'name':['xiaoli','wangwu','lisi'],
'salary':[100,234,678]
}
df3=DataFrame(data=dic)
2.由Series组成的字典创建
维度不一致可用Nan补齐
#使用Series数组创建
s1=pd.Series(data=[1,2,3,4],index=list('abcd'))
s2=pd.Series(data=[1,2,3],index=list('abc'))
dic={
's1':s1,
's2':s2
}
df=pd.DataFrame(dic)

3.ndarray二维数组创建
from pandas import DataFrame
#使用二维数组创建
df1=DataFrame(data=[[1,2,3],[4,5,6]],index=['first','second'],columns=['a','b','c'])
df2=DataFrame(data=np.random.randint(0,100,size=(3,4)))

2.DataFrame的属性
- shape:返回series的形状
- size:返回元素个数
- index :返回行索引
- columns:返回列索引
- values :返回值
- dtype:返回元素类型(只能单独看一行或一列)
3.DataFrame的索引和切片操作
loc:通过显式索引取行
iloc:通过隐式索引取行
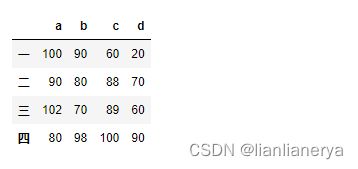
import numpy as np
from pandas import DataFrame
dic={
'a':[100,90,102,80],
'b':[90,80,70,98],
'c':[60,88,89,100],
'd':[20,70,60,90]
}
df=DataFrame(data=dic,index=['一','二','三','四'])
1.DataFrame的索引操作
注意:取单行和取单列的区别,有显式索引的时候,取单列必须要用显式索引
- 取单列:df[col] (如果df有显式的索引,通过索引机制取列的时候只能用显式索引)
- 取多列: df[[‘a’,‘c’]]
- 取单行:df.loc[index];df.iloc[index]
- 取多行: df.iloc[[index1,index3]]
- 取元素:df.loc[index,col];df.iloc[index,col];df.at[index,col]
- 取多个元素:df.loc[[index1,index3],[col2,col3]];df.iloc[[index1,index3],[col2,col3]]
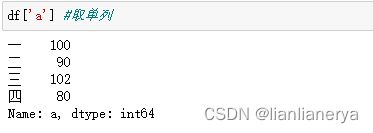
df['a'] #取单列
df[['a','c']]#取多列
#显式取
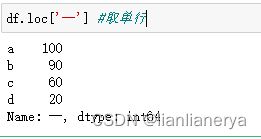
df.loc['一'] #取单行
df.loc[['一','四'],['a','c']] #显式取多行多列
df.loc['一','a'] #显式取元素
#隐式取
df.iloc[0] #取单行
df.iloc[[0,2]] #取多行
df.iloc[[0,2],[0,1]]#显式取多行多列






2.DataFrame的切片操作
- 切行:df[index1:index3]
- 切列:df.iloc[:,col1:col3];df.loc[:,col1:col3]
- 切行切列:df.iloc[index1:index3,col1:col3] ;df.iloc[index1:index3,col1:col3]
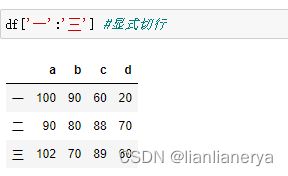
df['一':'三'] #显式切行
df.loc[:,'a':'b']#显式切列
df.loc['一':'三','a':'b'] #显式切行列
df[0:3] #隐式切行
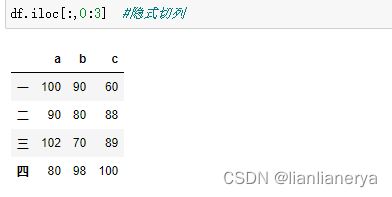
df.iloc[:,0:3] #隐式切列
df.iloc[0:2,0:3] #隐式切行列



3.DataFrame的算术运算
同Series的算术运算(相同位置的数进行运算)
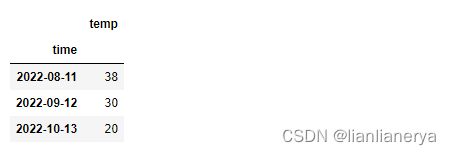
4.时间数据类型的转换
- 时间数据类型的转换:pd.to_datetime(col)
- 将某一列设置为行索引:df.set_index()
from pandas import DataFrame
dic={
'time':['2022-08-11','2022-09-12','2022-10-13'], #time为字符串类型
'temp':[38,30,20]
}
df=DataFrame(data=dic)
#将time的字符串类型转化成时间序列类型
import pandas as pd
df['time']=pd.to_datetime(df['time']) #time为时间序列类型
#将time列作为原始数据的行索引
df.set_index('time',inplace=True)