极客星球 | 业务监控及告警系统体系化建设之路

监控系统体系化建设背景及现状
监控系统对于业务系统的重要性不言而喻,但该如何选择监控系统,以及如何实现系统监控和告警的功能,一直是监控系统中的两大难题。本文就来解密一下数据智能企业在监控系统上的处理和建议,和大家一起探讨。
常见业务监控系统通常先实现操作系统层面的监控,目前这部分技术已相对成熟,继而再扩展出其它监控,如 :Zabbix、小米Open-Falcon。当然也有同时支持两者的监控系统,如 Prometheus。若对业务监控要求较高,建议开发者们在选型中优先考虑 Prometheus。
下图为截至2022年5月,谷歌提供监控系统使用情况分布:

开源监控报警系统——Prometheus
Prometheus(普罗米修斯)是由SoundCloud开发的开源监控报警系统和时间序列数据库(TSDB),它是一个监控采集与数据存储框架(监控服务器端),支持多种exporter采集指标数据,并支持PushGateway进行数据上报,性能足够支撑上万台规模的集群,相较于其它监控系统使用的 push 数据的方式,Prometheus 则使用的是 pull 的方式。

1、基本原理:
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态。这样做的好处是,任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程,这样做非常适合虚拟化环境,如:VM、Docker 。Prometheus是为数不多同时适合Docker、Mesos、Kubernetes环境的监控系统之一。
2、Exporter:
输出被监控组件信息的HTTP接口被称为exporter 。目前互联网公司常用的组件大部分都有可以直接使用的exporter,如:Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等)。具体采集的数据类型依赖于Exporter(监控客户端),例如采集MySQL的数据需要使用mysql_exporter。当Prometheus调用mysql_expoter采集到MySQL的监控指标之后,把采集数据存放到Prometheus所在服务器的磁盘数据文件中。它的各个组件基本都是用Golang编写的,对编译和部署十分友好,并且没有特殊依赖,基本都是独立工作。
Exporter种类如下:
- 官方Exporter地址:https://github.com/prometheus;
- node_exporter:Linux类操作系统相关数据的采集程序;
- jmx_exporter:Java进程指标采集程序;
- mysqld_exporter:MySQLserver数据采集程序;
- redis_exporter:Redis数据采集程序
3、Prometheus架构:
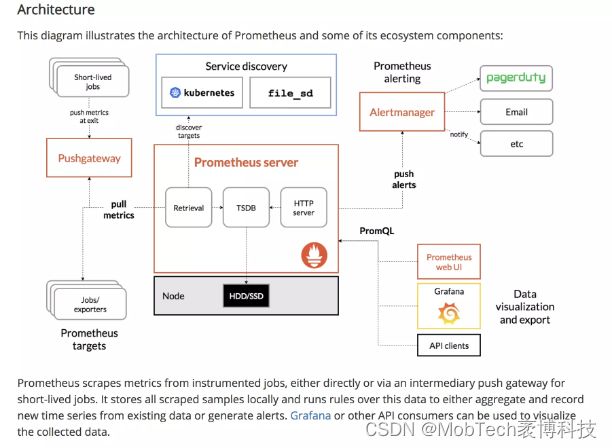
1)Prometheus Server
主要负责数据采集和存储,提供 PromQL 查询语言的支持。Server 通过配置文件、文本文件、ZooKeeper、Consul、DNS SRV Lookup 等方式指定抓取目标。根据这些目标,Server 定时去抓取 metrics 数据,每个抓取目标需要暴露一个 http 服务的接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为Pull。Pull方式体现了Prometheus独特的设计哲学,这一点与大多数采用Push方式的监控系统不同。
2)PushGateway
Prometheus支持临时性 Job 主动推送指标的中间网关。某些现有系统是通过Push方式实现的,为了接入这个系统,Prometheus提供对PushGateway的支持。这些系统主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
3)AlertManager
AlertManager是独立于Prometheus的一个组件,可以支持 Prometheus 的查询语句,并在触发了预先设置在Prometheus中的高级规则后,Prometheus便会推送告警信息到AlertManager。
4)Exporter
Exporter是 Prometheus 的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为 Prometheus 支持的格式。与传统的数据采集组件不同,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。Prometheus 提供多种类型的 Exporter 用于采集各种不同服务的运行状态。目前支持的有数据库、硬件、消息中间件、存储系统、HTTP 服务器、JMX 等。
5)HTTP API
这是一种查询方式,可以自定义所需要的输出。
6)Prometheus支持两种存储方式
第一种是本地存储,通过Prometheus自带的时序数据库将数据保存到本地磁盘,为了性能考虑,建议使用SSD。但本地存储的容量毕竟有限,建议不要保存超过一个月的数据。
另一种是远程存储,适用于存储大量监控数据。通过中间层适配器的转化,目前Prometheus支持OpenTSDB、InfluxDB、Elasticsearch等后端存储。通过适配器实现Prometheus存储的remote write和remote read接口,便可以接入Prometheus作为远端存储使用。
7)Prometheus核心价值
系统监控:主要是跟进操作系统的基本监控项目,如CPU、内存硬盘、IO、TCP连接、进出口流量;
程序监控:一般需要和开发人员配合,在程序中主动上报各种获取到的数据或者特定的日志格式;
业务监控:可以包含用户访问QPS、DAU日活、访问状态(Http code)、业务接口(登入、注册、聊天、上传、留言、短信、搜索)

开源分析监视平台——Grafana
1、基本简介
Grafana 是一套开源的分析监视平台,支持 Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch 等数据源,其 UI 非常漂亮且高度定制化,选择 Prometheus + Grafana 的方案,可以满足大部分中小团队的监控需求。

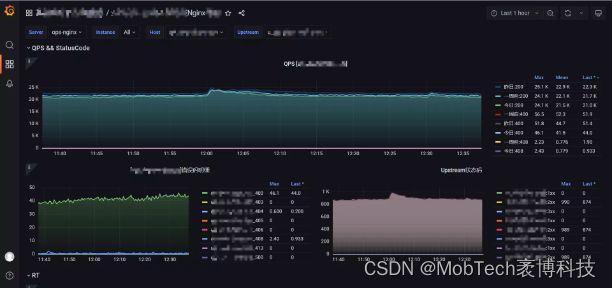
添加完数据源后,可根据实际需求,添加自定义的仪表盘和视图组件。

2、五步上手集成springboot项目
第一步 新建springboot项目,依赖如下:



第二步 启动服务,浏览器查看服务
http://ip:8081/actuator/prometheus


以上数据为Prometheus收集的数据格式,包含指标及数据。
第三步 将上面的应用接口作为job接入Prometheus,修改Prometheus的/prometheus.yml

第四步 重启prometheus
systemctl restart prometheus,此时prometheus的targets中便会增加一个

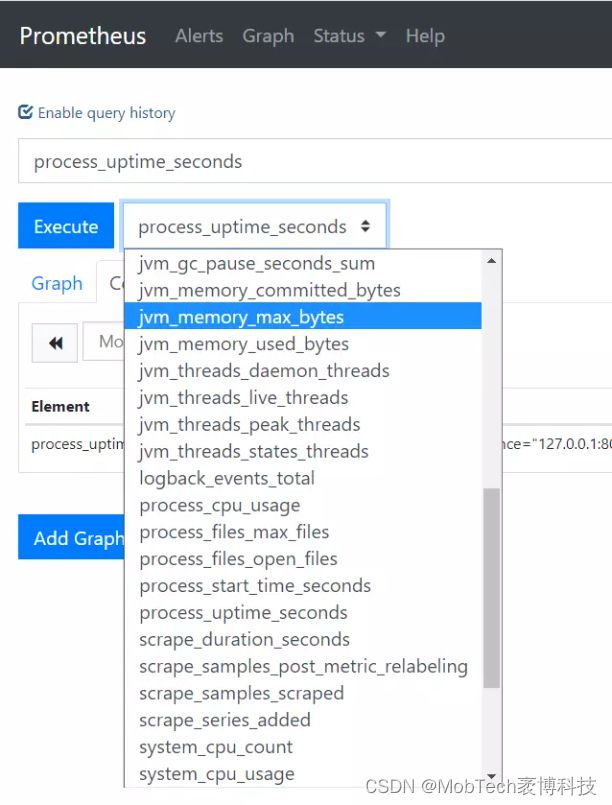
以上便是我们提供给Prometheus默认收集的指标,我们可以基于这些指标通过PromQL查询,查询结果在Grafana中做展示。
第五步 为方便展示,我们在Grafana中添加面板,保存即可展示到我们的仪表盘中。
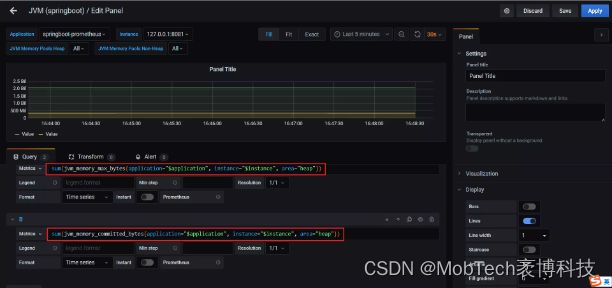
同时,Grafana中添加JVM模板。Grafana官网提供了很多模板,我们只需输入模板编号,即可完成仪表盘的配置。
更多模板请见:https://grafana.com/grafana/dashboards/

JVM相关的常用指标监控,到此便配置完成,以上配置也可以根据实际情况,调整每个模块的展示信息。

3、配置告警通知
1)告警通知模块
到这一阶段,我们已经能够通过Grafana展示收集并查看数据。想一想,系统还缺失什么功能?监控最重要的目的是,判断监控系统是否正常,并在系统不正常时,告知相关人员及时排查和解除问题,即告警通知。因此,还缺少一个有关告警通知的模块。prometheus的告警机制由以下两部分组成:
告警规则
prometheus会根据告警规则rule_files,将告警发送给Alertmanager。
管理告警和通知
该模块是Alertmanager,它负责管理告警、去除重复数据、告警通知。通知方式有多种选择,如Email、HipChat、Slack、WebHook等等。
实际操作为:新创建一个规则文件alert_rules.yml

以上代码的大意是创建了1条alert规则——InstanceDown。
InstanceDown就是实例宕机(up == 0)触发告警,5分钟后告警(for:5m)。
- alert:告警规则的名称。 expr:基于PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
- summary 描述告警的概要信息,description 用于描述告警的详细信息。
- Alertmanager 的UI 也会根据以上两个标签值,显示告警信息。
向promethues.yml添加告警规则:

重启promethues即可在Alerts中看到我们定义的告警规则:
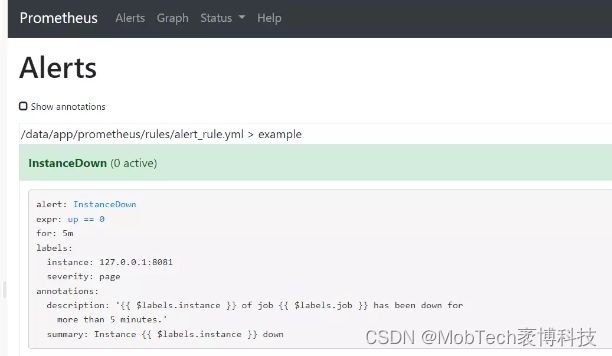
状态说明:Prometheus Alert 告警状态有三种状态,包括Inactive、Pending、Firing;
- Inactive:非活动状态,表示正在监控,但是还未有任何警报触发;
- Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以要等待验证,一旦所有的验证都通过,则转到Firing
状态; - Firing:将警报发送到AlertManager,它将按照配置将警报发送给所有接收者。一旦警报解除,则转到Inactive状态,如此循环
模拟服务宕机:kill进程

此时满足条件 up == 0,State变成为PENDING

当时间超过评估等待时间5m后 (for:5m),State变成FIRING,此时会产生告警。并发送给Alertmanager处理。

2)告警通知模块
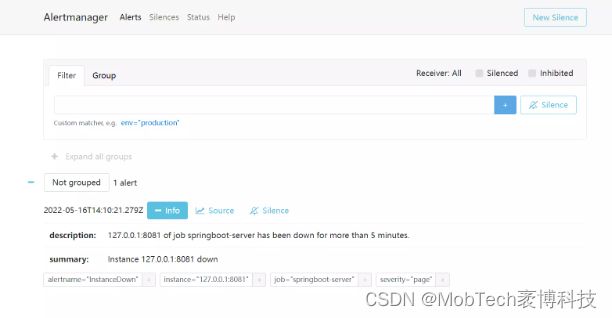
在上面我们可以看到alerts页面的告警信息,但是怎么把告警信息通知到研发和业务相关人员呢?这一操作需要由Alertmanager完成。
我们先配置alertmanager文件 alertmanager.yml


alertmanager收到告警通知后,会根据当前配置的方式,如邮件等,发送告警信息:
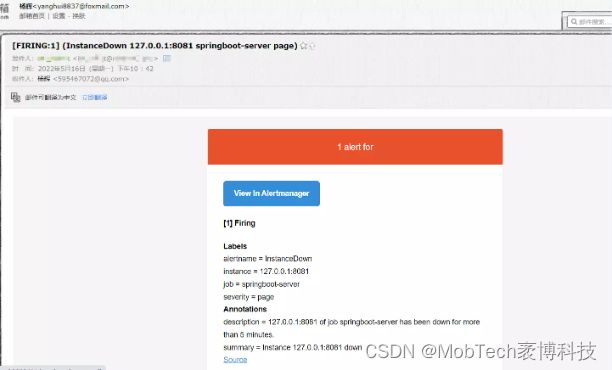
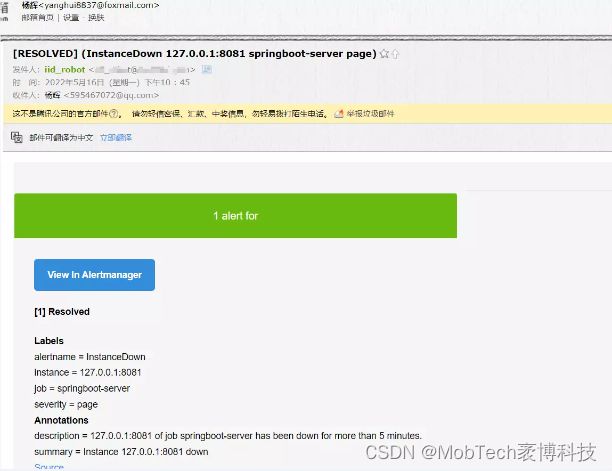
当我们服务重启,问题被修复时,也会收到一封邮件告知。若不想收到该邮件,可在alertmanager.yml配置:receivers.email_configs.send_resolved:false即可
Prometheus及Grafana对比分析
1、Prometheus优缺点分析:
监控数据基于时间序列存储数据库,便于实现数据聚合。各个组件有成熟的高可用方案,没有单点故障、不依赖分布式存储、单个服务器节点可直接工作。其使用的是PromSQL,这是一种灵活的查询语言,可利用多维数据完成复杂的查询。同时支持多种多样的图表和界面展示,一般和Grafana配合使用。
Prometheus 是基于指标(Metric)的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。它更多得展示趋势性监控,而非精准数据;Prometheus 认为只有最近的监控数据才有查询的需要,其本地存储的设计初衷只是保存短期(例如一个月)的数据,因而不支持针对大量历史数据的存储。若需要存储长期的历史数据,建议基于远端存储机制将数据保存于 InfluxDB 或 OpenTSDB等系统中。
另外,alertmanager的匹配规则配置很复杂,是在prometheus的时序数据库的基础上做二次定制。这也意味着如果中途更换数据库,那么之前的配置需要重新调整。这一点对于后期配置开发非常不利,尤其其键值还依赖exporter的metrics信息,从编码的角度而言,这里缺少接口的封装,对于程序的可维护性而言是一大挑战。
2、Grafana优缺点分析:
Grafana的可用性很高,图表插件非常多,完全可以根据自己的需求进行选用,并且社区上传了大量Dashboard可供使用,因此其优势与其他组件类似,都是开源、开箱即用等。
但其社区贡献也带来了同exporter一样的问题,首先是Dashboard和exporter的匹配度普遍不高,下载之后需要花费大量时间进行二次调整。除此之外,接入的api也不友好,例如接入prometheus,其接入api即为prometheus的时序数据库的查询语句,由于操作者对其不熟悉,也需要大量时间进行理解。最后就是缺少列表信息的内容,社区的Dashboard主要由各种图表构成,可以满足整体分析的需求,但是在问题定位时就显得力不从心了。
综合来看,Prometheus和Grafana组合基本上是目前主流监控系统的标配,Prometheus做存储后端,而Grafana负责分析及可视化界面,是一个省时省力,效率最高的方案,几乎能满足大部分企业对于系统和业务的监控需求。当然每个人所在的行业不同、公司不同、业务不同、岗位不同、对监控的理解也不同,也有比较好的开源的监控框架如Sensu等,再加上influxdb、grafana可以用来定制符合自己企业的监控平台。最重要的是,我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。