时间序列分析之GARCH模型介绍与应用
时间序列分析之GARCH模型介绍与应用
-
- 前言
- 一:ARCH模型的相关性质
- 二:ARCH实验过程
- 三:GARCH模型的轮廓介绍
- 四:GARCH实验过程
- 五:总结
前言
在ARIMA模型中,我们一般假设干扰项的方差为常数,然而在很多情况下,时序波动的干扰项方差并不为常数。因此我们有必要刻画方差(波动率)这一特征来研究时序模型,本篇的(G)ARCH模型就是刻画随时间变化的方差模型。
岁月如云,匪我思存,写作不易,望路
过的朋友们点赞收藏加关注哈,在此表示感谢!
一:ARCH模型的相关性质
- 底层由来
我们还是从 A R ( p ) AR(p) AR(p)模型入手:
x t = ϕ 0 + ϕ 1 x t − 1 + ϕ 2 x t − 2 + . . . + ϕ p x t − p + ε t x_t=\phi_0+\phi_1x_{t-1}+\phi_2x_{t-2}+...+\phi_px_{t-p}+\varepsilon_t xt=ϕ0+ϕ1xt−1+ϕ2xt−2+...+ϕpxt−p+εt,
我们定义 A R C H ( q ) ARCH(q) ARCH(q)模型为:残差
ε t = σ t μ t , σ t 2 = a 0 + a 1 ε t − 1 2 + . . . + a q ε t − q 2 \varepsilon_t=\sigma_t\mu_t,\sigma_t^2=a_0+a_1\varepsilon_{t-1}^2+...+a_q\varepsilon_{t-q}^2 εt=σtμt,σt2=a0+a1εt−12+...+aqεt−q2 这 { μ t } \{\mu_t\} {μt}
均值为0,方差为1的独立同分布随机变量序列, a i ≥ 0 a_i\geq0 ai≥0。假设 E ( ε t 2 ) < ∞ E(\varepsilon_t^2)<\infty E(εt2)<∞有界,则在信息流 F t − 1 F^{t-1} Ft−1 的作用下,有 ε t \varepsilon_t εt 的条件方差:
E ( ε t ∣ F t − 1 ) = σ t E ( μ t ∣ F t − 1 ) = σ t E ( μ t ) = 0 E(\varepsilon_t|F^{t-1})=\sigma_tE(\mu_t|F^{t-1})=\sigma_tE(\mu_t)=0 E(εt∣Ft−1)=σtE(μt∣Ft−1)=σtE(μt)=0 ,
由条件方差公式:
D ( ε t ∣ F t − 1 ) = E ( ε t 2 ∣ F t − 1 ) − ( E ( ε t ∣ F t − 1 ) ) 2 D(\varepsilon_t|F^{t-1})=E(\varepsilon_t^2|F^{t-1})-\left( E(\varepsilon_t|F^{t-1}) \right)^2 D(εt∣Ft−1)=E(εt2∣Ft−1)−(E(εt∣Ft−1))2
得其条件方差为:
D ( ε t ∣ F t − 1 ) = E ( ε t 2 ∣ F t − 1 ) = σ t 2 E ( μ t 2 ∣ F t − 1 ) = σ t 2 E ( μ t 2 ) = σ t 2 = a 0 + a 1 ε t − 1 2 + . . . + a q ε t − q 2 ( 1 ) D(\varepsilon_t|F^{t-1})=E(\varepsilon_t^2|F^{t-1})=\sigma_t^2E(\mu_t^2|F^{t-1})=\sigma_t^2E(\mu_t^2)=\sigma_t^2=a_0+a_1\varepsilon_{t-1}^2+...+a_q\varepsilon_{t-q}^2(1) D(εt∣Ft−1)=E(εt2∣Ft−1)=σt2E(μt2∣Ft−1)=σt2E(μt2)=σt2=a0+a1εt−12+...+aqεt−q2(1)
从公式(1)容易看出,满足 A R C H ( q ) ARCH(q) ARCH(q)模型的序列的波动与其过去 q q q 期的波动有关,而且会随着时间的改变而改变。
- 期望、方差与协方差
对于白噪声 { ε t } \{\varepsilon_t\} {εt} 序列,在假定期条件与方差不变的情况下,根据条件期望的期望就是它本身的性质,我们有
E ( ε t ) = E [ E ( ε t ∣ F t − 1 ) ] = 0 E(\varepsilon_t)=E\left[ E(\varepsilon_t|F^{t-1}) \right]=0 E(εt)=E[E(εt∣Ft−1)]=0 ,
V a r ( ε t ) = E [ E ( ε t 2 ∣ F t − 1 ) ] = E ( σ t 2 ) = Var(\varepsilon_t)=E\left[ E(\varepsilon_t^2|F^{t-1}) \right]=E(\sigma_t^2)= Var(εt)=E[E(εt2∣Ft−1)]=E(σt2)=
a 0 + a 1 E ( ε t − 1 2 ) + . . . + a q E ( ε t − q 2 ) = a 0 1 − a 1 − . . . − a q a_0+a_1E(\varepsilon_{t-1}^2)+...+a_qE(\varepsilon_{t-q}^2)= \frac{a_0}{1-a_1-...-a_q} a0+a1E(εt−12)+...+aqE(εt−q2)=1−a1−...−aqa0,
C o v ( ε t , ε t − j ) = E ( ( ε t − E ( ε t ) ) ( ε t − j − E ( ε t − j ) ) ) Cov(\varepsilon_t,\varepsilon_{t-j})=E\left( (\varepsilon_t-E(\varepsilon_t))(\varepsilon_{t-j}-E(\varepsilon_{t-j})) \right) Cov(εt,εt−j)=E((εt−E(εt))(εt−j−E(εt−j)))
= E ( ε t ε t − j ) = 0 =E(\varepsilon_t\varepsilon_{t-j})=0 =E(εtεt−j)=0。
- 参数估计过程
- 估计一个 A R C H ARCH ARCH模型,首先要确定好 A R ( p ) AR(p) AR(p)模型的阶数,可以根据定阶模型。但对于波动率阶数 q q q的确定,我们要先检验序列 { ε t } \{\varepsilon_t\} {εt} 存在显著的 A R C H ARCH ARCH效应,再根据偏自相关函数 ( P a c f ) (Pacf) (Pacf)来确定 q q q ,
- 定好阶后,为了估计模型参数,当 { μ t } \{\mu_t\} {μt} 服从正态分布时,我们可以用最小二乘最大似然估计对模型参数进行估计。
- 建模过程(由于此模型前期工作跟ARMA模型的建立很相似,所以有些步骤将简述)
- 首先还是对序列进行平稳性和白噪声检验,
- 检验ARCH效应。
a:我们对建立的AR§模型进行残差平方分析,对残差平方进行白噪声检验,如果过了白噪声检验,那就进行ARCH(q)偏自相关函数定阶,否则不存在ARCH效应;
b:还有一种是基于LM公式检验, L M LM LM公式为:
ε t 2 = a 0 + ∑ i = 1 q a i ε t − i 2 \varepsilon_t^2=a_0+\sum_{i=1}^{q}{a_i\varepsilon_{t-i}^2} εt2=a0+∑i=1qaiεt−i2,检验的原假设为:序列 { ε t 2 } \{\varepsilon_t^2\} {εt2} 无 A R C H ARCH ARCH效应,即 a i = 0 , i = 1 , 2 , . . , q a_i=0,i=1,2,..,q ai=0,i=1,2,..,q,备择假设为:序列 { ε t 2 } \{\varepsilon_t^2\} {εt2} 存在 A R C H ARCH ARCH效应,即至少存在一个 a i a_i ai 显著不为0, - 建立好 A R C H ( q ) ARCH(q) ARCH(q)模型后,我们将预测数据并进行模型检验。
二:ARCH实验过程
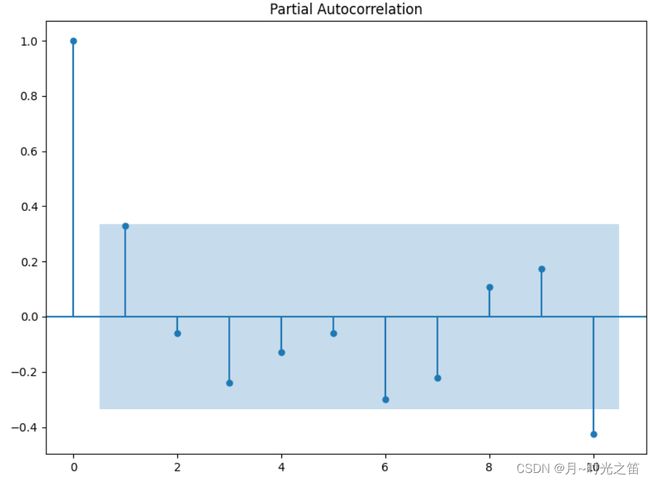
建模过程中,将沿用上一篇文章的数据,根据上一篇文章数据内容,我们得出的 P a c f Pacf Pacf如下,选择 A R ( 10 ) AR(10) AR(10)模型。
根据残差公式,我们做出残差图和残差平方图如下。
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
from statsmodels.tsa.stattools import adfuller as ADF
from statsmodels.tsa.arima_model import ARIMA,ARMA
import statsmodels.api as sm
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import arch
yv = np.array([2800,2811,2832,2850,2880,2910,2960,3023,3039,3056,3138,3150,3198,3100,3029,2950,2989,3012,3050,3142,3252,3342,3365,3385,3340,3410,3443,3428,3554,3615,3646,3614,3574,3635,3738,3764,3788,3820,3840,3875,3900,3942,4000,4021,4055])
yv_serie = pd.Series(yv[:-10])
def testwhitenoise(data):
m = 10# 检验10个自相关系数
acf,q,p = sm.tsa.acf(data,nlags=m,qstat=True)
out = np.c_[range(1,m+1),acf[1:],q,p]
output = pd.DataFrame(out,columns=['lag','自相关系数','统计量Q值','p_values'])
output = output.set_index('lag')# 设置第一列索引名称,可省略重复索引列1
print(output)
def teststeady(data,count=0):
res_ADF = ADF(data)
print('ADF检验结果为:', res_ADF)
Pv = res_ADF[1]
if Pv > 0.05:
print('\033[1;31mP值:%s,原始序列不平稳,要进行差分!\033[0m' % round(Pv,5))
count = count + 1
print('\033[1;32m进行了%s阶差分后的结果如下\033[0m' % count)
data = data.diff(1).dropna()
teststeady(data,count)
else:
print('\033[1;34mP值:%s,原始序列平稳,继续建模\033[0m'% round(Pv,5))
return data
tsres = teststeady(yv_serie)
def confirm_p(data):
fig = plt.figure(figsize=(10,6))
train = teststeady(data)
ax1 = fig.add_subplot(111)
fig = plot_pacf(train, lags=10, ax=ax1)
plt.show() ###可视化定阶
def testARCH(data):
order = (10,0)
tempmodel = ARMA(data, order).fit(disp=-1)
at = data - tempmodel.fittedvalues
at2 = np.power(at,2)##残差平方和
fig = plt.figure(figsize=(8,6))
plt.subplot(211)
plt.plot(at,label='at')
plt.legend()
plt.subplot(212)
plt.plot(at2,label='at^2')
plt.legend()
plt.show()
testwhitenoise(at2)
confirm_p(at2)
testARCH(tsres)

再对残差平方图进行白噪声检验如下,

从图3中,我们发现残差平方图是白噪声序列,不满足 A R C H ARCH ARCH效应,但是为了展示 A R C H ARCH ARCH模型的建模过程,我们还是继续建模,最后跟 A R M A ARMA ARMA模型做对比,接下来对 A R C H ( q ) ARCH(q) ARCH(q)进行定阶。

从图4的 P a c f Pacf Pacf图我们发现,确实也没有合适的阶数,如果强行建立 A R C H ARCH ARCH模型,我们设阶数 q = 3 q=3 q=3 试一试,那么实际模型为 A R ( 10 ) + A R C H ( 3 ) AR(10)+ARCH(3) AR(10)+ARCH(3)!
def make_ARCHmodel(data,pst,lag):
tempmodel = arch.arch_model(data,mean='AR',lags=lag,vol='ARCH',p=3,dist='gaussian').fit(update_freq=0,disp='off')
##预测值的均值;如果AR模型是10阶,起步位置必须是第9(从0起算)位置以上开始;horizon:从第start+1数据开始,预测未来horizon期数据
pre = tempmodel.forecast(horizon=pst,start=lag-1,method='simulation').mean.iloc[lag-1]
print(pre)
init_value = yv[lag]
fig = plt.figure(figsize=(8, 6))
predicthorizon = pre.cumsum() ##差分还原
predicthorizon = init_value + predicthorizon
prelsall = yv[:lag + 1] + list(predicthorizon)##差分少一个数据并补充
# 作图
plt.plot(prelsall, label='样本预测值')
plt.plot(yv, label='原始值')
plt.legend()
plt.show()
l = 10
presteps = len(yv) - l - 1
preres = make_ARCHmodel(tsres,presteps,l)
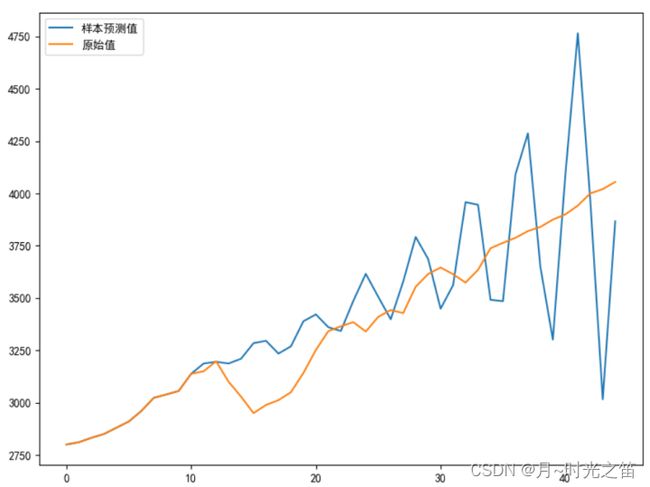
从上图5我们发现,当数据确实不符合 A R C H ARCH ARCH效应时,如果强行建模,那确实适得其反,跟 A R M A ARMA ARMA模型的效果相比差的很远,从图也能发现,预测结果相当不可靠,所以我们理解好建模思路和用对模型都非常重要,不能因为模型复杂而不适合来进行强行建模。
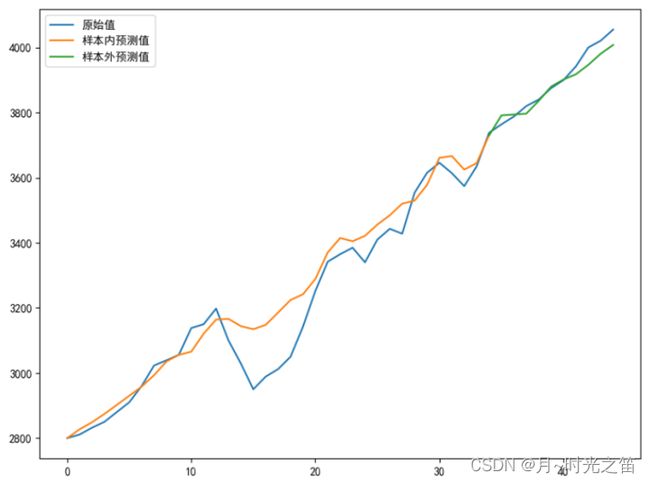
下图是上一篇文章均值模型ARIMA的建模结果,为了方便比较,这里列出!
点击进入上一篇文章内容!
三:GARCH模型的轮廓介绍
- 原理简介
我们知道 A R C H ARCH ARCH模型的波动率 σ t 2 \sigma_t^2 σt2 仅与白噪声序列 ε t 2 \varepsilon_t^2 εt2 的滞后项有关, G A R C H GARCH GARCH则认为时间序列每个时间点变量的波动率是最近 p p p 个时间点残差平方的线性组合,再与最近 q q q 个时间点变量波动的线性组合的加起来得到的,即:
ε t = σ t μ t , σ t 2 = a 0 + ∑ i = 1 p a i ε t − i 2 + ∑ j = 1 q b j σ t − j 2 ( ∗ ) \varepsilon_t=\sigma_t\mu_t,\sigma_t^2=a_0+\sum_{i=1}^{p}{a_i\varepsilon_{t-i}^2}+\sum_{j=1}^{q}{b_j\sigma_{t-j}^2}(*) εt=σtμt,σt2=a0+∑i=1paiεt−i2+∑j=1qbjσt−j2(∗)
其中 { μ t } \{\mu_t\} {μt} 是均值为0,方差为1的独立同分布随机变量序列。这里我们对每个变量进行些说明,
a 0 > 0 , a i , b j ≥ 0 , ∑ i = 1 p a i + ∑ j = 1 q b j < 1 a_0>0,a_i,b_j\geq0,\sum_{i=1}^{p}{a_i}+\sum_{j=1}^{q}{b_j}<1 a0>0,ai,bj≥0,∑i=1pai+∑j=1qbj<1,
且假定 a i , b j a_i,b_j ai,bj 满足一定条件使得 ε t \varepsilon_t εt 的条件方差随时间变化是有限的。(特别说明这里的 p 跟AR模型里面的 p不是一个值, ε t \varepsilon_t εt 为残差,即真实值与预测值之差)
- 模型说明
G A R C H GARCH GARCH模型跟 A R C H ARCH ARCH模型非常类似,都是对于波动率进行新的建模分析,所以在模型搭建前,也是有必要进行数据平稳性、白噪声和 A R C H ARCH ARCH效应检验的。但在 ( ∗ ) (*) (∗)中,我们发现此波动率会涉及 p , q p,q p,q 值,还有 A R AR AR模型的 p p p 值(虽然是两个 p p p ,但含义不同),所以 G A R C H GARCH GARCH的定阶跟 A R M A ARMA ARMA有点类似。但 G A R C H GARCH GARCH的定阶一般是比较困难的,所以一般都是选择低阶模型如 G A R C H ( 1 , 1 ) GARCH(1,1) GARCH(1,1), G A R C H ( 1 , 2 ) , G A R C H ( 2 , 1 ) GARCH(1,2),GARCH(2,1) GARCH(1,2),GARCH(2,1)。
四:GARCH实验过程
我们还是基于相同的数据集,由于此数据集已经验证不符合 A R C H ARCH ARCH效应,那我们强行建立 G A R C H GARCH GARCH模型看看预测效果。
def make_GARCHmodel(data,pst,lag):
tempmodel = arch.arch_model(data, mean='AR', lags=lag, vol='GARCH', p=2, dist='gaussian').fit(update_freq=0,
disp='off')
print(tempmodel.summary())
pre = tempmodel.forecast(horizon=pst, start=lag - 1, method='simulation').mean.iloc[lag - 1]
print(pre)
init_value = yv[lag]
fig = plt.figure(figsize=(8, 6))
predicthorizon = pre.cumsum() ##差分还原
predicthorizon = init_value + predicthorizon
prelsall = yv[:lag + 1] + list(predicthorizon) ##差分少一个数据并补充
# 作图
plt.plot(prelsall, label='样本预测值')
plt.plot(yv, label='原始值')
plt.legend()
plt.show()
l = 10
presteps = len(yv) - l - 1
preres = make_GARCHmodel(tsres,presteps,l)



注: G A R C H GARCH GARCH更大的作用是对波动率的预测,比如从上面的波动率模型和均值模型我们知道,当计算出来 ε t , ε t − 1 . . . \varepsilon_{t},\varepsilon_{t-1}... εt,εt−1... (真实值和预测值做差), σ t \sigma_t σt 等等后,那么 σ t + 1 \sigma_{t+1} σt+1 就迎刃而解!
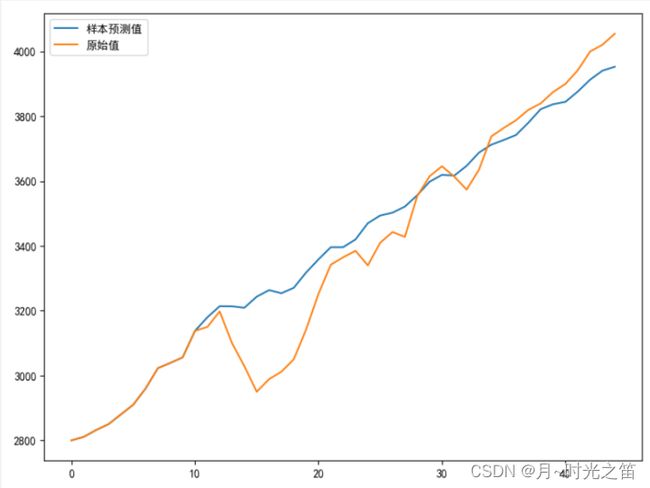
从上图6我们发现, G A R C H GARCH GARCH模型效果还是不如均值模型 A R M A ARMA ARMA效果好,所以在本身数据不符合 A R C H ARCH ARCH效应下,我们还是选择 A R M A ARMA ARMA模型进行建模。这正好能体现不同数据用不同方法建模的道理!
五:总结
- G A R C H GARCH GARCH和 A R C H ARCH ARCH准确的来说属于波动率模型,比如图6计算过程,
- 当只有存在 A R C H ARCH ARCH效应时,我们可以建立波动率模型,否则可以多使用均值模型 ( A R I M A ) (ARIMA) (ARIMA)。
