带马尔科夫切换的正向随机微分方程数值格式模拟
带马尔科夫切换的正向随机微分方程数值格式模拟
-
- 前言
- 一:带马尔科夫切换的随机微分方程(SDEwMS)
- 二:相关伊藤公式
- 三:数值格式
- 四:实验模拟
- 五:总结
前言
在现实世界中, 很多现象或模型都具有状态切换的特性, 用马尔科夫链刻画这一现象, 可以很好地解释不同条件下的随机切换,这导致马尔科夫切换的随机微分方程(SDEwMS)在最近几年的迅速发展。这种随机数学模型不仅能广泛运用于金融市场,而且在控制工程领域同样如此。然而这类模型的显式解是非常难求的,我们此篇文章主要是建立弱一阶Euler和Milstein格式来求解此类随机微分方程,想要了解更高解的弱格式,可以参考如下论文。
Yang Li, Taitao Feng, Yaolei Wang, and Yifei Xin. A high order accurate and effective scheme for solving Markovian switching stochastic models[J]. Mathematics, 2021, 9(6), 588.

一:带马尔科夫切换的随机微分方程(SDEwMS)
1:马尔科夫链知识
- 基础的跳和马尔科夫链知识
在之前的“随机知识”相关文章中,我们详细提到了马氏链以及如何模拟离散马氏链的相关知识,详细可见如下文章,这里不再介绍,但后面的格式模拟会用到此部分知识。
离散马氏链模拟过程
- 泊松随机测度
结合基础知识,我们定义 N ( d e , d t ) N(de,dt) N(de,dt) 为在空间 ε × [ 0 , T ] \varepsilon\times[0,T] ε×[0,T] 上的强度为 λ ( d e ) d t \lambda(de)dt λ(de)dt
的泊松随机测度,其中 λ \lambda λ 为在 ε \varepsilon ε 上的 L e b a n e s e Lebanese Lebanese测度,
有 d r t = ∫ ε l ( r t − , , e ) N ( d e , d t ) dr_t=\int_{\varepsilon}l(r_{t-,},e)N(de,dt) drt=∫εl(rt−,,e)N(de,dt) ,其中 l ( i , e ) = j − i , e ∈ Δ i j ; l ( i , e ) = 0 l(i,e)=j-i,e\in \Delta_{ij};l(i,e)=0 l(i,e)=j−i,e∈Δij;l(i,e)=0, 其他,
其中 Δ i j \Delta_{ij} Δij 是长度 跟 q i j q_{ij} qij 有关的小区间,定义如下:
Δ 12 = [ 0 , q 12 ) , Δ 13 = [ q 12 , q 12 + q 13 ) , . . . , Δ 1 M \Delta_{12}=[0,q_{12}),\Delta_{13}=[q_{12},q_{12}+q_{13}),...,\Delta_{1M} Δ12=[0,q12),Δ13=[q12,q12+q13),...,Δ1M
Δ 12 = [ 0 , q 12 ) , Δ 13 = [ q 12 , q 12 + q 13 ) , . . . , \Delta_{12}=[0,q_{12}),\Delta_{13}=[q_{12},q_{12}+q_{13}),..., Δ12=[0,q12),Δ13=[q12,q12+q13),...,
Δ 1 M = [ ∑ j = 2 M − 1 q 1 j , ∑ j = 2 M q 1 j ) , \Delta_{1M}=\left[ \sum_{j=2}^{M-1}{q_{1j},\sum_{j=2}^{M}{q_{1j}}} \right), Δ1M=[∑j=2M−1q1j,∑j=2Mq1j),
Δ 21 = [ ∑ j = 2 M q 1 j , ∑ j = 2 M q 1 j + q 21 ) , \Delta_{21}=\left[ \sum_{j=2}^{M}{q_{1j}},\sum_{j=2}^{M}{q_{1j}+q_{21}} \right), Δ21=[∑j=2Mq1j,∑j=2Mq1j+q21),
Δ 23 = [ ∑ j = 2 M q 1 j + q 21 , ∑ j = 2 M q 1 j + q 21 + q 23 ) , . . , \Delta_{23}=\left[ \sum_{j=2}^{M}{q_{1j}+q_{21},\sum_{j=2}^{M}{q_{1j}+q_{21}+q_{23}}} \right),.., Δ23=[∑j=2Mq1j+q21,∑j=2Mq1j+q21+q23),..,
Δ 2 M = [ ∑ j = 2 M q 1 j + ∑ j = 1 , j ≠ 2 M − 1 q 2 j , ∑ j = 2 M q 1 j + ∑ j = 1 , j ≠ 2 M q 2 j ) , . . . \Delta_{2M}=\left[ \sum_{j=2}^{M}{q_{1j}}+\sum_{j=1,j\ne2}^{M-1}{q_{2j},\sum_{j=2}^{M}{q_{1j}}+\sum_{j=1,j\ne2}^{M}{q_{2j}}} \right),... Δ2M=[∑j=2Mq1j+∑j=1,j=2M−1q2j,∑j=2Mq1j+∑j=1,j=2Mq2j),...
= [ ∑ j = 2 M − 1 q 1 j , ∑ j = 2 M q 1 j ) , = \left[ \sum_{j=2}^{M-1}{q_{1j},\sum_{j=2}^{M}{q_{1j}}} \right), =[∑j=2M−1q1j,∑j=2Mq1j),
Δ 21 = [ ∑ j = 2 M q 1 j , ∑ j = 2 M q 1 j + q 21 ) , \Delta_{21}=\left[ \sum_{j=2}^{M}{q_{1j}},\sum_{j=2}^{M}{q_{1j}+q_{21}} \right), Δ21=[∑j=2Mq1j,∑j=2Mq1j+q21),
Δ 23 = [ ∑ j = 2 M q 1 j + q 21 , ∑ j = 2 M q 1 j + q 21 + q 23 ) , . . , \Delta_{23}=\left[ \sum_{j=2}^{M}{q_{1j}+q_{21},\sum_{j=2}^{M}{q_{1j}+q_{21}+q_{23}}} \right),.., Δ23=[∑j=2Mq1j+q21,∑j=2Mq1j+q21+q23),..,
Δ 2 M = [ ∑ j = 2 M q 1 j + ∑ j = 1 , j ≠ 2 M − 1 q 2 j , ∑ j = 2 M q 1 j + ∑ j = 1 , j ≠ 2 M q 2 j ) , . . . \Delta_{2M} =\left[ \sum_{j=2}^{M}{q_{1j}}+\sum_{j=1,j\ne2}^{M-1}{q_{2j},\sum_{j=2}^{M}{q_{1j}}+\sum_{j=1,j\ne2}^{M}{q_{2j}}} \right),... Δ2M=[∑j=2Mq1j+∑j=1,j=2M−1q2j,∑j=2Mq1j+∑j=1,j=2Mq2j),...
其中 M M M 是马氏链长度。
2:SDEwMS的结构介绍
在完备概率空间 ( Ω , F , P ) \left( \Omega,F,P \right) (Ω,F,P) ,具有信息流 { F t } t ≥ 0 \left\{ F_t \right\}_{t\geq 0} {Ft}t≥0 ,一般 S D E w M S SDEwMS SDEwMS有如下微分结构:
d X t = f ( t , X t , r t h ) d t + g ( t , X t , r t h ) d W t , t ∈ ( 0 , T ] , X 0 = x 0 dX_t=f(t,X_t,r_t^h)dt+g(t,X_t,r_t^h)dW_t,t\in(0,T],X_0=x_0 dXt=f(t,Xt,rth)dt+g(t,Xt,rth)dWt,t∈(0,T],X0=x0。
其中 T T T 是一个有限的终端时刻, r t h ∈ S = { 1 , 2 , . . . , M } r_t^h\in S=\{1,2,...,M\} rth∈S={1,2,...,M} 为右连续的 B o r e l Borel Borel可测的马尔科夫链。
W t = ( W t 1 , . . . , W t d ) T W_t=\left( W_t^1,...,W_t^d \right)^T Wt=(Wt1,...,Wtd)T 是 d d d 维各元素之间互相独立的布朗运动,
X t = ( X t 1 , . . . , X t q ) T X_t=\left( X_t^1,...,X_t^q \right)^T Xt=(Xt1,...,Xtq)T 是 q q q 维随机过程,漂移项 f ( ⋅ , ⋅ , ⋅ , ) : [ 0 , T ] × R q × S → R q f(\cdot,\cdot,\cdot,):[0,T]\times R^q\times S\rightarrow R^q f(⋅,⋅,⋅,):[0,T]×Rq×S→Rq 和
扩散项 g ( ⋅ , ⋅ , ⋅ , ) : [ 0 , T ] × R q × S → R q × d g(\cdot,\cdot,\cdot,):[0,T]\times R^q\times S\rightarrow R^{q\times d} g(⋅,⋅,⋅,):[0,T]×Rq×S→Rq×d 都是可测函数, x 0 x_0 x0 是方程的初始值。
3:解的存在唯一性定理
对固定常数 L L L 和任意有限的终端时刻, T > 0 , x , y ∈ R q , ∀ t ∈ [ 0 , T ] T>0,x,y\in R^q,\forall t\in [0,T] T>0,x,y∈Rq,∀t∈[0,T], 飘逸系数
f ( ⋅ , ⋅ , ⋅ , ) f(\cdot,\cdot,\cdot,) f(⋅,⋅,⋅,) ,扩散系数 g ( ⋅ , ⋅ , ⋅ , ) g(\cdot,\cdot,\cdot,) g(⋅,⋅,⋅,) 满足 L i p s c h i t z Lipschitz Lipschitz 条件:
∣ f ( t , x , i ) − f ( t , y , i ) ∣ ∨ ∣ g ( t , x , i ) − g ( t , y , i ) ∣ ≤ L ∣ x − y ∣ , ∣ f ( t , x , i ) − f ( s , x , i ) ∣ ≤ L ∣ t − s ∣ \left| f(t,x,i)-f(t,y,i) \right|\vee \left| g(t,x,i)-g(t,y,i) \right|\leq L\left| x-y \right|,\left| f(t,x,i)-f(s,x,i) \right|\leq L\left| t-s \right| ∣f(t,x,i)−f(t,y,i)∣∨∣g(t,x,i)−g(t,y,i)∣≤L∣x−y∣,∣f(t,x,i)−f(s,x,i)∣≤L∣t−s∣。
及线性增长条件:
∣ f ( t , x , i ) ∨ g ( s , x , i ) ∣ ≤ M ( 1 + ∣ x ∣ ) \left| f(t,x,i)\vee g(s,x,i) \right|\leq M(1+\left| x \right|) ∣f(t,x,i)∨g(s,x,i)∣≤M(1+∣x∣) ,
其中 M = L ∨ m a x { ∣ f ( t , 0 , i ) ∨ g ( t , 0 , i ) ∣ } M=L\vee max\{\left| f(t,0,i)\vee g(t,0,i) \right|\} M=L∨max{∣f(t,0,i)∨g(t,0,i)∣}。
所以方程 S D E w M S SDEwMS SDEwMS满足如上条件,当初始条件 x 0 ∈ F 0 x_0\in F_0 x0∈F0 时,方程存在唯一的解
{ X t , t ∈ [ 0 , T ] } \{X_t,t\in [0,T]\} {Xt,t∈[0,T]} 。
具体证明可参阅相关论文文献!
二:相关伊藤公式
伊藤公式是推导相关数值格式的必要理论知识,所以这里要详细介绍一下。
1:伊藤公式
对上述 S D E w M S SDEwMS SDEwMS方程,我们记 x ∈ R q , φ ( t , x , i ) ∈ C 2 , 1 ( [ 0 , T ] × R q × S ; R ) x\in R^q,\varphi(t,x,i) \in C^{2,1}\left( [0,T]\times R^q\times S;R \right) x∈Rq,φ(t,x,i)∈C2,1([0,T]×Rq×S;R) ,定义算子
L 0 φ , L j φ , L e − 1 φ L^0\varphi,L^j\varphi,L_{e}^{-1}{\varphi} L0φ,Ljφ,Le−1φ 从 R q × S → R : L φ 0 = ∂ φ ∂ t + ∑ k = 1 q ∂ φ ∂ x k f k + 1 2 ∑ m = 1 d ∑ l , k = 1 q ∂ 2 φ ∂ x k ∂ x l g l , m g k , m R^q\times S\rightarrow R: L^0_\varphi=\frac{\partial\varphi}{\partial t}+\sum_{k=1}^{q}{\frac{\partial\varphi}{\partial{x_k}}f_k}+\frac{1}{2}\sum_{m=1}^{d}{\sum_{l,k=1}^{q}{\frac{\partial^2\varphi}{\partial x_k\partial{x_l}}g_{l,m}g_{k,m}}} Rq×S→R:Lφ0=∂t∂φ+∑k=1q∂xk∂φfk+21∑m=1d∑l,k=1q∂xk∂xl∂2φgl,mgk,m
+ ∑ j ∈ S q i j φ +\sum_{j\in S}q_{ij}\varphi +∑j∈Sqijφ,
L j φ = ∑ k = 1 q ∂ φ ∂ x k g k , j , L e − 1 φ = φ ( t , x , i + l ( i , e ) ) − φ ( t , x , i ) L^j\varphi=\sum_{k=1}^{q}{\frac{\partial\varphi}{\partial x_k}g_{k,j}},L_{e}^{-1}\varphi=\varphi\left( t,x,i+l(i,e) \right)-\varphi(t,x,i) Ljφ=∑k=1q∂xk∂φgk,j,Le−1φ=φ(t,x,i+l(i,e))−φ(t,x,i),
其中 i ∈ S , i ≤ j ≤ d i\in S,i\leq j\leq d i∈S,i≤j≤d。
我们得到如下伊藤积分公式:
φ ( t n + 1 , X t n + 1 , r t n + 1 ) = φ ( t n , X t n , r t n ) + ∫ t n t n + 1 L 0 φ ( s , X s , r s ) d s + \varphi\left( t_{n+1},X_{t_{n+1}},r_{t_{n+1}} \right)=\varphi(t_n,X_{t_n},r_{t_n})+\int_{t_n}^{t_{n+1}}L^0\varphi(s,X_s,r_s)ds+ φ(tn+1,Xtn+1,rtn+1)=φ(tn,Xtn,rtn)+∫tntn+1L0φ(s,Xs,rs)ds+
∑ j = 1 d ∫ t n t n + 1 L j φ ( s , X s , r s ) d W s j + ∫ t n t n + 1 ∫ ε L e − 1 φ ( s , X s , r s ) N ~ ( d e , d s ) \sum_{j=1}^{d}{\int_{t_n}^{t_{n+1}}L^j\varphi(s,X_s,r_s)dW_{s}^{j}} +\int_{t_n}^{t_{n+1}}\int_{\varepsilon}L_{e}^{-1}\varphi\left( s,X_s,r_s \right)\tilde{N}(de,ds) ∑j=1d∫tntn+1Ljφ(s,Xs,rs)dWsj+∫tntn+1∫εLe−1φ(s,Xs,rs)N~(de,ds),
这里 N ~ ( d e , d s ) = N ( d e , d s ) − λ ( d e ) d s \tilde{N}(de,ds)=N(de,ds)-\lambda(de)ds N~(de,ds)=N(de,ds)−λ(de)ds 是一个补偿泊松测度。
2:伊藤展开
结合上述的伊藤公式算子,对任意 φ ( t n + 1 , X t n + 1 , r t n + 1 ) ∈ C 2 , 1 ( R q × S ; R ) \varphi\left( t_{n+1},X_{t_{n+1}},r_{t_{n+1}} \right)\in C^{2,1}(R^q\times S;R) φ(tn+1,Xtn+1,rtn+1)∈C2,1(Rq×S;R) ,在 t_n 处使用伊藤公式得到如下积分形式:
φ ( t n + 1 , X t n + 1 , r t n + 1 ) = φ ( t n , X t n , r t n ) + ∫ t n t n + 1 L 0 φ ( s , X s , r s ) d s + \varphi\left( t_{n+1},X_{t_{n+1}},r_{t_{n+1}} \right)=\varphi\left( t_{n},X_{t_{n}},r_{t_{n}} \right)+\int_{t_n}^{t_{n+1}}L^0\varphi\left( s,X_s,r_s \right)ds+ φ(tn+1,Xtn+1,rtn+1)=φ(tn,Xtn,rtn)+∫tntn+1L0φ(s,Xs,rs)ds+
∑ j = 1 d ∫ t n t n + 1 L j φ ( s , X s , r s ) d W s j \sum_{j=1}^{d}{\int_{t_n}^{t_{n+1}}L^j\varphi\left( s,X_s,r_s \right)dW_{s}^{j}} ∑j=1d∫tntn+1Ljφ(s,Xs,rs)dWsj,
为了简化叙述伊藤展开,我们令 d = q = 1 d=q=1 d=q=1 ,同理得:
φ ( t n + 1 , X t n + 1 , r t n + 1 ) = φ ( t n , X t n , r t n ) + ∫ t n t n + 1 L 0 φ ( s , X s , r s ) d s + ∫ t n t n + 1 L 1 φ ( s , X s , r s ) d W s \varphi\left( t_{n+1},X_{t_{n+1}},r_{t_{n+1}} \right)=\varphi\left( t_{n},X_{t_{n}},r_{t_{n}} \right)+\int_{t_n}^{t_{n+1}}L^0\varphi\left( s,X_s,r_s \right)ds+{\int_{t_n}^{t_{n+1}}L^1\varphi\left( s,X_s,r_s \right)dW_{s}} φ(tn+1,Xtn+1,rtn+1)=φ(tn,Xtn,rtn)+∫tntn+1L0φ(s,Xs,rs)ds+∫tntn+1L1φ(s,Xs,rs)dWs,
我们再对 L 0 φ ( s , X s , r s ) 和 L 1 φ ( s , X s , r s ) L^0\varphi\left( s,X_s,r_s \right) 和 L^1\varphi\left( s,X_s,r_s \right) L0φ(s,Xs,rs)和L1φ(s,Xs,rs) 使用伊藤公式可得:
φ ( t n + 1 , X t n + 1 , r t n + 1 ) = φ ( t n , X t n , r t n ) + \varphi\left( t_{n+1},X_{t_{n+1}},r_{t_{n+1}} \right)=\varphi\left( t_{n},X_{t_{n}},r_{t_{n}} \right)+ φ(tn+1,Xtn+1,rtn+1)=φ(tn,Xtn,rtn)+
∫ t n t n + 1 [ L 0 φ ( s , X s , r s ) + ∫ t n s L 0 L 0 φ ( τ , X τ , r τ ) d τ + ∫ t n s L 1 L 0 φ ( τ , X τ , r τ ) d W τ + ∫ t n s L e − 1 L 0 φ ( τ , X τ , r τ ) d N ~ τ ] d s + \int_{t_n}^{t_{n+1}}\left[ L^0\varphi\left( s,X_{s},r_{s} \right)+\int_{t_n}^{s}L^0L^0\varphi\left( \tau,X_{\tau},r_{\tau} \right)d\tau+\int_{t_n}^{s}L^1L^0\varphi\left( \tau,X_{\tau},r_{\tau} \right)dW_\tau+\int_{t_n}^{s}L_{e}^{-1}L^0\varphi\left( \tau,X_{\tau},r_{\tau} \right)d\tilde{N}_\tau \right]ds + ∫tntn+1[L0φ(s,Xs,rs)+∫tnsL0L0φ(τ,Xτ,rτ)dτ+∫tnsL1L0φ(τ,Xτ,rτ)dWτ+∫tnsLe−1L0φ(τ,Xτ,rτ)dN~τ]ds+
∫ t n t n + 1 [ L 1 φ ( s , X s , r s ) + ∫ t n s L 0 L 1 φ ( τ , X τ , r τ ) d τ + ∫ t n s L 1 L 1 φ ( τ , X τ , r τ ) d W τ + ∫ t n s L e − 1 L 1 φ ( τ , X τ , r τ ) d N ~ τ ] d W s \int_{t_n}^{t_{n+1}}\left[ L^1\varphi\left( s,X_s,r_s \right) +\int_{t_n}^{s}L^0L^1\varphi\left( \tau,X_{\tau},r_{\tau} \right)d\tau+\int_{t_n}^{s}L^1L^1\varphi\left( \tau,X_{\tau},r_{\tau} \right)dW_\tau+\int_{t_n}^{s}L_{e}^{-1}L^1\varphi\left( \tau,X_{\tau},r_{\tau} \right)d\tilde{N}\tau\right]dW_s ∫tntn+1[L1φ(s,Xs,rs)+∫tnsL0L1φ(τ,Xτ,rτ)dτ+∫tnsL1L1φ(τ,Xτ,rτ)dWτ+∫tnsLe−1L1φ(τ,Xτ,rτ)dN~τ]dWs。
在得到上面等式中, 若 φ ( s , X s , r s ) \varphi\left( s,X_{s},r_{s} \right) φ(s,Xs,rs) 足够光滑, 我们继续对上述涉及的多维积分展开, 可以得到更高阶的数值格式。
三:数值格式
1:弱收敛定义
给定时间分割 0 = t 0 < t 1 < . . . < t N − 1 < t N = T 0=t_0
W t n ( n = 0 , 1 , 2 , . . . , N ) W_{t_n}(n=0,1,2,...,N) Wtn(n=0,1,2,...,N), 且存在光滑函数 G ∈ C p 2 ( β + 1 ) G\in C_p^{2(\beta+1)} G∈Cp2(β+1) 和正常数 C C C 满足不等式
∣ E [ G ( X t ) − G ( X N ) ] ∣ ≤ C ( 1 + E [ ∣ X 0 ∣ b ] ) ( Δ t ) β \left| E[G(X_t)-G(X^N)] \right|\leq C\left( 1+E[|X_0|^b] \right)(\Delta t)^\beta ∣ ∣E[G(Xt)−G(XN)]∣ ∣≤C(1+E[∣X0∣b])(Δt)β,
其中 β , b ∈ N \beta,b\in N β,b∈N ,则 X N X^N XN 以阶数 \beta 弱收敛于 X T X_T XT。 当然有弱收敛就有强收敛,当我们不以整个轨迹误差取期望再绝对值,取而代之的是以每个点的绝对误差取期望后,就是我们的强收敛误差要求,高阶强收敛格式更加复杂,条件更加苛刻,阶数可以是0.5的倍数关系。
2:弱一阶收敛格式
我们简记 f k i = f ( t , X n , i ) , g k i = g ( t , X n , i ) f_k^i=f(t,X^n,i) , g_k^i=g(t,X^n,i) fki=f(t,Xn,i),gki=g(t,Xn,i) , 于是有如下格式:
设初始条件 X 0 X_0 X0 已知,对于 0 ≤ n ≤ N − 1 0\leq n\leq N-1 0≤n≤N−1 ,对于 m m m 维的伊藤过程的第 k k k 个分量,我们有如下格式:
1:欧拉格式(弱1.0阶,强0.5阶): X k n + 1 , i = X k n + f k i Δ t + g k i Δ W n X^{n+1,i}_k=X_k^n+f_k^i\Delta t+g_k^i\Delta W_n Xkn+1,i=Xkn+fkiΔt+gkiΔWn
2:米尔斯坦格式(强弱都是1.0阶): X k n + 1 , i = X k n + f k i Δ t + g k i Δ W n + 1 2 L 1 g k i ( ( Δ W n ) 2 − Δ t ) X^{n+1,i}_k=X_k^n+f_k^i\Delta t+g_k^i\Delta W_n+\frac{1}{2}L^1g_k^i\left( (\Delta W_n)^2-\Delta t \right) Xkn+1,i=Xkn+fkiΔt+gkiΔWn+21L1gki((ΔWn)2−Δt)
3:高阶收敛格式
高阶格式的形式比较复杂,且模拟和证明难度较大,想要了解更高解的弱格式,可以参考如下论文。
Yang Li, Taitao Feng, Yaolei Wang, and Yifei Xin. A high order accurate and effective scheme for solving Markovian switching stochastic models[J]. Mathematics, 2021, 9(6), 588.
四:实验模拟
- 马尔科夫链代码
import matplotlib.pyplot as plt
import numpy as np
import time
plt.rcParams['font.sans-serif']=['SimHei']##中文乱码问题!
plt.rcParams['axes.unicode_minus']=False#横坐标负号显示问题!
start_time = time.time()
def markov_m(days,delta):
original_value = 1 ## 设置初始状态
r = np.array([[-1,0.6,0.4], [10 ,-5, 5], [3, 1, -4]]) ###根据定义随意给的的转移速率矩阵
p = r * delta
for i in range(r.shape[1]):
p[i, i] = 1 + p[i, i]
# P = np.exp(delta * r) - 1
# for i in range(r.shape[1]):
# P[i, i] = 1 + P[i, i]
# print(P) ###delta越小,P跟p越接近
U = np.random.uniform(0,1,days)
q = np.zeros((1,days))
for i in range(days):
u = U[i]
v_temp = original_value
q[:,i] = v_temp
original_value = 1
s = 0
while original_value <= p.shape[1] and u > s:
s = s + p[v_temp - 1, original_value - 1] ###概率值叠加
original_value = original_value + 1 ###矩阵列索引变大
original_value = original_value - 1 ##由于开始original_value =1,所以要减1
return p,q.tolist()[0]
- SDEwMS格式模拟代码
def schemes(a_ls,b_ls,names):
time_ls = [16,32,64,128,256]
tran_matx_ls = []
state_vect_ls = []
for i in time_ls:
mres = markov_m(i, 0.1)##调用马氏链模拟函数
tran_matx = mres[0]
state_vect = mres[1]
print('\033[1;31m时间长度为%s时转移概率矩阵为:\033[0m'%i)
print(tran_matx)
tran_matx_ls.append(tran_matx)
print('\033[1;34m时间长度为%s时状态向量为:\033[0m'%i)
print(state_vect)
state_vect_ls.append(state_vect)
logtimels = []
logerrorls = []
CRls = []
msg = '''
1:exp函数
2:sin函数
3:原函数的2.5次方
4:原函数
'''
print(msg)
msg_ls = ['exp函数','sin函数','原函数的2.5次方','原函数']
##定义初始化内容
choose = int(input('请选择g(x)函数:'))
echoes = 500
error_ls = []
value_matx = np.zeros((echoes,len(time_ls)))
Euler = 'y + a * dt * y + b * y * dwt_temp'
Milstein = Euler + ' + 0.5 * b * b * y * (dwt_temp * dwt_temp - dt)'
schemes_ls = [Euler,Milstein]
x0 = 1.5 ##SDE真解初始值
for s,n in zip(schemes_ls,names):
for e in range(echoes):
for i in range(len(time_ls)):
y = x0 ##数值格式初始值
N = time_ls[i]
dt = 1 / N
yt = []
dwt = np.random.normal(0,1,N) * np.sqrt(dt)
nowstate_vect = state_vect_ls[i]
###真解求解过程
v_ls = []
vtemp = 0
for j in range(N):##循环长度
a = a_ls[int(nowstate_vect[j] - 1)]##取对应的mu系数
b = b_ls[int(nowstate_vect[j] - 1)]##取对应的sigm系数
vtemp = vtemp + (a - 0.5 * b * b) * dt + b * dwt[j]##对于离散可变系数,用积分定义求解其真解
v_ls.append(vtemp)
xT = ''##分配个内存
finv = x0 * np.exp(v_ls[-1])
if choose == 1:
xT = np.exp(finv)
if choose == 2:
xT = np.sin(finv)
if choose == 3:
xT = np.power(finv,2.5)
if choose == 4:
xT = finv
##数值格式解
for j in range(N):
a = a_ls[int(nowstate_vect[j]-1)]##取对应的mu系数
b = b_ls[int(nowstate_vect[j]-1)]##取对应的sigm系数
dwt_temp = dwt[j]
y = eval(s)
if choose == 1:
yt.append(np.exp(y))
if choose == 2:
yt.append(np.sin(y))
if choose == 3:
yt.append(np.power(y,2.5))
if choose == 4:
yt.append(y)
error_temp = yt[N - 1] - xT ##真解与数值解末端值作差
error_ls.append(error_temp)
value_matx[e,:] = error_ls
error_ls = []
error_fin = np.abs(sum(value_matx) / echoes)##弱收敛最终求期望
log_time = np.log(1 / np.array(time_ls))
log_error_fin = np.log(error_fin)
CR = np.polyfit(log_time,log_error_fin,1)##一次多项式拟合
print('\033[1;36m{0:*^80}\033[0m'.format('计算结果'))
print('格式%s的误差绝对值期望为:%s'%(n,np.round(error_fin,6)))
print('格式%s的弱收敛阶为:%s'%(n,round(CR[0],6)))
logerrorls.append(np.round(log_error_fin,6))
logtimels.append(log_time)
CRls.append(round(CR[0],6))
return logtimels,logerrorls,CRls,msg_ls[choose - 1]
statemu_ls = [1,0.8,0.9]##飘逸系数
statesigm_ls = [-0.1,0.2,0.05]##扩散系数
scheme_names = ['Euler', 'Milstein']
R = schemes(statemu_ls,statesigm_ls,scheme_names)


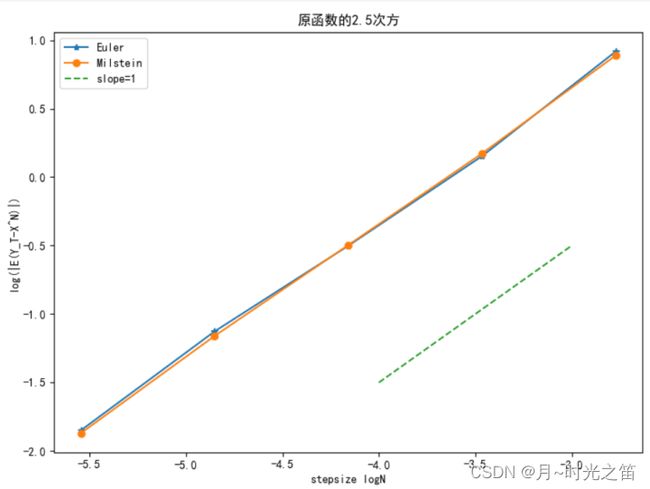
上图图1和图2就是模拟的实验结果,符合理论结果!
- 作图代码
marker_ls = ['-*','-o']
def make_figure():
plt.figure(figsize=(8, 6))
for i,j,l,m in zip(R[0],R[1],scheme_names,marker_ls):
plt.plot(i,j,m,label=l)
plt.plot(np.array([-4,-3]),np.array([-4,-3]) + 2.5,'--',label='slope=1')
plt.xlabel('stepsize logN')
plt.ylabel('log(|E(Y_T-X^N)|)')
plt.title(R[3])
plt.legend()
plt.show()
make_figure()
五:总结
SDEwMS是SDE的一个推广,试用性更强,但是对应的数值解理论会变得更加复杂。近年来,很多人也研究倒向带马尔科夫的随机微分方程并取得了很多理论上的突破。
随机微分方程是个很深很广的研究领域,无论正向还是倒向,无论带切换还是带跳还是带反射,都是值得研究的,有兴趣的朋友可以多研读这方面的著作,本篇内容仅抛砖引玉之用!