机器学习笔记之受限玻尔兹曼机(二)模型表示
机器学习笔记之受限玻尔兹曼机——模型表示
- 引言
-
- 回顾:玻尔兹曼分布
- 玻尔兹曼机
-
- 关于玻尔兹曼机的问题
- 受限玻尔兹曼机
- 受限玻尔兹曼机的学习任务(填坑)
引言
上一节基于马尔可夫随机场介绍了玻尔兹曼分布,本节将介绍受限玻尔兹曼机的模型表示(Representation)与 学习任务(Laerning)。
回顾:玻尔兹曼分布
基于Hammersley-Clifford定理,可以将马尔可夫随机场 G \mathcal G G中关于随机变量集合的联合概率分布 P ( X ) \mathcal P(\mathcal X) P(X)表示为如下形式:
P ( X ) = 1 Z ∏ i = 1 K ψ i ( x C i ) \mathcal P(\mathcal X) = \frac{1}{\mathcal Z} \prod_{i=1}^{\mathcal K} \psi_i(x_{\mathcal C_i}) P(X)=Z1i=1∏Kψi(xCi)
其中 x C i ( i = 1 , 2 , ⋯ , K ) x_{\mathcal C_i}(i=1,2,\cdots,\mathcal K) xCi(i=1,2,⋯,K)表示极大团 C i \mathcal C_i Ci中结点组成的随机变量集合; ψ i ( x C i ) \psi_i(x_{\mathcal C_i}) ψi(xCi)表示极大团 x C i x_{\mathcal C_i} xCi对应的势函数; Z \mathcal Z Z表示规范化因子。
由于势函数的恒正属性,因此通常将势函数使用能量函数进行表示:
ψ i ( x C i ) = exp { − E [ x C i ] } i = 1 , 2 , ⋯ , K \psi_i(x_{\mathcal C_i}) = \exp \left\{-\mathbb E[x_{\mathcal C_i}]\right \} \quad i=1,2,\cdots,\mathcal K ψi(xCi)=exp{−E[xCi]}i=1,2,⋯,K
那么 基于能量函数表示的联合概率分布 P ( X ) \mathcal P(\mathcal X) P(X)被称作吉布斯分布,也称玻尔兹曼分布:
这里全部使用’玻尔兹曼分布‘进行描述。
P ( X ) = 1 Z ∏ i = 1 K exp { − E [ x C i ] } = 1 Z exp [ − ∑ i = 1 K E [ x C i ] ] \begin{aligned} \mathcal P(\mathcal X) & = \frac{1}{\mathcal Z} \prod_{i=1}^{\mathcal K} \exp \left\{- \mathbb E[x_{\mathcal C_i}]\right\} \\ & = \frac{1}{\mathcal Z} \exp \left[- \sum_{i=1}^{\mathcal K} \mathbb E[x_{\mathcal C_i}]\right] \end{aligned} P(X)=Z1i=1∏Kexp{−E[xCi]}=Z1exp[−i=1∑KE[xCi]]
此时的联合概率分布 P ( X ) \mathcal P(\mathcal X) P(X)明显是指数族分布的表示形式。
可以将 − ∑ i = 1 K E [ x C i ] -\sum_{i=1}^{\mathcal K} \mathbb E[x_{\mathcal C_i}] −∑i=1KE[xCi]看作是’某权重矩阵‘ W \mathcal W W与’极大团向量‘ x C = ( x C 1 , x C 2 , ⋯ , x C K ) T x_{\mathcal C} = (x_{\mathcal C_1},x_{\mathcal C_2},\cdots,x_{\mathcal C_{\mathcal K}})^T xC=(xC1,xC2,⋯,xCK)T的线性组合。
1 Z exp [ − ∑ i = 1 K E [ x C i ] ] ⇒ 1 Z exp [ W T x C ] \frac{1}{\mathcal Z} \exp \left[- \sum_{i=1}^{\mathcal K} \mathbb E[x_{\mathcal C_i}]\right] \Rightarrow \frac{1}{\mathcal Z} \exp [\mathcal W^T x_{\mathcal C}] Z1exp[−i=1∑KE[xCi]]⇒Z1exp[WTxC]
如果给能量函数 E [ x C i ] ( i = 1 , 2 , ⋯ , K ) \mathbb E[x_{\mathcal C_i}](i=1,2,\cdots,\mathcal K) E[xCi](i=1,2,⋯,K)一个准确描述的话,可以将 E [ x C i ] \mathbb E[x_{\mathcal C_i}] E[xCi]描述为如下形式:
E [ x C i ] = − { [ x C i ] T U x C i + b T x C i } i = 1 , 2 , ⋯ , K \mathbb E[x_{\mathcal C_i}] = - \left\{[x_{\mathcal C_i}]^T \mathcal U x_{\mathcal C_i} + b^T x_{\mathcal C_i}\right\} \quad i=1,2,\cdots,\mathcal K E[xCi]=−{[xCi]TUxCi+bTxCi}i=1,2,⋯,K
其中 U \mathcal U U表示模型参数的权重矩阵; b b b表示偏置向量。
个人理解:在花书(第20章)将随机变量集合x x x描述为一个d d d维的分布。为了简化运算,将每一维分布均设为’伯努利分布‘,从而将’能量函数‘描述为如下形式:
E ( x ) = − x T U x − b T x \mathbb E(x) = - x^T\mathcal U x - b^Tx E(x)=−xTUx−bTx
回归文章示例,将p p p维随机变量X \mathcal X X表示为’若干个结点‘(可能有的结点内部包含一个随机变量,有的包含多个),然后将这些结点归纳为K \mathcal K K个极大团x C i ( i = 1 , 2 , ⋯ , K ) x_{\mathcal C_i}(i=1,2,\cdots,\mathcal K) xCi(i=1,2,⋯,K)。可以将每个极大团中的随机变量看作是X \mathcal X X的一个子集,因而这里的表述没什么问题。欢迎小伙伴们交流讨论。
玻尔兹曼机
玻尔兹曼机(Boltzmann Machine,BM)示例表示如下:
蓝色结点表示观测变量,白色结点表示隐变量,下同。
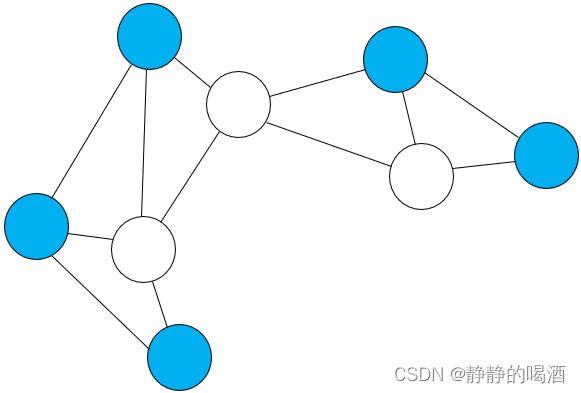
玻尔兹曼机本质上就是一个马尔可夫随机场,但是不同点在于玻尔兹曼机将随机变量集合 X \mathcal X X分成了两个子集:
需要注意的是,这里的 m , n , p m,n,p m,n,p表示随机变量的维度,而不是极大团的编号。
X = ( x 1 , x 2 , ⋯ x p ) T ⇒ ( h v ) { h = ( h 1 , h 2 , ⋯ , h m ) T v = ( v 1 , v 2 , ⋯ , v n ) T m + n = p \begin{aligned} \mathcal X & = (x_1,x_2,\cdots x_p)^T \Rightarrow \begin{pmatrix}h \\ v \end{pmatrix}\\ & \begin{cases} h = (h_1,h_2,\cdots,h_m)^T \\ v = (v_1,v_2,\cdots,v_n)^T \quad m + n = p \end{cases} \end{aligned} X=(x1,x2,⋯xp)T⇒(hv){h=(h1,h2,⋯,hm)Tv=(v1,v2,⋯,vn)Tm+n=p
其中 v v v表示观测变量; h h h表示隐变量。它的能量函数不同于单个随机变量种类 x ∈ R p \mathcal x \in \mathbb R^p x∈Rp,它的能量函数根据图中边两端结点种类 分为三种表示:
E ( v , h ) = − [ ( v T R v + b T v ) + v T W h + ( h T S h + c T h ) ] \mathbb E(v,h) = - \left[(v^T\mathcal Rv + b^Tv) + v^T \mathcal W h + (h^T\mathcal S h + c^T h)\right] E(v,h)=−[(vTRv+bTv)+vTWh+(hTSh+cTh)]
以观测变量v v v内部的边为例。v i , v j ∈ v v_i,v_j \in v vi,vj∈v表示观测变量的两个结点,它们之间的能量(边;关联关系)可表示为:
E ( v i , v j ) = − v i ⋅ r i j ⋅ v j \mathbb E(v_i,v_j) = - v_i \cdot r_{ij} \cdot v_j E(vi,vj)=−vi⋅rij⋅vj
其中r i j r_{ij} rij表示v i , v j v_i,v_j vi,vj之间的权重系数。至此,观测变量v v v内部的能量结果可表示为如下形式:
− ∑ i = 1 m ∑ j = 1 m v i ⋅ r i j ⋅ v j = − ( v 1 , v 2 , ⋯ , v m ) ( r 11 , r 12 , ⋯ , r 1 m r 21 , r 22 , ⋯ , r 2 m ⋮ r m 1 , r m 2 , ⋯ , r m m ) ( v 1 v 2 ⋮ v m ) = − v T R v \begin{aligned}- \sum_{i=1}^m\sum_{j=1}^m v_i \cdot r_{ij} \cdot v_j & = -(v_1,v_2,\cdots,v_m)\begin{pmatrix} r_{11},r_{12},\cdots,r_{1m} \\ r_{21},r_{22},\cdots,r_{2m} \\ \vdots \\ r_{m1},r_{m2},\cdots,r_{mm} \\ \end{pmatrix}\begin{pmatrix} v_1 \\ v_2 \\ \vdots \\ v_m \end{pmatrix} \\ & = -v^T\mathcal Rv \end{aligned} −i=1∑mj=1∑mvi⋅rij⋅vj=−(v1,v2,⋯,vm)⎝⎜⎜⎜⎛r11,r12,⋯,r1mr21,r22,⋯,r2m⋮rm1,rm2,⋯,rmm⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛v1v2⋮vm⎠⎟⎟⎟⎞=−vTRv其他表示边的关系如− v T W h , − h T S h - v^T\mathcal Wh,-h^T\mathcal Sh −vTWh,−hTSh同理。关于结点本身的能量也通过权重系数进行表达。如观测变量的能量表达:∑ i = 1 m b i v i = b T v \sum_{i=1}^m b_iv_i = b^Tv ∑i=1mbivi=bTv,隐变量同理。
其中 R , b \mathcal R,b R,b表示基于观测变量团的权重矩阵和偏置向量; S , c \mathcal S,c S,c表示基于隐变量团的权重矩阵和偏置向量; W \mathcal W W表示边两端分别是观测变量和隐变量的权重矩阵。
最终,玻尔兹曼机对应的 联合概率分布(概率质量函数) 表示如下:
在后续’玻尔兹曼机‘中将继续进行介绍。
P ( v , h ) = 1 Z exp { − E [ v , h ] } = 1 Z exp { [ ( v T R v + b T v ) + v T W h + ( h T S h + c T h ) ] } \begin{aligned} \mathcal P(v,h) & = \frac{1}{\mathcal Z} \exp \{- \mathbb E[v,h]\} \\ & = \frac{1}{\mathcal Z} \exp \left\{\left[(v^T\mathcal Rv + b^Tv) + v^T \mathcal W h + (h^T\mathcal S h + c^T h)\right] \right\} \end{aligned} P(v,h)=Z1exp{−E[v,h]}=Z1exp{[(vTRv+bTv)+vTWh+(hTSh+cTh)]}
关于玻尔兹曼机的问题
如果并不是所有变量都能够被观测,如隐变量的存在。这种情况下,隐变量类似于神经网络中的隐藏层神经元,此时的波尔兹曼机就不再局限于变量之间的线性关系了。通过对模型的学习,类似于神经网络隐藏层的函数逼近定理,它可以对 离散型随机变量的任意概率质量函数 P ( X ) \mathcal P(\mathcal X) P(X)进行逼近。
当然,这种情况下,同样需要玻尔兹曼机内部结点之间存在丰富的关联关系。如下图:

这种复杂结构引出玻尔兹曼机的缺陷:由于结构过于复杂,没有办法对其进行精确推断。
其次,如果使用近似推断,如马尔可夫链蒙特卡罗方法,由于分布过于复杂,需要采集足够量的样本对其进行近似。这种方式的计算量过于庞大。
受限玻尔兹曼机
玻尔兹曼机的缺陷主要在于模型对应的概率图结构过于复杂。受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是在玻尔兹曼机的基础上,对结点间的边进行约束。约束要求是:只有隐变量 h h h和观测变量 v v v之间存在连接, h , v h,v h,v变量内部无连接。
上图关于优化后的受限玻尔兹曼机表示如下:
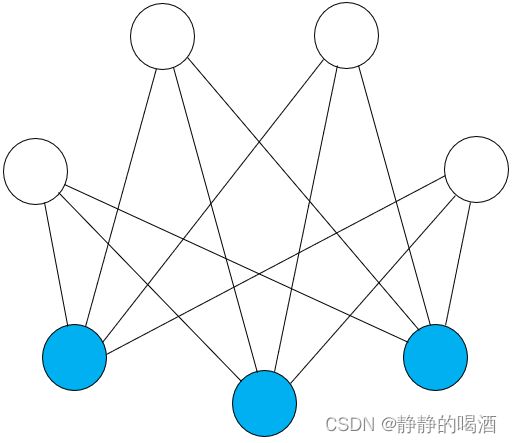
同理,基于改进后的概率图表达,可以对波尔兹曼机的联合概率分布进行优化:
P ( X ) = P ( v , h ) = 1 Z exp { − E ( v , h ) } = 1 Z exp ( v T W h + b T v + c T h ) \begin{aligned} \mathcal P(\mathcal X) = \mathcal P(v,h) & = \frac{1}{\mathcal Z} \exp \{- \mathbb E(v,h)\} \\ & = \frac{1}{\mathcal Z} \exp (v^T \mathcal W h + b^Tv + c^Th) \end{aligned} P(X)=P(v,h)=Z1exp{−E(v,h)}=Z1exp(vTWh+bTv+cTh)
继续对上式进行展开:
P ( v , h ) = 1 Z exp [ v T W h ] ⋅ exp [ b T v ] ⋅ exp [ c T h ] = 1 Z { exp [ ∑ i = 1 m ∑ j = 1 n v i ⋅ w i j ⋅ h j ] ⋅ exp [ ∑ i = 1 m b i v i ] ⋅ exp [ ∑ j = 1 n c j h j ] } = 1 Z { ∏ i = 1 m ∏ j = 1 n exp ( v i ⋅ w i j ⋅ h j ) ⋅ ∏ i = 1 m exp ( b i v i ) ∏ j = 1 n exp ( c j h j ) } \begin{aligned} \mathcal P(v,h) & = \frac{1}{\mathcal Z} \exp [v^T \mathcal W h] \cdot \exp[b^Tv] \cdot \exp[c^Th] \\ & = \frac{1}{\mathcal Z} \left\{\exp \left[\sum_{i=1}^m\sum_{j=1}^n v_i \cdot w_{ij}\cdot h_j \right] \cdot \exp \left[\sum_{i=1}^m b_iv_i\right] \cdot \exp \left[\sum_{j=1}^n c_jh_j\right]\right\} \\ & = \frac{1}{\mathcal Z} \left\{\prod_{i=1}^m\prod_{j=1}^n \exp (v_i \cdot w_{ij} \cdot h_j) \cdot \prod_{i=1}^m \exp (b_iv_i) \prod_{j=1}^n \exp(c_jh_j)\right\} \end{aligned} P(v,h)=Z1exp[vTWh]⋅exp[bTv]⋅exp[cTh]=Z1{exp[i=1∑mj=1∑nvi⋅wij⋅hj]⋅exp[i=1∑mbivi]⋅exp[j=1∑ncjhj]}=Z1{i=1∏mj=1∏nexp(vi⋅wij⋅hj)⋅i=1∏mexp(bivi)j=1∏nexp(cjhj)}
上式展开后的结果就是各种各样的指数函数做乘法。因此可以从因子图(Factor Graph)的角度对受限玻尔兹曼机进行描述,对应因子图表示如下:
例如团(实际上就是极大团) v i ⇔ h j v_i \Leftrightarrow h_j vi⇔hj可以定义为 f i j ( v i , h j ) = exp ( v i ⋅ w i j ⋅ h j ) f_{ij}(v_i,h_j) = \exp (v_i \cdot w_{ij} \cdot h_j) fij(vi,hj)=exp(vi⋅wij⋅hj),其他同理。这里就不多描述了。
因受限玻尔兹曼机的性质,其概率图中任意三个结点之间均不能构成极大团。因此,每一条边对应的两个结点都是一个极大团。

最终,受限玻尔兹曼机需要学习的参数包含以下三个:
W = ( w 11 , w 12 , ⋯ , w 1 n w 21 , w 22 , ⋯ , w 2 n ⋮ w m 1 , w m 2 , ⋯ , w m n ) m × n b = ( b 1 b 2 ⋮ b m ) m × 1 c = ( c 1 c 2 ⋮ c n ) n × 1 \mathcal W = \begin{pmatrix} w_{11},w_{12},\cdots,w_{1n} \\ w_{21},w_{22},\cdots,w_{2n} \\ \vdots \\ w_{m1},w_{m2},\cdots,w_{mn} \\ \end{pmatrix}_{m \times n} \quad b = \begin{pmatrix} b_1 \\ b_2 \\ \vdots \\ b_{m} \end{pmatrix}_{m \times 1} \quad c = \begin{pmatrix} c_1 \\ c_2 \\ \vdots \\ c_{n} \end{pmatrix}_{n \times 1} W=⎝⎜⎜⎜⎛w11,w12,⋯,w1nw21,w22,⋯,w2n⋮wm1,wm2,⋯,wmn⎠⎟⎟⎟⎞m×nb=⎝⎜⎜⎜⎛b1b2⋮bm⎠⎟⎟⎟⎞m×1c=⎝⎜⎜⎜⎛c1c2⋮cn⎠⎟⎟⎟⎞n×1
受限玻尔兹曼机的学习任务(填坑)
在介绍对比散度(Contrastive Divergence)介绍完毕后,再介绍受限玻尔兹曼机的学习任务。
相关参考:
深度学习(花书)——第20章 深度生成模型
(系列二十八)玻尔兹曼机1-介绍
机器学习-受限玻尔兹曼机(3)-模型表示(Representation)