关于gensim库中lda主题模型困惑度和一致性python图像绘制
关于gensim库中lda主题模型困惑度和一致性python图像绘制
第三方库使用: matplotlib
前期准备
函数参数解释
num_topics: 主题数量
corpus: 处理过的文档语料
texts:二维列表(源代码存储的是中文分词)
dictionary:对应词典
import gensim
from gensim import corpora, models
"""
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
"""
def lda_model_values(num_topics, corpus, dictionary):
x = [] # x轴
perplexity_values = [] # 困惑度
coherence_values = [] # 一致性
model_list = [] # 存储对应主题数量下的lda模型,便于生成可视化网页
for topic in range(num_topics):
print("主题数量:", topic+1)
lda_model = models.LdaModel(corpus=corpus, num_topics=topic+1, id2word =dictionary, chunksize = 2000, passes=20, iterations = 400)
model_list.append(lda_model)
x.append(topic+1)
perplexity_values.append(lda_model.log_perplexity(corpus))
coherencemodel = models.CoherenceModel(model=lda_model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
print("该主题评价完成\n")
return model_list, x, perplexity_values, coherence_values
绘图
import matplotlib.pyplot as plt
import matplotlib
from pylab import xticks,yticks,np
# 调用准备函数
model_list, x, perplexity_values, coherence_values = lda_model_values(num_topics, corpus, dictionary)
# 绘制困惑度和一致性折线图
fig = plt.figure(figsize=(15,5))
plt.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
ax1 = fig.add_subplot(1, 2, 1)
plt.plot(x, perplexity_values, marker="o")
plt.title("主题建模-困惑度")
plt.xlabel('主题数目')
plt.ylabel('困惑度大小')
xticks(np.linspace(1, num_topics, num_topics, endpoint=True)) # 保证x轴刻度为1
ax2 = fig.add_subplot(1, 2, 2)
plt.plot(x, coherence_values, marker="o")
plt.title("主题建模-一致性")
plt.xlabel("主题数目")
plt.ylabel("一致性大小")
xticks(np.linspace(1, num_topics, num_topics, endpoint=True))
plt.show()
效果展示
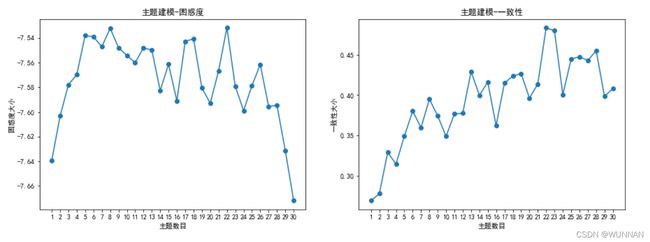
关于模型的困惑度问题
gensim库的困惑度并不是指主题模型的困惑度python gensim里的log_perplexity得出的结果是困惑度吗?
困惑度计算推荐:python下进行lda主题挖掘(三)——计算困惑度perplexity
关于代码的使用问题
建议先会使用gensim库中关于lda的函数,包括corpus和dictionary的生成