Redis对象及redisObject源码解析
写在前面
以下内容是基于Redis 6.2.6 版本整理总结
一、对象
前面几篇文章,我们介绍了Redis用到的主要的数据结构,如:sds、list、dict、ziplist、skiplist、inset等。
但是,Redis并没有直接使用这些数据结构来实现key-value数据库,而是基于这些数据结构构建了一个对象系统。包括字符串对象、列表对象、哈希对象、集合对象和有序集合对象五种类型的对象。每种对象都使用了至少一种前面提到的数据结构。
通过对对象的区分,Redis可以在执行命令前判断该对象是否能够执行该条命令。为对象设置不同的数据结构实现,只要是为了提高效率。
二、对象的类型及编码
Redis使用对象来表示数据中的key和value,每当我们在Redis数据库中创建一个新的键值对时,至少会创建两个对象,一个作用域key,另一个作用于value。
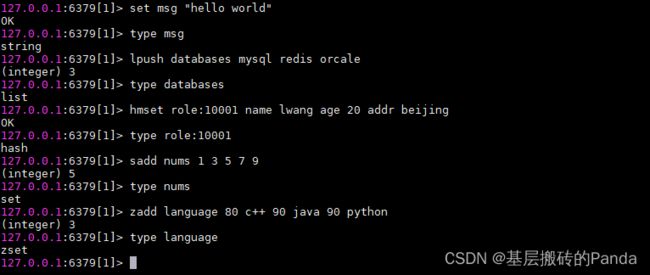
举个栗子:set msg “hello world” 表示分别创建了一个字符串对象保存“msg”,另一个字符串对象保存“hello world”:

redisObject 结构体
Redis中的每个对象由 redisObject 结构体来描述,对象的类型、编码、内存回收、共享对象都需要redisObject的支持,redisObject 结构体定义如下:
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
下面我们来看看每个字段的含义:
(1)type: 占4个比特位,表示对象的类型,有五种类型。当我们执行type命令时,便是通过type字段获取对象的类型。
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
type命令使用示例:
(2)encoding: 占4个比特位,表示对象使用哪种编码,redis会根据不同的场景使用不同的编码,大大提高了redis的灵活性和效率。
字符串对象不同编码类型示例:

(3)lru: 占 24 个比特位,记录该对象最后一次被访问的时间。千万别以为这只能在LRU淘汰策略中才用,LFU也是复用的个字段。当使用LRU时,它保存的上次读写的24位unix时间戳(秒级);使用LFU时,24位会被分为两个部分,16位的分钟级时间戳和8位特殊计数器,这里就不展开了,详细可以注意我后续的文章。
(4)refcount: 对象的引用计数,类似于shared_ptr 智能指针的引用计数,当refcount为0时,释放该对象。
(5)ptr: 指向对象具体的底层实现的数据结构。
三、不同对象编码规则

四、redisObject结构各字段使用范例
Redis中操作key的命令大致可以分为两类:一种是可以操作任何类型的key,如:del type object等等,另外一种是针对特定类型的key只能使用特定的命令。如:LLEN只能用来获取列表对象的长度。
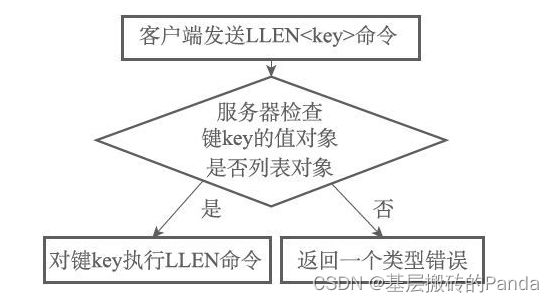
4.1 类型检查(type字段)
比如对于LLEN命令,Redis服务器在执行命令之前会先检查输入的key对应的的value对象是否为列表类型,即检查该value对象的type类型是不是OBJ_LIST,如果是才会执行LLEN命令。否则就拒绝执行命令并返回操作类型错误。
4.2 多态命令的实现(encoding)
Redis除了会根据value对象的类型来判断对应key能否执行执行命令外,还会根据value对象的**编码方式(encoding字段)**选择正确的方式来执行命令。比如:列表对象的编码方式有quicklist 和 ziplist两种,Redis服务器除了判断对应value对象的类型为列表对象还要根据具体的编码选择正确的LLEN执行。
借用面向对象的术语来说,可以认为LLEN命令是多态的。只要执行LLEN命令的列表键,无论value对象的编码是哪种方式,LLEN命令都可以正常执行。实际上del type 等也是多态命令。他们和LLEN的区别在于,前者是基于类型的多态,后者是基于编码的多态。

4.3 内存回收和共享对象(refcount)
C语言不具备自动回收功能,Redis就通过引用计数实现了自己的内存回收机制。具体是由redisObject结构中的refcount字段记录。对象的引用计数会随着对象的使用状态而不断变化。
创建一个新对象时,refcount会被初始化为1,;当对象被另一个新程序使用时 refcount加1;不被一个程序使用时减1;当refcount==0时,该对象所占的空间会被回收。
引用计数除了被用来实现内存回收外,还被用来实现对象共享。比如:
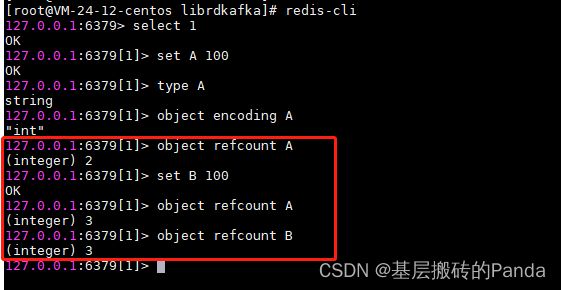
上面我们创建可一个value为100的key A,并使用object refcount来查看key A的引用计数,会看到此时的refcount为2,这是为什么呢?此时有两个地方引用了这个value对象,一个是持有该对象的服务器程序,另外一个是共享该value对象的key A。如果,我们再创建一个value为100 的 key B,那么键B也会指向这个value对象,使得该对象的引用计数变为3。由此,可以看到,共享value对象的键越多,节约的内存就越多。
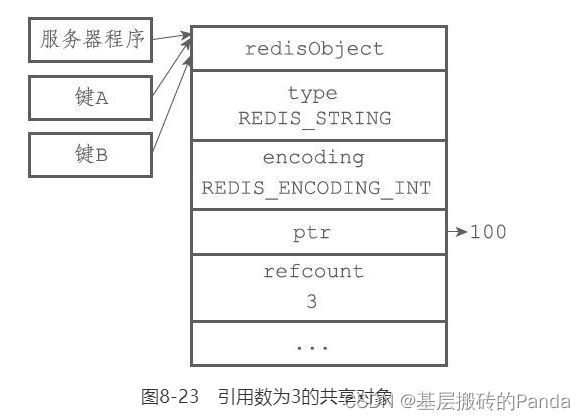
在创建键B的时候,服务器考到键B要创建的对象是int编码的字符串对象100,而刚好有个value为100的共享对象匹配,就直接将键B指向该共享对象。因为是整数的字符串对象,直接比较即可,如果共享对象是字符串值的对象,要从头到尾比较每个字符,时间复杂度O(n)。
简单来说就是,要能使用共享对象,需要先验证该共享对象和要创建的目标对象是不是完全一致,如果共享对象保存的值越复杂,消耗的CPU也就越多,所以Redis值对整数类型的字符串对象做了共享。没有共享保存字符串值的字符串对象。
Redis在初始化服务器是,就创建了一万个字符串对象,这些对象包含了0~9999的所有整数值。当你创建了这个范围内的 字符串对象时,服务器就会使用这些共享对象,而不是创建新对象,以节约内存。
4.4 对象的空转时长(lru)
redisObject结构中的lru字段保存,该对象最后一次被访问的时间。 使用object idletime 来查看,注意这个命令不会修改对象的lru属性。
当Redis开启最大内存限制,一般为机器内存的一半,如果redis使用的内存达到这个值,且内存淘汰策略使用的是volatile-lru 或者 allkeys-lru,空转时长较高的那些键会被优先释放。
使用object idletime 查看键的空间时间,单位:秒:
127.0.0.1:6379[1]> keys *
1) "msg"
2) "teacher"
127.0.0.1:6379[1]> object idletime msg
(integer) 71166
127.0.0.1:6379[1]>
五、对象在源码中的使用
5.1 字符串对象
5.1.1字符串对象创建
// code location: src/object.c
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
// 创建 strintg 对象
robj *createStringObject(const char *ptr, size_t len) {
// 如果待保存的字符串的长度小于等于44,使用 embstr 编码
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else // 否则使用 raw 编码
return createRawStringObject(ptr,len);
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 申请 robj + sdshdr + data + 1 的空间
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING; // 设置类型
o->encoding = OBJ_ENCODING_EMBSTR; // 设置编码
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
从 createEmbeddedStringObject 函数可以看到,该对象是robj和sds的结合体,将sds直接放入到robj里,这也是嵌入式编码embstr的由来。
为什么要限制44字节呢?因为robj结构体占16个字节,sdshdr结构体占3个字节,最后结尾的‘\0’占一个字节,限制44个字节,就能保证64个字节里能放下所有内容(16+3+1+44 = 64)。
5.1.2 字符串对象编码
Redis将节省内存做到了极致,它的作者对字符串对象又做了特殊的编码处理,以进一步达到节省空间的目的。编码处理过程及代码注释如下:
/* Try to encode a string object in order to save space */
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
/* Make sure this is a string object, the only type we encode
* in this function. Other types use encoded memory efficient
* representations but are handled by the commands implementing
* the type. */
// 这里只对string对象进行编码,其他类型的编码都有对应的具体实现处理
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
/* We try some specialized encoding only for objects that are
* RAW or EMBSTR encoded, in other words objects that are still
* in represented by an actually array of chars. */
// 非sds string对象,直接返回原对象
if (!sdsEncodedObject(o)) return o;
/* It's not safe to encode shared objects: shared objects can be shared
* everywhere in the "object space" of Redis and may end in places where
* they are not handled. We handle them only as values in the keyspace. */
// 如果该对象由其他对象共享,不能编码,如果编码可能影响到其他对象的使用
if (o->refcount > 1) return o;
/* Check if we can represent this string as a long integer.
* Note that we are sure that a string larger than 20 chars is not
* representable as a 32 nor 64 bit integer. */
// 检查能否把一个字符串表示为长整型数,长度要小于等于20
len = sdslen(s);
if (len <= 20 && string2l(s,len,&value)) {
/* This object is encodable as a long. Try to use a shared object.
* Note that we avoid using shared integers when maxmemory is used
* because every object needs to have a private LRU field for the LRU
* algorithm to work well. */
// 如果可以被编码为long型,且编码后的值小于OBJ_SHARED_INTEGERS(10000),且未配
// 置LRU替换淘汰策略, 就使用这个数的共享对象,相当于所有小于10000的数都是用的同一个robj
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
// 不能转为long的字符串
/* If the string is small and is still RAW encoded,
* try the EMBSTR encoding which is more efficient.
* In this representation the object and the SDS string are allocated
* in the same chunk of memory to save space and cache misses. */
// 如果字符串的长度太小,小于等于44
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
// 如果当前编码是embstr,直接返回原对象,否则转为embstr编码,返回
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/* We can't encode the object...
*
* Do the last try, and at least optimize the SDS string inside
* the string object to require little space, in case there
* is more than 10% of free space at the end of the SDS string.
*
* We do that only for relatively large strings as this branch
* is only entered if the length of the string is greater than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT. */
// 如果前面编码没有成功,这里做最后一步,当编码类型为raw,且它的sds可用空间超过10%,
// 尝试释放调这部分内存
trimStringObjectIfNeeded(o);
/* Return the original object. */
// 返回原对象
return o;
}
5.1.3 字符串对象解码
有编码就有解码,实际上只需要那些可以转为整型类型的字符串传进行解码,解码代码及注释如下:
robj *getDecodedObject(robj *o) {
robj *dec;
// 如果编码是 embstr 和 raw ,只是把引用计数加一,然后返回原对象
if (sdsEncodedObject(o)) {
incrRefCount(o);
return o;
}
// 如果编码是 int 进行解码,返回新的对象
if (o->type == OBJ_STRING && o->encoding == OBJ_ENCODING_INT) {
char buf[32];
ll2string(buf,32,(long)o->ptr);
dec = createStringObject(buf,strlen(buf));
return dec;
} else {
serverPanic("Unknown encoding type");
}
}
5.1.4 redis对象引用计数及自动清理
void incrRefCount(robj *o) {
if (o->refcount < OBJ_FIRST_SPECIAL_REFCOUNT) {
o->refcount++; // 引用计数加一
} else {
if (o->refcount == OBJ_SHARED_REFCOUNT) {
/* Nothing to do: this refcount is immutable. */
} else if (o->refcount == OBJ_STATIC_REFCOUNT) {
serverPanic("You tried to retain an object allocated in the stack");
}
}
}
// 减少引用计数
void decrRefCount(robj *o) {
// 释放空间
if (o->refcount == 1) {
switch(o->type) {
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
case OBJ_MODULE: freeModuleObject(o); break;
case OBJ_STREAM: freeStreamObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o);
} else {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--; // 计数减一
}
}
六、总结
- redis对象为所有类型的value提供了统一的封装
- 为对象的淘汰策略保存相关信息
- 实现引用计数及内存自动释放功能
文章参考与<零声教育>的C/C++linux服务期高级架构系统教程学习