机器学习(聚类分析模型应用)
用K-means算法解决实际应用问题
1.读取数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
datas=pd.read_excel("./data/business_circle.xls")
datas.head()2.清理数据,将异常值清洗
def abnormalIndex(data):
abnIndex=pd.Series().index
for col in data.columns:
s=data[col]
a=s.describe()
high=a['75%']+(a['75%']-a['25%'])*1.5
low=a['25%']-(a['75%']-a['25%'])*1.5
abn=s[(s>high)|(sdata=data.drop(abnormalIndex(data))
data.shape删除后的数据打印出来

3.数据归一化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
data_std=std.fit_transform(data)
data 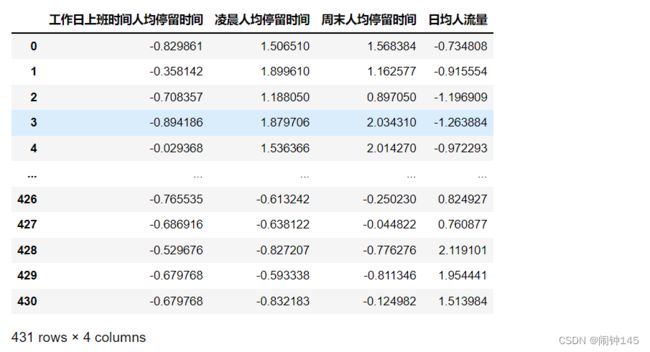
方便之后的可视化画图
4.K-means模型训练
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 3, n_jobs = 4, max_iter = 500) #分为k类,并发数4
model.fit(data_std) #开始聚类5.内部评估
轮廓系数:
from sklearn.metrics import silhouette_score #轮廓系数,[-1,1]
print(silhouette_score(data_std, model.labels_)CH分数:
from sklearn.metrics import calinski_harabaz_score #CH分数越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果
print(calinski_harabaz_score(data_std, model.labels_))6.最后可视化分析
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(data_std) #进行数据降维
df=pd.DataFrame(data=tsne.embedding_,columns=['x','y'])
df['type']=model.labels_
# df.head()
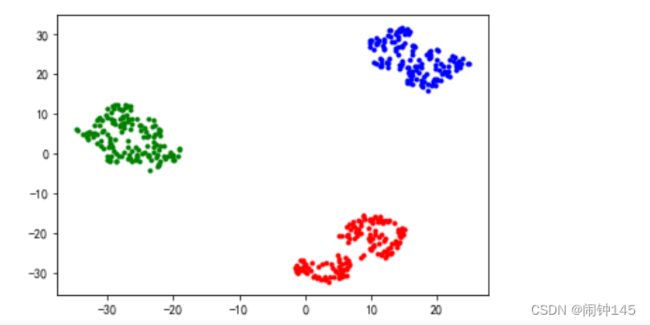
#二维图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#不同类别用不同颜色和样式绘图
d=df[df.type==0]
plt.plot(d.x,d.y ,'r.')
d=df[df.type==1]
plt.plot(d.x,d.y ,'g.')
d=df[df.type==2]
plt.plot(d.x,d.y ,'b.')
plt.show()二维图结果:
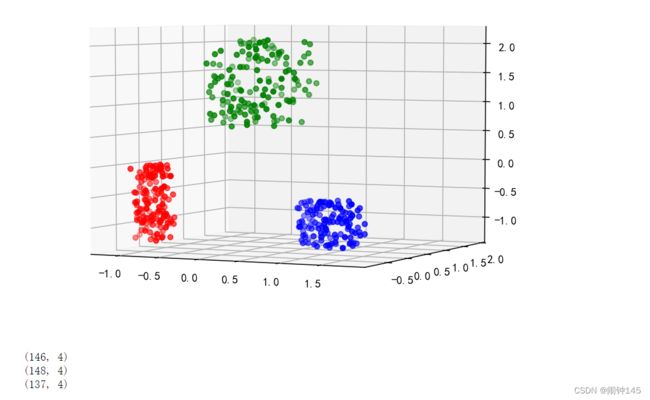
*7.再简单介绍一下三维图
%matplotlib notebook
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
d=data_std[df.type==0]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='r')
d=data_std[df.type==1]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='g')
d=data_std[df.type==2]
print(d.shape)
ax.scatter(d[:,0],d[:,1],d[:,2], c='b')
plt.show()把type==0,1,2的结果分别聚类,然后展现出来