关键点检测——HrNet网络结构搭建
参考视频讲解如下:
【HRNet源码解析(Pytorch)】 https://www.bilibili.com/video/BV1ar4y157JM?p=2&share_source=copy_web&vd_source=95705b32f23f70b32dfa1721628d5874
import torch.nn as nn
BN_MOMENTUM = 0.1
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
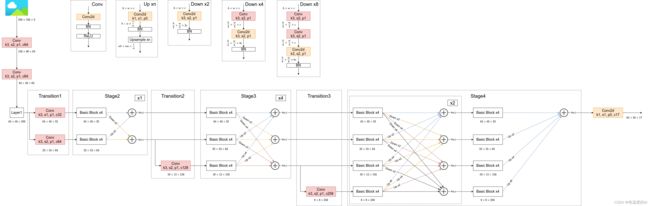
class StageModule(nn.Module):
def __init__(self, input_branches, output_branches, c):
"""
构建对应stage,即用来融合不同尺度的实现
:param input_branches: 输入的分支数,每个分支对应一种尺度
:param output_branches: 输出的分支数
:param c: 输入的第一个分支通道数
"""
super().__init__()
self.input_branches = input_branches
self.output_branches = output_branches
self.branches = nn.ModuleList() #用于存储每个分支中所用到的一系列BasicBlock
for i in range(self.input_branches): # 每个分支上都先通过4个BasicBlock
w = c * (2 ** i) # 对应第i个分支的通道数
branch = nn.Sequential(
BasicBlock(w, w),
BasicBlock(w, w),
BasicBlock(w, w),
BasicBlock(w, w)
)
self.branches.append(branch)
self.fuse_layers = nn.ModuleList() # 用于融合每个分支上的输出
for i in range(self.output_branches):
self.fuse_layers.append(nn.ModuleList()) #对每一个输出分支初始化一个ModuleList()
for j in range(self.input_branches): #遍历input_branches次
if i == j:
# 当输入、输出为同一个分支时不做任何处理
self.fuse_layers[-1].append(nn.Identity())
elif i < j: #需要进行上采样
# 当输入分支j大于输出分支i时(即输入分支下采样率大于输出分支下采样率),
# 此时需要对输入分支j进行通道调整以及上采样,方便后续相加
self.fuse_layers[-1].append( #在ModuleList()中添加一个nn.Sequential
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** i), kernel_size=1, stride=1, bias=False), #通道收缩
nn.BatchNorm2d(c * (2 ** i), momentum=BN_MOMENTUM),
nn.Upsample(scale_factor=2.0 ** (j - i), mode='nearest') #进行2,4,8倍的上采样
)
)
else: # i > j
# 当输入分支j小于输出分支i时(即输入分支下采样率小于输出分支下采样率),
# 此时需要对输入分支j进行通道调整以及下采样,方便后续相加
# 注意,这里每次下采样2x都是通过一个3x3卷积层实现的,4x就是两个,8x就是三个,总共i-j个
ops = []
# 前i-j-1个卷积层不用变通道,只进行下采样
# 下采样模块中有几个红色的Conv,红色的Conv只改变特征图大小,不改变通道数;黄色的Conv特征图大小和通道数都改变
for k in range(i - j - 1): #i-j-1即为下采样中对应的红色的Conv数,可能有0,1,2个,所有需要循环
ops.append(
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** j), kernel_size=3, stride=2, padding=1, bias=False), #通道数不变
nn.BatchNorm2d(c * (2 ** j), momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
# 最后一个卷积层不仅要调整通道,还要进行下采样,只有一个,不需要循环
ops.append(
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** i), kernel_size=3, stride=2, padding=1, bias=False), #通道数加倍
nn.BatchNorm2d(c * (2 ** i), momentum=BN_MOMENTUM)
)
)
self.fuse_layers[-1].append(nn.Sequential(*ops))
self.relu = nn.ReLU(inplace=True) #Add后需要接一个relu
def forward(self, x):
# 每个分支通过对应的block
x = [branch(xi) for branch, xi in zip(self.branches, x)] #将对应分支的输入,输入到对应的branch分支中
# 接着融合不同尺寸信息
x_fused = []
for i in range(len(self.fuse_layers)): #循环得到第i个分支的输出
x_fused.append(
self.relu(
# 将x[j]输入到fuse_layers[0][0]、fuse_layers[0][1].......,再将输出分支进行sum求和,然后在经过relu,添加到x_fused中
sum([self.fuse_layers[i][j](x[j]) for j in range(len(self.branches))])
)
)
return x_fused
#Hrnet
class HighResolutionNet(nn.Module):
def __init__(self, base_channel: int = 32, num_joints: int = 17):
super().__init__()
# Stem
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
self.transition1 = nn.ModuleList([
nn.Sequential(
nn.Conv2d(256, base_channel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(base_channel, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
),
nn.Sequential(
nn.Sequential( # 这里又使用一次Sequential是为了适配原项目中提供的权重
nn.Conv2d(256, base_channel * 2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 2, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage2
self.stage2 = nn.Sequential(
StageModule(input_branches=2, output_branches=2, c=base_channel)
)
# transition2
self.transition2 = nn.ModuleList([
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Sequential(
nn.Sequential(
nn.Conv2d(base_channel * 2, base_channel * 4, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 4, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage3 包含4个StageModule
self.stage3 = nn.Sequential(
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel)
)
# transition3
self.transition3 = nn.ModuleList([
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Sequential(
nn.Sequential(
nn.Conv2d(base_channel * 4, base_channel * 8, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 8, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage4 包含3个StageModule
# 注意,最后一个StageModule只输出分辨率最高的特征层
self.stage4 = nn.Sequential(
StageModule(input_branches=4, output_branches=4, c=base_channel),
StageModule(input_branches=4, output_branches=4, c=base_channel),
StageModule(input_branches=4, output_branches=1, c=base_channel)
)
# Final layer
self.final_layer = nn.Conv2d(base_channel, num_joints, kernel_size=1, stride=1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
# x是一个列表
x = [trans(x) for trans in self.transition1] # Since now, x is a list
# x = [
# self.transition1[0](x),
# self.transition1[1](x),
# ]
x = self.stage2(x)
x = [
self.transition2[0](x[0]),
self.transition2[1](x[1]),
self.transition2[2](x[-1]) #这里的x[-1]其实就是x[1]
] # New branch derives from the "upper" branch only
x = self.stage3(x)
x = [
self.transition3[0](x[0]),
self.transition3[1](x[1]),
self.transition3[2](x[2]),
self.transition3[3](x[-1]), #这里的x[-1]其实就是x[2]
] # New branch derives from the "upper" branch only
x = self.stage4(x)
x = self.final_layer(x[0]) #stage4(x)只有一个输出,但x是一个列表,故用x[0]
return x
reference
【HRNet源码解析(Pytorch)】 https://www.bilibili.com/video/BV1ar4y157JM?p=2&share_source=copy_web&vd_source=95705b32f23f70b32dfa1721628d5874