kaggle泰坦尼克号生存预测eda和pytorch全连接神经网络分类
PS:这是一个入门学习赛,我也没太认真做,还有很多可以改进的空间。
# 数据分析
import pandas as pd
import numpy as np
import random as rnd
from tqdm.notebook import tqdm
# 数据可视化
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 机器学习模型
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
加载数据
train_data = pd.read_csv('C:/ml_data/titanic/train.csv')
test_data = pd.read_csv('C:/ml_data/titanic/test.csv')
train_data.head(1)

特征含义:
PassengerId:乘客ID
Pclass: packet class 船票等级,1st 一等舱 2st 二等舱 3st 三等舱
Name: 乘客姓名
Sex: 乘客性别
Age: 乘客年龄
SibSp: 有几个siblings(兄弟姐妹) or spouses(配偶) 在船上
parch: 有几个parents or children 在船上
ticket: ticket number
fare: 船票价格
cabin: 船舱号
embarked: 登船位置 C Q S 三个港口
目标:
survived: 是否存活
特征删除
乘客的id和船票id直接删除,这两个特征没有意义。
del train_data['PassengerId']
del train_data['Ticket']
del test_data['Ticket']
del test_data['PassengerId']
缺失值处理
train_data.isnull().sum()/len(train_data)*100
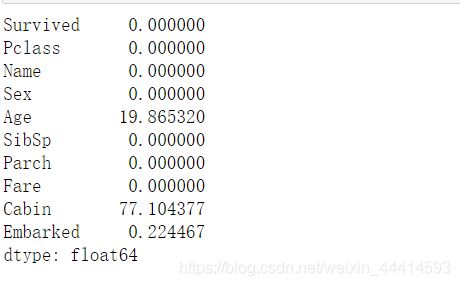
test_data.isnull().sum()/len(test_data)*100

特征Cabin缺失值达到了78%,所以该特征直接删除吧。
del train_data['Cabin']
del test_data['Cabin']
Embarked(上船的岸)缺失值较少,进行填充。这里使用所有数据的众数进行填充。因为无法分析出Embarked和其他的特征有什么联系。
freq_port = train_data['Embarked'].dropna().mode()[0]
train_data['Embarked'] = train_data['Embarked'].fillna(freq_port)
test_data['Embarked'] = test_data['Embarked'].fillna(freq_port)
其实应该使用所有数据的众数进行填充,本例中训练数据的众数和所有数据的众数一样。
Age缺失值较多,达到了20%左右,可以考虑删除,也可以进行填充。这里先进行填充。Age填充时不能直接使用所有数据的mean或者median等进行填充,因为偏差较大,所以需要进行分析哪些特征会影响Age。
train_data[['Sex', 'Age']].groupby(['Sex'], as_index=False).mean().sort_values(by='Age', ascending=False)
train_data[['Pclass', 'Age']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Age', ascending=False)
train_data[['Embarked', 'Age']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Age', ascending=False)
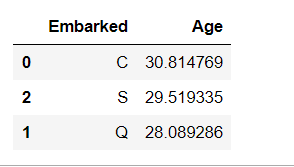
暂时看来Sex,Pclass,Embarked都会对Age造成影响。(其他特征也有影响,例如target:survied等,也应该对其他特征进行分析)。这里我就仅仅使用Sex,Pclass这二个特征进行填充了,毕竟这是一个学习赛。
首先需要进行
类别特征序号编码
dataset = [train_data,test_data]
for dataset in combine_data:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
all_data = pd.concat([train_data,test_data], axis=0)
Sex缺失值填充
guess_ages = np.zeros((2,3))
for i in range(0,2):
for j in range(0,3):
temp_data = all_data[(all_data['Sex'] == i) & (all_data['Pclass'] == j + 1)]['Age'].dropna()
guess_ages[i][j] = temp_data.mean()
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
测试集fare填充
查看缺失值那一行的数据情况。
test_data[test_data['Fare'].isnull()]

根据分析,对fare(船票价格)造成影响的特征有Pclass,Embarked。所以根据这两个特征进行缺失值填充。PS:其实其他特征一会存在影响,这里不进行深入的探讨了。
test_fare_miss_value = all_data[(all_data.Pclass == 3) & all_data.Embarked == 0]['Fare'].dropna().mean()
test_data['Fare'] = test_data['Fare'].fillna(test_fare_miss_value)
新增特征 Title
Title是根据name中得出的,例如Kelly, Mr. James
for dataset in combine_data:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_data['Title'], train_data['Sex'])
for data_single in combine_data:
data_single['Title'] = data_single['Title'].replace(['Capt','Col','Countess','Don','Dr',\
'Jonkheer','Major','Mme','Rev'],'Rare')
data_single['Title'] = data_single['Title'].replace(['Sir'],'Mr')
data_single['Title'] = data_single['Title'].replace(['Mrs','Ms','Lady','Mlle'],'Miss')
pd.crosstab(train_data['Title'], train_data['Survived'])
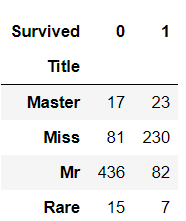
可以看出Title很有用的,但是Title存在一个隐形问题,title中的mr和miss其实和性别重复了。
对title进行序号编码
title_mapping = {"Master": 1, "Miss": 2, "Mr": 3, "Rare": 4, }
for dataset in combine_data:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_data.head()
新增特征familysize
因为初始特征中的兄弟数量和父母孩子数量,构造新的特征familysize。
for dataset in combine_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
新增特征 Isalone
即familysize == 0
for data_single in combine_data:
data_single['IsAlone'] = 0
data_single.loc[data_single['FamilySize'] == 1, 'IsAlone'] = 1
train_data[['IsAlone','Survived']].groupby('IsAlone').mean()
del train_data['SibSp']
del train_data['Parch']
del test_data['SibSp']
del test_data['Parch']
连续值分桶
for data_set in combine_data:
data_set.loc[data_set['Age'] <= 16,'Age'] = 0
data_set.loc[(data_set['Age'] > 16) & (data_set['Age'] <= 32),'Age'] = 1
data_set.loc[(data_set['Age'] > 32) & (data_set['Age'] <= 48),'Age'] = 2
data_set.loc[(data_set['Age'] > 48) & (data_set['Age'] <= 64),'Age'] = 3
data_set.loc[data_set['Age'] >64,'Age'] = 4
也可以使用pandas中的cut和qcut
train_data['Fareband'] = pd.qcut(train_data['Fare'],4)
test_data['Fareband'] = pd.qcut(test_data['Fare'],4)
for dataset in combine_data:
dataset.loc[dataset['Fare'] < 7.91,'Fare']=0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] < 14.454),'Fare']=1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] < 31.0),'Fare']=2
dataset.loc[dataset['Fare'] >= 31.0,'Fare']=3
新增特征AC
即Age+Class,其实最好再加上Sex,因为Sex对生存的影响很大。我做这个竞赛的时候还不太懂。
for data_set in combine_data:
data_set['AC'] = data_set.Age * 3 + data_set.Pclass
保存数据
del train_data['Fareband']
del test_data['Fareband']
train_data.to_csv('C:/ml_data/titanic/train_data.csv',index = False)
test_data.to_csv('C:/ml_data/titanic/test_data.csv',index = False)
神经网络
引用
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
from torch.utils.data import DataLoader as DataLoader
数据读取
train_data = pd.read_csv('data/titanic/train_data.csv')
test_data = pd.read_csv('data/titanic/test_data.csv')
训练接,验证集划分
train_y = train_data['Survived'][0:712].values
valid_y = train_data['Survived'][712:891].values
train_x = train_data.drop('Survived',axis = 1)
test_x = test_data.values
all_data = pd.concat([train_x,test_x],axis = 0).reset_index()
线性关系的特征归一化,非线性关心的类别特征做onehot
all_x_Linear= all_data[['Age','Fare']]
all_x_non_Linear= all_data[['Pclass','Sex','Embarked','Title','IsAlone','AC']]
for i in all_x_Linear.columns:
all_x_Linear[i] = (all_x_Linear[i] - np.min(all_x_Linear[i])) / (np.max(all_x_Linear[i]) - np.min(all_x_Linear[i]))
all_x_non_Linear['Title'] = all_x_non_Linear['Title'].astype(int)
for i in all_x_non_Linear.columns:
all_x_non_Linear[i] = all_x_non_Linear[i].astype(str)
all_x_non_Linear = pd.get_dummies(all_x_non_Linear)
all_data = pd.concat([all_x_Linear, all_x_non_Linear],axis = 1)
train_x = all_data[0:891][0:712].values
valid_x = all_data[0:891][712:891].values
test_x = all_data[891:len(all_data)].values
train_x_all = all_data.values
train_y_all = train_data['Survived'].values
全连接神经网络
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(32,64)
self.fc2 = nn.Linear(64,32)
self.fc3 = nn.Linear(32,2)
def forward(self,x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.sigmoid(x)
return F.softmax(x,dim = 1)
loss函数和优化方法
#本例中类别稍微有点不平衡,Loss函数中可以加点权重。
fc_nn = Net().cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(fc_nn.parameters())
验证函数
def valid(model, valid_x_func, valid_y_func):
valid_y_func = torch.tensor(valid_y_func,dtype = torch.long).to('cuda:0')
valid_x_func = torch.tensor(valid_x_func,dtype = torch.float32).to('cuda:0')
outputs = model(valid_x_func)
loss = criterion(outputs,valid_y_func)
total = len(valid_y_func)
correct = 0
outputs_ = []
for item in outputs:
if item[0].item() > item[1].item():
outputs_.append(0)
else:
outputs_.append(1)
for i in range(len(valid_y_func)):
if outputs_[i] == valid_y_func[i]:
correct += 1
return loss.item(), correct, total
保存训练中的loss等数据
epoch_mean_loss_gather = []
epoch_single_loss_gather = []
epoch_valid_loss_gather = []
epoch_valid_acc_gather = []
训练函数
def train(model, train_x_func, train_y_func, criterion, optimizer, epochs, batch_size):
if len(train_y_func) % batch_size == 0:
not_ed = 0
else:
not_ed = 1
for epoch in range(epochs):
total_loss = 0
for iter in range(int(len(train_y_func)/batch_size)+not_ed):
start = iter * batch_size
if iter == (int(len(train_y_func)/batch_size)+not_ed) - 1:
end = min((iter + 1)* batch_size, len(train_y_func))
else:
end = (iter + 1)* batch_size
train_x_ = torch.tensor(train_x_func[start:end],dtype = torch.float32).to('cuda:0')
train_y_ = torch.tensor(train_y_func[start:end],dtype = torch.long).to('cuda:0')
outputs = model(train_x_)
loss = criterion(outputs,train_y_)
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
epoch_single_loss_gather.append(loss.item())
valid_loss, valid_correct,valid_total = valid(model, valid_x,valid_y)
if epoch % 100 == 0:
print('Epoch: {0} train_data mean_loss: '.format(epoch),total_loss/(int(len(train_y_func)/batch_size)+not_ed))
print('Epoch: {0} valid_data mean_loss: '.format(epoch),valid_loss)
print('Epoch: {0} valid_data acc: '.format(epoch),(valid_correct/valid_total)*100)
epoch_mean_loss_gather.append(total_loss/(int(len(train_y_func)/batch_size)+not_ed))
epoch_valid_loss_gather.append(valid_loss)
epoch_valid_acc_gather.append((valid_correct/valid_total)*100)
print('-----------------------------')
训练
训练deepoch数量227验证集验证出来的,验证过程略去。
train(fc_nn, train_x_all, train_y_all, criterion, optimizer, 227, 32)
结果保存和提交
单神经网络得分0.77左右。
test_x = torch.tensor(test_x,dtype = torch.float32).to('cuda:0')
pred_y = fc_nn(test_x)
result = []
for item in pred_y:
if item[0].item() > item[1].item():
result.append(0)
else:
result.append(1)
sub = pd.read_csv('data/titanic/gender_submission.csv')
sub['Survived'] = result
sub.to_csv('data/titanic/result_fcnn_1.csv',index = False)
改进
1.eda总觉得可以再改改。
2.神经网络的结果应该一个再复杂一些,因为现在的神经网络基本没有过拟合,说明拟合能力应该不够。
3.loss函数应该处理一下类别不平衡问题。
4.试试过采样做数据增强。