贝叶斯算法
贝叶斯算法
贝叶斯算法是机器学习中一个重要分支,在较小的数据集中分类效果非常好,而且它的原理也比较简单。
贝叶斯算法基础知识:
贝叶斯算法的基础知识主要是概率论,比如概率、条件概率、联合概率等。
贝叶斯定理:
P(A|B) = P(A)P(B|A) / P(B)
import pandas as pd
docuts = [["菜品","很","一般","不","建议","在这","消费"],
["老板","很","闹心","坑人","建议","去","别家"],
["让人","惊艳","东西","口味","让人","感觉","不错"],
["环境","不错","孜然牛柳","很","好吃"],
["味道","真的","一般","环境","也","比较","拥挤"],
["一家","性价比","很","高","餐厅","推荐"]]
classVec = [1,1,0,0,1,0]

#创建计数函数
def creat_wordall(doucts):
word_all = set()
for douct in doucts:
word_all = word_all | set(douct) #|是并集
word_all = list(word_all)
return word_all
#计算出现的词语
all_words = creat_wordall(docuts)
all_words

#创建词向量函数
def create_wordVec(douct,all_words):
dic = {}
for word in all_words:
if word in douct:
dic[word] = 1
else:
dic[word] = 0
return dic
#创建训练矩阵
trainmatrix = []
for i in docuts:
trainmatrix.append(create_wordVec(i,all_words))
trainmatrix

#将矩阵转化为数据框
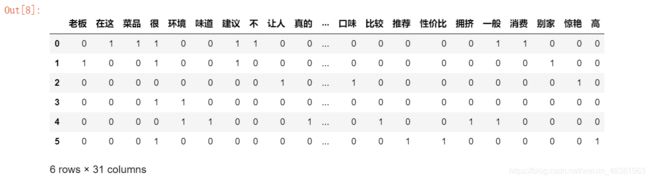
df = pd.DataFrame(trainmatrix)
df
#将标签转化为序列
se = pd.Series(classVec)
se

提取消极词
#取消极词语的数据
df_neg = df[se == 1]
df_neg

#计算出消极词语出现的次数
p_negwordnum = df_neg.sum()
#计算消极词语的总数
p_negallnum = p_negwordnum.sum()
#计算消极词语的条件概率
p_negvect = p_negwordnum/p_negallnum
#计算消极文档出现的概率
p_negdoc = len(df_neg)/len(df)
提取积极词
#取积极词语的数据
df_pos = df[se==0]
df_pos

#计算积极词语出现的总数数
p_poswordnum = df_pos.sum()
#计算积极词语出现的总数数
p_posallnum = p_poswordnum.sum()
#计算积极词语的条件概率
p_posvect = p_poswordnum/p_posallnum
#计算消极文档出现的概率
p_posdoc = len(df_pos)/len(df)
创建测试文章
#创建测试文章
testdoc = ["环境","很","不错"]
找出消极文章词语的条件概率
#找出消极文章词语的条件概率
p_negcurvect = p_negvect[testdoc]
p_negcurvect

计算总概率
#计算总概率
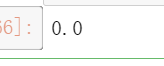
p_negfeatcla = p_negcurvect.prod()
p_negfeatcla
赋值消极文章概率
#赋值消极文章概率
p_negcla = p_negdoc
p_negcla

计算该文章属于消极文章的概率
#计算该文章属于消极文章的概率
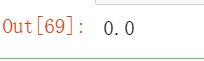
p_negfinal = p_negfeatcla * p_negcla
p_negfinal
计算该文章是积极文章的概率
#计算该文章是积极文章的概率
p_posfeatcla = p_posvect[testdoc].prod()
p_posfeatcla

计算积极文章出现的概率
#计算积极文章出现的概率
p_poscla = 1 - p_negdoc
p_poscla

#计算该文章属于积极文章的概率
p_posfinal = p_posfeatcla * p_poscla
p_posfinal
![]()
所以属于积极文章。
总结:
判断出测试文章是积极文章还是消极文章步骤:
1、分别找出测试文章中的每个词在训练集中相应的积极词语和消极词语的条件概率,再分别求总概率(总概率=每个词语条件概率的乘积)
2、然后分别求出是积极文章还是消极文章的概率(总概率 * 积极文章或消极文章出现的概率)
3、比较大小