孪生神经网络原理介绍
孪生神经网络
定义
孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的。
当我们想要提取同一属性的特征的时候,如果使用两个神经网络分别对图片进行特征提取,提取到的特
征很有可能不在一个分布域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。因此,
孪生神经网络可以提取出两个输入图片同一分布域的特征,此时便可以判断两个输入图片的相似性。
狭义的孪生神经网络由两个结构相同,且权重共享的神经网络拼接而成 。广义的孪生神经网络,或“伪
孪生神经网络”,可由任意两个神经网拼接而成 。可由卷积神经网络、循环神经网络等组成。
过程图解
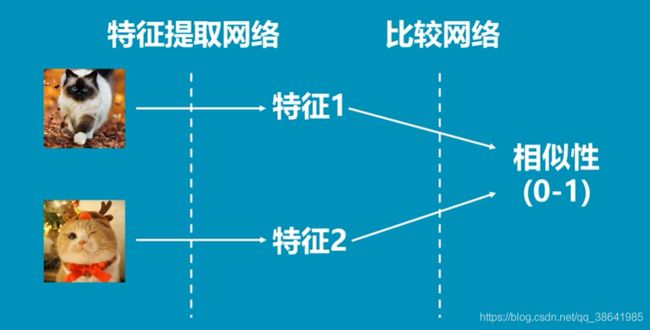
说明: 首先,有两只猫的图片,将形状调整为相同大小作为输入层。
其次,讲两只猫的图片,放入神经网络进行特征提取。神经网络可以是结构相同的两个神经网络
;也可以是一个神经网络。
接着,将多维特征的输入进行一维化转换。
最终,通过计算得到两张图片的相似性。
提示:(当然,必须实现进行模型的训练,讲同类特征进行学习才可以预测相似性)
VGG16 讲解
vgg16结构图
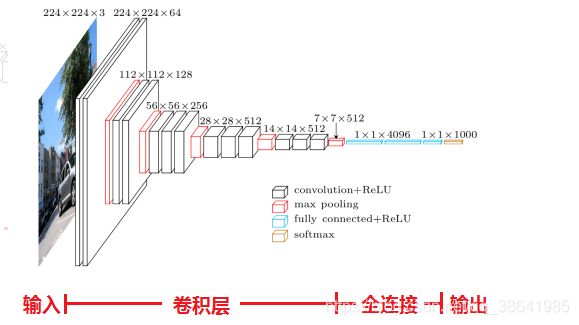
说明: VGG结构由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大池化)分开,
所有隐层的激活单元都采用ReLU函数。

处理过程:
1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
卷积计算

池化计算

基于VGG16的孪生神经网络构建
孪生神经网络结构

说明: 这里借用了VGG16的前五层,完成特征提取后,将特征展开为一维,然后为下一步做准备。
孪生神经网络代码
# 第一个卷积部分
# 105, 105, 3 -> 105, 105, 64 -> 52, 52, 64
self.block1_conv1 = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')
self.block1_conv2 = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv2')
self.block1_pool = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')
# 第二个卷积部分
# 52, 52, 64 -> 52, 52, 128 -> 26, 26, 128
self.block2_conv1 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')
self.block2_conv2 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')
self.block2_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')
# 第三个卷积部分
# 26, 26, 128-> 26, 26, 256 -> 13, 13, 256
self.block3_conv1 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')
self.block3_conv2 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')
self.block3_conv3 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')
self.block3_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')
# 第四个卷积部分
# 13, 13, 256-> 13, 13, 512 -> 6, 6, 512
self.block4_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')
self.block4_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')
self.block4_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')
self.block4_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')
# 第五个卷积部分
# 6, 6, 512-> 6, 6, 512 -> 3, 3, 512
self.block5_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')
self.block5_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')
self.block5_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')
self.block5_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')
# 3*3*512 = 4500 + 90 + 18 = 4608
self.flatten = Flatten(name = 'flatten')
完整代码:https://github.com/bubbliiiing/Siamese-tf2
训练模型准备
环境配置(CUDA配置-GPU加速)
https://blog.csdn.net/m0_37872216/article/details/103136477
版本说明
pip list
Pillow 7.2.0
tensorflow 2.4.1
tensorflow-gpu 2.4.1
matplotlib 3.3.2
numpy 1.19.5
opencv-python 4.1.1.26
命令行参数
import sys
import cv2
def show_pic(img):
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def main():
print("start")
print (sys.argv)
image_1 = sys.argv[1]
image_2 = sys.argv[2]
src = cv2.imread(image_1)
show_pic(src)
print("end")
if __name__ == "__main__":
main()
运行方式

说明: 更加深入学习命令行参数,学习argparse这个模块。tensortflow也内置了命令行参数的API,
很多深度学习代码不能直接运行,需要设置参数,路径等。如果不会写界面,大多需要用到命令行参数。
目录操作
import sys
import os
def root_ope():
current_file = __file__ #获取执行的Python完整文件名,D:\server\root.py 1
print (current_file,"1")
base_name = os.path.basename(current_file) #获取文件名,不包含目录,root.py 2
print (base_name,"2")
current_root = os.path.dirname(__file__) #获取当前文件的上级(父)目录,D:\server 3
print (current_root,"3")
current_up = os.path.dirname(current_root) #获取当前文件的上级目录,D:\ 4
print (current_up,"4")
file_list = os.listdir(current_root) #获取此目录下的所有文件及目录,返回列表,['a.png', 'a1.png', ..... ] 5
print (file_list,"5")
file_root1 = os.path.join(current_root,file_list[0]) #拼接目录,D:\server\a.png 6
file_root2 = current_root+"\\"+file_list[0] #拼接目录,D:\server\a.png 7
print (file_root1,"6")
print (file_root2,"7")
replace_file_root1 = file_root1 .replace("\\","/") #替换字符,D:/server/a.png 8
print (replace_file_root1,"8")
split_file_root1 = file_root1.split("\\") #根据字符分离字符串,['D:', 'server', 'a.png'] 9
print (split_file_root1,"9")
split_file_root2 = file_root1.split(".") #根据字符分离字符串,['D:\\server\\a', 'png'] 10
print (split_file_root2,"10")
child_name_ext = os.path.splitext(file_root1) #获取文件后缀名,('D:\\server\\a', '.png') 11
print (child_name_ext,"11")
def getListFiles(path):
"""
遍历目录下的所有文件,包含所有层级目录,os.walk类似于一个迭代器。
"""
print(type(os.walk(path)))
ret = []
for root, dirs, files in os.walk(path):
#print (root,dirs)
for filespath in files:
#print(os.path.join(root,filespath))
ret.append(os.path.join(root,filespath))
return ret
def main():
root_ope()
file = getListFiles("D:/server/pic_xiangsi")
print ("file_counter:",len(file))
if __name__ == "__main__":
main()
os.walk

运行 for (root, dirs, files) in os.walk(‘a’):
#第一次运行时,当前遍历目录为 a
所以 root == ‘a’
dirs == [ ‘b’, ‘c’, ‘d’]
files == [ ‘4.txt’, ‘5.txt’]
#接着遍历 dirs 中的每一个目录
b: root = ‘a\b’
dirs = []
files = [ ‘1.txt’, ‘2.txt’]
#dirs为空,返回
# 遍历c
c: root = ‘a\c’
dirs = []
files = [ ‘3.txt’ ]
#遍历d
d: root = ‘a\b’
dirs = []
files = []
遍历完毕,退出循环
说明: 深度学习,图像处理,目标检测,神经网络等操作时需要对文件进行处理,都要求掌握基本的目录、
文件处理以及文件的基本能力。
文件操作
import sys
import cv2
import os
import csv
import json
import xml
import random
import pandas as pd
import xml.etree.ElementTree as ET
from xml.dom import minidom
from xml.dom.minidom import parse
"""
此外文件读写还可以写成这种形式,更加简洁,方便,会自动关闭文件。
with open("text.txt","w") as f:
f.write("data")
with open("text.txt","r") as f:
data = f.read()
data = f.readlines()
json.dumps(test_dict) #将数据转化为字符串
## type print (type(120))
## help print (help(json))
## dir print (dir(json))
"""
"""
0001.xml
pic
0001
E:\Download\object_detection_training\object_detection\dataset\pic\0001.jpg
Unknown
356
240
3
0
"""
def file_read(filename):
f = open(filename,"r")
data = f.read()
print (data)
f.close()
return data
def file_write(filename,data):
f = open(filename,"w")
f.write(data)
f.close()
def list_line_write(filename,list):
f = open(filename,"w")
for i,data in enumerate(list):
f.write(str(data)+"\n")
f.close()
def list_line_read(filename):
f = open(filename,"r")
list = f.readlines()
for i,data in enumerate(list):
print (i,data)
f.close()
return list
def json_read(filename):
with open(filename,"r") as f:
data = json.load(f)
return data
def json_write(filename,data):
with open(filename,"w") as f:
json.dump(data,f,indent = 4)
def csv_read(filename):
all_list = []
with open(filename) as f:
f_csv = csv.reader(f)
for i,row in enumerate(f_csv):
all_list.append(row)
return all_list
def csv_write(filename,data):
column_name = ['1', '2', '3', '4', '5', '6', '7', '8','9','10','11', '12', '13', '14', '1', '16', '17', '18','19','20']
data_pd = pd.DataFrame(data, columns=column_name)
data_pd.to_csv(filename, index=None)
def xml_read(filename):
xml_list = []
tree = ET.parse(filename)
root = tree.getroot()
for member in root.findall('object'):
value = (
root.find('filename').text,
int(root.find('size').find("width").text),
int(root.find('size').find("height").text),
member.find("name").text,
int(member.find("bndbox")[0].text),
int(member.find("bndbox")[1].text),
int(member.find("bndbox")[2].text),
int(member.find("bndbox")[3].text)
)
xml_list.append(value)
return xml_list
def xml_write(filename,data):
#xml_obj = minidom.getDOMImplementation()
#doc = xml_obj.createDocument(None, None, None)
doc = minidom.Document()
xmemlElement = doc.createElement('annotation')
doc.appendChild(xmemlElement)
filename_element = doc.createElement('filename')
filename_text = doc.createTextNode(data[0][0])
filename_element.appendChild(filename_text)
xmemlElement.appendChild(filename_element)
size_element = doc.createElement('size')
size_element_width = doc.createElement("width")
size_element_height = doc.createElement("height")
size_element_width_text = doc.createTextNode(str(data[0][2]))
size_element_height_text = doc.createTextNode(str(data[0][1]))
size_element_width.appendChild(size_element_width_text)
size_element_height.appendChild(size_element_height_text)
size_element.appendChild(size_element_width)
size_element.appendChild(size_element_height)
xmemlElement.appendChild(size_element)
object_element = doc.createElement('object')
object_element_name = doc.createElement("name")
object_element_name_text = doc.createTextNode(data[0][3])
object_element_bndbox = doc.createElement("bndbox")
object_element_bndbox_xmin = doc.createElement("xmin")
object_element_bndbox_ymin = doc.createElement("ymin")
object_element_bndbox_xmax = doc.createElement("xmax")
object_element_bndbox_ymax = doc.createElement("ymax")
object_element_bndbox.appendChild(object_element_bndbox_xmin)
object_element_bndbox.appendChild(object_element_bndbox_ymin)
object_element_bndbox.appendChild(object_element_bndbox_xmax)
object_element_bndbox.appendChild(object_element_bndbox_ymax)
object_element_bndbox_xmin_text = doc.createTextNode(str(data[0][4]))
object_element_bndbox_ymin_text = doc.createTextNode(str(data[0][5]))
object_element_bndbox_xmax_text = doc.createTextNode(str(data[0][6]))
object_element_bndbox_ymax_text = doc.createTextNode(str(data[0][7]))
object_element_bndbox_xmin.appendChild(object_element_bndbox_xmin_text)
object_element_bndbox_ymin.appendChild(object_element_bndbox_ymin_text)
object_element_bndbox_xmax.appendChild(object_element_bndbox_xmax_text)
object_element_bndbox_ymax.appendChild(object_element_bndbox_ymax_text)
object_element_name.appendChild(object_element_name_text)
object_element.appendChild(object_element_name)
object_element.appendChild(object_element_bndbox)
xmemlElement.appendChild(object_element)
with open(filename,"w") as f:
doc.writexml(f, indent='\t', addindent='\t', newl='\n', encoding="utf-8")
def create_list():
list_all = []
for i in range(10):
list = []
for j in range(20):
list.append(random.randint(0,20))
list_all.append(list)
return list_all
def create_dict():
dict_all = {}
for i in range(10):
list = []
for j in range(20):
list.append(random.randint(0,20))
dict_all[str(i)] = list
return dict_all
def main():
print ("satrt".center(30,"-"))
list_data = create_list()
#print (list_data)
dict_data = create_dict()
#print (dict_data)
file_write("list.txt",str(list_data))
file_read("list.txt")
list_line_write("list_lines.txt",list_data)
list_line_read("list_lines.txt")
json_write("dict_data.json",dict_data)
json_write("list_data.json",list_data)
list_data = json_read("list_data.json")
#print (list_data)
dict_data = json_read("dict_data.json")
#print (dict_data)
csv_write("list_data.csv",list_data )
list_data = csv_read("list_data.csv")
#print (list_data)
xml_data = xml_read("0001.xml")
print (xml_data)
xml_write("new.xml",xml_data)
print ("end".center(30,"-"))
if __name__ == "__main__":
main()
说明:
深度学习,图像处理,目标检测,神经网络等操作时需要对文件进行处理,都要求掌握基本的目录、
文件处理以及文件的基本能力。 包含基本文件读写,列表,字典,元组操作。
1.基本文件读写方式,及数据简单处理
2.json文件读写方式,及数据简单处理
3.xml文件读写方式,及数据简单处理
4.csv文件读写方式,及数据简单处理
自定义模块调用
root_look.py(自定义的模块,不运行它)
import sys
import cv2
import os
class GetRootFiles(object):
def __init__(self):
print ("look root file")
def look_root(self,path):
ret = []
for root, dirs, files in os.walk(path):
#print (root,dirs)
for filespath in files:
#print(os.path.join(root,filespath))
ret.append(os.path.join(root,filespath))
return ret
def getListFiles(path):
"""
遍历目录下的所有文件,包含所有层级目录,os.walk类似于一个迭代器。
"""
ret = []
for root, dirs, files in os.walk(path):
#print (root,dirs)
for filespath in files:
#print(os.path.join(root,filespath))
ret.append(os.path.join(root,filespath))
return ret
def main():
root_ope()
file = getListFiles("D:/server/pic_xiangsi")
print ("file_counter:",len(file))
if __name__ == "__main__":
main()
use_moudle.py (运行这个文件,调用自定义模块)
import root_look
from root_look import getListFiles
from root_look import GetRootFiles
def main():
#data = root_look.getListFiles("D:/server/pic_xiangsi")
#data = getListFiles("D:/server/pic_xiangsi")
#data = GetRootFiles().look_root("D:/server/pic_xiangsi")
data = root_look.GetRootFiles().look_root("D:/server/pic_xiangsi")
for i,li in enumerate(data):
print (i,li)
main()
if __name__ == "__main__":
main()
"""
look root file
0 D:/server/pic_xiangsi\alcremie.png
1 D:/server/pic_xiangsi\altaria.png
2 D:/server/pic_xiangsi\current.json
3 D:/server/pic_xiangsi\dataset_xsd.py
4 D:/server/pic_xiangsi\display_rect_check.py
5 D:/server/pic_xiangsi\get_record_num_file.py
6 D:/server/pic_xiangsi\network.py
7 D:/server/pic_xiangsi\network1.py
...
...
"""
说明:
将两个文件放入同级目录,调用自定义的函数或类模块。
也可以放在Python的模块包的路径下。
当存在两个同名的模块时,优先调用同级目录的模块。
当存在不同版本的模块时,可以采用此方法。
我们有时需要修改别人写的模块,必须知道基本的原理,以及模块包的结构。
other
## 同级目录类模块调用
## 同级目录函数模块调用
## 将模块放入Python模块库中
## 构建项目工程模块包
暂时等待,日后更新
基于自定义类的API接口构建方式
暂时等待,日后更新
参考,https://github.com/bubbliiiing/Siamese-tf2
参考,https://blog.csdn.net/weixin_44791964/article/details/107488516