孪生神经网络专题
孪生网络专题
孪生神经网络(Siamese Network)
可以解决的问题?
- 孪生神经网络可解决以下两种分类问题:
- 第一类,分类数量较少,每一类的数据量较多,比如ImageNet、VOC等。这种分类问题可以使用神经网络或者SVM解决,只要事先知道了所有的类。
- 第二类,分类数量较多(或者说无法确认具体数量),每一类的数据量较少,比如人脸识别、人脸验证任务。
何为“孪生”?
-
Siamese:”连体“,”孪生“,来源于泰国(暹罗)的连体双胞胎(Siamese Twins)
-
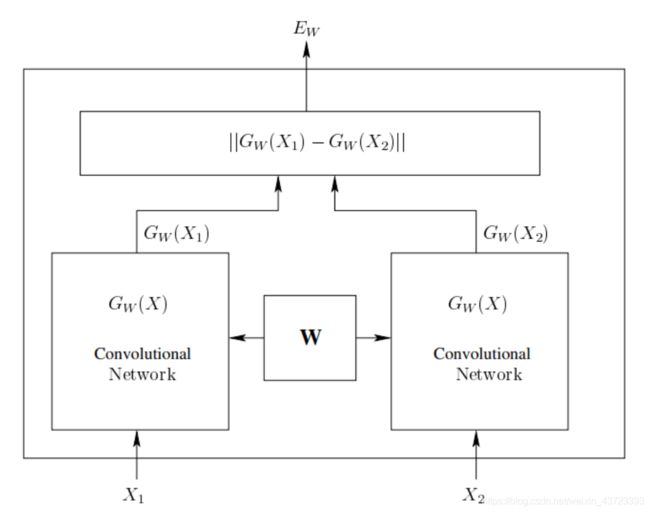
Siamese Network 具有两个结构相同,且权值共享的子网络。分别接收两个输入 X 1 X_{1} X1 与 X 2 X_{2} X2 ,将其转换为向量 G W ( X 1 ) G_{W}(X_{1}) GW(X1) 与 G W ( X 2 ) G_{W}(X_{2}) GW(X2) ,再通过某种距离度量的方式计算两个输出向量的距离 E W E_{W} EW。
在低维空间,任意两个样本:
- 如果它们是相同类别,空间距离尽量接近0
- 如果它们是不同类别,空间距离大于某个间隔
-
训练样本:
训练样本的形式应该表示成为一个三元组,即 t u p l e ( X 1 , X 2 , Y ) tuple (X_{1},X_{2},Y) tuple(X1,X2,Y) 将其转化为向量 G W ( X 1 ) G_W(X_{1}) GW(X1) 和 G W ( X 2 ) G_{W}(X_{2}) GW(X2),再通过某种距离度量的方式计算出两个输出向量的距离 E W E_{W} EW。
-
孪生方法:
寻找一个映射函数,能够将输入图像转换到一个特征空间,每个语句对应一个特征向量,通过一些简单的“距离度量”(比如欧式距离)来表示向量之间的差异,最后通过这个距离来拟合输入图像的相似度差异(语义差异)。
采用什么方法解决?
-
Siamese Network 思路:
孪生神经网络提出了一种思路,将输入映射成以恶特征向量,采用L1正则化指标衡量两个向量之间的距离,定量表示输入向量之间的差异。孪生神经网络每次需要输入两个样本作为一个样本对来计算损失函数,提出了用于训练的Contrastive Loss用于孪生神经网络的训练。

孪生神经网络结构
Siamese Network 结构:—— 类似于差分放大器
评价指标 之 损失函数
LOSS函数设计的基本准则应该是
L ( W ) = ∑ i = 1 P L ( W , ( Y , X 1 , X 2 ) i ) L ( W , ( Y , X 1 , X 2 ) i ) = ( 1 − Y ) L G ( E W ( X 1 , X 2 ) i ) + Y L I ( E W ( X 1 , X 2 ) i ) \begin{aligned} \mathcal{L}(W) &=\sum_{i=1}^{P} L\left(W,\left(Y, X_{1}, X_{2}\right)^{i}\right) \\ L\left(W,\left(Y, X_{1}, X_{2}\right)^{i}\right) &=(1-Y) L_{G}\left(E_{W}\left(X_{1}, X_{2}\right)^{i}\right) +Y L_{I}\left(E_{W}\left(X_{1}, X_{2}\right)^{i}\right) \end{aligned} L(W)L(W,(Y,X1,X2)i)=i=1∑PL(W,(Y,X1,X2)i)=(1−Y)LG(EW(X1,X2)i)+YLI(EW(X1,X2)i)
其中,数学符号表示
- Y Y Y 表示 X 1 , X 2 X_{1}, X_{2} X1,X2 是否属于同一类:
- 若为同类,则为0;
- 若为不同类,则为1。
- P P P 表示输入的总样本数, i i i 表示当前样本的下标。
- L G L_{G} LG 表示两个样本为同类时的损失函数, L I L_{I} LI 表示两个样本未不同类时的损失函数。
- 使用Contrastive Loss的任务主要是设计合适的 L G L_{G} LG 和 L I L_{I} LI 损失函数, 当为同类时,使得 L G L_{G} LG 尽可能 小; 当不同类时,使得 L I L_{I} LI 尽可能大。文中给出的函数如下图, 现在也不常用了,推导步骤略。
在Caffe框架下,损失函数定义为
L = 1 2 N ∑ n = 1 N y D W 2 + ( 1 − y ) max ( margin − D W , 0 ) 2 L=\frac{1}{2 N} \sum_{n=1}^{N} y D_{W}^{2}+(1-y) \max (\operatorname{margin}-D_{W}, 0)^{2} L=2N1n=1∑NyDW2+(1−y)max(margin−DW,0)2
其中,
D W ( X 1 , X 2 ) = ∥ X 1 − X 2 ∥ 2 = ( ∑ i = 1 P ( X 1 i − X 2 i ) 2 ) 1 2 D_{W}\left(X_{1}, X_{2}\right)=\left\|X_{1}-X_{2}\right\|_{2}=\left(\sum_{i=1}^{P}\left(X_{1}^{i}-X_{2}^{i}\right)^{2}\right)^{\frac{1}{2}} DW(X1,X2)=∥X1−X2∥2=(i=1∑P(X1i−X2i)2)21
-
D W D_{W} DW 代表两个样本特征 X 1 X_{1} X1 和 X 2 X_{2} X2 的欧式距离(向量差的二范数)
-
P P P 表示样本的特征维数
-
Y Y Y 为两个样本是否匹配的标签
- Y = 1 Y=1 Y=1 代表两个样本相似或者匹配
- Y = 0 Y=0 Y=0 代表两个样本不匹配
-
m a r g i n margin margin 为设定的阈值,也可以成为边际价值。有一个边际价值表示超出该边际价值的不同对不会造成损失。这是有道理的,因为你只希望基于实际不相似对来优化网络,但网络认为是相当相似的。
- 当 Y = 1 Y=1 Y=1 时,如果 X 1 X_{1} X1 与 X 2 X_{2} X2 之间距离大于 m m m,则不做优化——省时省力
- 当 Y = 0 Y=0 Y=0 时,如果 X 1 X_{1} X1 与 X 2 X_{2} X2 之间的距离小于 m m m,则调整参数使其距离增大到 m m m
-
N N N 为样本个数
详谈损失函数
-
损失函数还有更多的选择
Siamese network的初衷是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个"向量",在新的空间中,通过判断cosine距离就能得到相似度了。cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。其他的距离度量没有太多经验,这里简单说一下cosine和exp在NLP中的区别。
-
根据实验分析,cosine更适用于词汇级别的语义相似度度量,而exp更适用于句子级别、段落级别的文本相似性度量。其中的原因可能是cosine仅仅计算两个向量的夹角,exp还能够保存两个向量的长度信息,而句子蕴含更多的信息。
损失函数 Python 实现
import torch
import numpy as np
import torch.nn.functional as F
class ContrastiveLoss(torch.nn.Module):
"Contrastive loss function"
def __init__(self, m=2.0):
super(ContrastiveLoss, self).__init__()
self.m = m
def forward(self, output1, output2, label):
d_w = F.pairwise_distance(output1, output2)
contrastive_loss = torch.mean((1-label) * 0.5 * torch.pow(d_w, 2) +
(label) * 0.5 * torch.pow(torch.clamp(self.m - d_w, min=0.0), 2))
return contrastive_loss
其中,F.pairwise_distance(x1, x2, p=2)
pairwise_distance(x1, x2, p)Computes the batchwise pairwise distance between vectors x 1 , x 2 x_{1},x_{2} x1,x2 using the p-norm.
( ∑ i = 1 n ( ∣ x 1 − x 2 ∣ p ) ) 1 p x 1 , x 2 ∈ R b × n \begin{array}{c} \left(\sum_{i=1}^{n}\left(\left|x_{1}-x_{2}\right|^{p}\right)\right)^{\frac{1}{p}} \\ x_{1}, x_{2} \in \mathbb{R}^{b \times n} \end{array} (∑i=1n(∣x1−x2∣p))p1x1,x2∈Rb×n
小结
孪生神经网络的直接用途就是衡量两个输入之间的差异/相似程度。
孪生神经网络的用途:
- 词汇语义相似度分析
- 问答机制中 question 和 answer的匹配
- 手写体识别
- 问题匹配
- Kaggle上Quora的Question Pair比赛,即判断两个提问是否为同一个问题
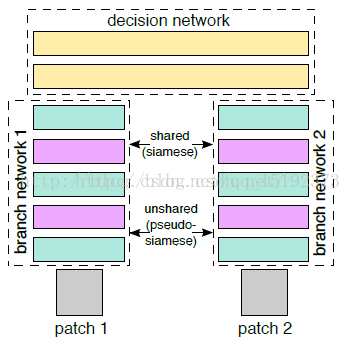
改进的Siamese网络 (2-channel networks)

Siamese 网络(2-branches networks)的大体思路:
- 让patch1、patch2分别经过网络,进行提取特征向量(Siamese 对于两张图片patch1、patch2的特征提取过程是相互独立的)
- 然后在最后一层对两个两个特征向量做一个相似度损失函数,进行网络训练。
paper所提出的算法(2-channel networks) 的大体思路:
- 把patch1、patch2合在一起,把这两张图片,看成是一张双通道的图像。也就是把两个(1,64,64)单通道的数据,放在一起,成为了(2,64,64)的双通道矩阵。
- 然后把这个矩阵数据作为网络的输入,这就是所谓的:2-channel。
这样,跳过了分支的显式的特征提取过程,而是直接学习相似度评价函数。最后一层直接是全连接层,输出神经元个数直接为1,直接表示两张图片的相似度。当然CNN,如果输入的是双通道图片,也就是相当于网络的输入的是2个feature map,经过第一层的卷积后网,两张图片的像素就进行了相关的加权组合并映射,这也就是说,用2-channel的方法,经过了第一次的卷积后,两张输入图片就不分你我了。而Siamese网络是到了最后全连接的时候,两张图片的相关神经元才联系在一起。
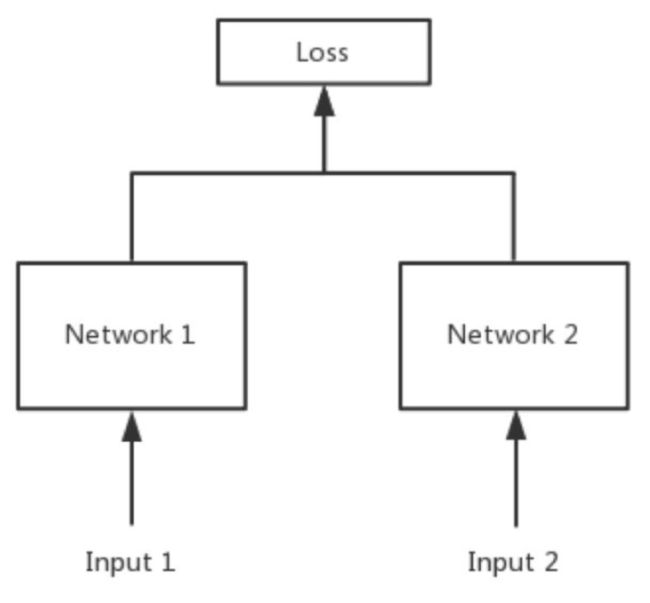
伪孪生网络 (Pseudo-Siamese Network)
“伪”字含义:
对于伪孪生网络来说,两边可以是不同的神经网络(例如,一个是LSTM,另一个是CNN),并且如果两边是相同的神经网络,是不共享参数的
伪孪生神经网络结构
伪孪生圣经网络结构如下图所示:
可以解决的问题?
- 孪生网络适用于处理两个输入比较类似的情况
- 伪孪生网络设用于处理啷个输入有一定差别的情况
例如,计算两个句子或者词汇的语义相似度,使用Siamese Network比较合适;验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字)就应该使用Pseudo-Siamese Network
三胞胎网络(Triplet Network)
论文:《Deep metric learning using Triplet network》
三个输入:一个正例+两个负例 或者 两个正例+一个负例
训练的目的是让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大。
训练效果:Triplet在cifar, mnist的数据集上,效果都是很不错的,超过了siamese network。
三胞胎网络结构
输入: x − x^{-} x−与 x x x是负样本, x + x^{+} x+与 x x x是相似正样本。


三胞胎网络的损失函数
损失函数定义如下:
L = max ( d ( a , p ) − d ( a , n ) + margin , 0 ) \mathcal{L}=\max (d(a, p)-d(a, n)+\operatorname{margin}, 0) L=max(d(a,p)−d(a,n)+margin,0)
- a a a 表示anchor图像
- p p p 表示positive图像
- n n n 表示negative图像
我们希望 a a a 与 p p p 的距离应该小于 a a a 与 n n n 的距离。 m a r g i n margin margin 是个超参数,它表示 d ( a , p ) d(a,p) d(a,p) 与 d ( a , n ) d(a,n) d(a,n) 之间应该相差多少,例如,假设 m a r g i n = 0 margin=0 margin=0,并且 d ( a , p ) = 0.5 d(a,p)=0.5 d(a,p)=0.5 ,那么 d ( a , n ) d(a,n) d(a,n) 应该大于等于 0.7 0.7 0.7
Appendix:Andrew NG 三重损失函数
-
代价函数是训练集的所有个体的三重损失的和:
Cost function: J = ∑ i = 1 n L ( A ( i ) , P ( i ) , N ( i ) ) \text { Cost function: } J=\sum_{i=1}^{n} L\left(A^{(i)}, P^{(i)}, N^{(i)}\right) Cost function: J=i=1∑nL(A(i),P(i),N(i)) -
三重损失函数:
L ( A , P , N ) = max ( ∥ f ( A ) − f ( P ) ∥ 2 − ∥ f ( A ) − f ( N ) ∥ 2 + α , 0 ) L(A, P, N)=\max \left(\|f(A)-f(P)\|^{2}-\|f(A)-f(N)\|^{2}+\alpha, 0\right) L(A,P,N)=max(∥f(A)−f(P)∥2−∥f(A)−f(N)∥2+α,0) -
解释:
这里的最大化处理意味着只要 d ( A , P ) — d ( A , N ) + α d(A, P)—d(A, N)+ α d(A,P)—d(A,N)+α 小于等于 0 0 0,那么 l o s s L ( A , P , N ) loss L(A, P, N) lossL(A,P,N) 就会是 0 0 0,但是一旦它大于 0 0 0,那么损失值就是正的,这个函数就会将它最小化成 0 0 0 或者小于 0 0 0。
这里的问题是,模型可能学习给不同的图片做出相同的编码,这意味着距离会成为 0 0 0,不幸的是,这仍然满足三重损失函数。因为这个原因,我们加入了边际 α α α(一个超参数)来避免这种情况的发生。让 d ( A , P ) d(A,P) d(A,P) 与 d ( N , P ) d(N,P) d(N,P) 之间总存在一个差距。
-
为了比较图片 x ( 1 ) x(1) x(1) 和 x ( 2 ) x(2) x(2) ,我们计算了编码 结果 f ( x 1 ) f(x_{1}) f(x1) 和 f ( x 2 ) f(x_{2}) f(x2) 之间的距离。
d ( x ( 1 ) , x ( 2 ) ) = ∥ f ( x ( 1 ) ) − f ( x ( 2 ) ) ∥ 2 2 d\left(x^{(1)}, x^{(2)}\right)=\left\|f\left(x^{(1)}\right)-f\left(x^{(2)}\right)\right\|_{2}^{2} d(x(1),x(2))=∥∥∥f(x(1))−f(x(2))∥∥∥22
上式是 x 1 x_{1} x1 和 x 2 x_{2} x2 的编码距离。如果它比某个阈值(一个超参数)小,则意味着两张图片是同一个人,否则,两张图片中不是同一个人。
-
适用于任何两张图片【存在正负样本】
If x ( i ) , x ( j ) x^{(i)}, x^{(j)} x(i),x(j) are the same person, ∥ f ( x ( i ) ) − f ( x ( j ) ) ∥ 2 \left\|f\left(x^{(i)}\right)-f\left(x^{(j)}\right)\right\|^{2} ∥∥f(x(i))−f(x(j))∥∥2 is small.
If x ( i ) , x ( j ) x^{(i)}, x^{(j)} x(i),x(j) are different persons, ∥ f ( x ( i ) ) − f ( x ( j ) ) ∥ 2 \left\|f\left(x^{(i)}\right)-f\left(x^{(j)}\right)\right\|^{2} ∥∥f(x(i))−f(x(j))∥∥2 is large.
-
应用:
- Image ranking
- face verification
- metric learning
参考资料:
- 多种类型的神经网络(孪生网络)
- Siamese network 孪生神经网络–一个简单神奇的结构
- Siamese Network & Triplet Loss
- A friendly introduction to Siamese Networks
- Contrastive Loss