PCA降维可视化举例
文章目录
- 前言
- 1、生成一群二维点并画在坐标轴上
- 2、PCA降维
- 3、平移回去PCA和原来点共同显示
- 总结
前言
横看成岭侧成峰,远近高低各不同。PCA降维的作用是降低数据的维度,同时让最小的维度得到最大原数据的信息,也就是降维后的点方差最大。本文通过一群点从二维降到一维可视化PCA的效果
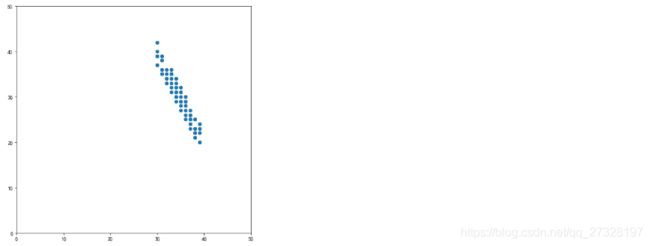
1、生成一群二维点并画在坐标轴上
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#先生成一群点 然后画出来
datax=np.random.randint(30,40, size=(1, 100)).flatten()
datay=-2*datax+100+np.random.randint(-3,3, size=(1, 100)).flatten()
dataxy=pd.DataFrame(data={'x':datax,'y':datay})
plt.figure(figsize=(8,8))
plt.xlim((0, 50))
plt.ylim((0, 50))
plt.scatter(dataxy['x'],dataxy['y'])
plt.show()
2、PCA降维
from sklearn.decomposition import PCA
transfer=PCA(n_components=1)#n_components=1表示降成一维
data_new=transfer.fit_transform(dataxy)#调用fit_transform
print("经过降维之后的数据的类型和维度:",type(data_new),data_new.shape)
x_pca=np.dot(data_new,transfer.components_)
plt.figure(figsize=(8,8))
plt.grid(True)
plt.title("PCA降维之后的情况")
plt.xlim(-15,15)
plt.ylim(-15,15)
plt.scatter(x_pca[:,0],x_pca[:,1])
plt.show()#PCA降维自动给数据规范化了一下 均值为0 方差为1 从下图可以看出来

3、平移回去PCA和原来点共同显示
mean_x = np.mean(dataxy.values[:, 0])#得到原来那批数据的x的中点
mean_y = np.mean(dataxy.values[:, 1])#得到y的终点 得到原来那群点的中点 目的是把PCA降维成一条直线了点平移回去
w2 = np.ones(dataxy.shape)
w2[:, 0] = w2[:, 0] * mean_x
w2[:, 1] = w2[:, 1] * mean_y
x_pca_transBack = x_pca + w2#平移回去了
plt.figure(figsize=(8,8))
plt.scatter(dataxy['x'], dataxy['y'], alpha=0.3, c='blue', label='原数据') # ,c='black'
plt.scatter(x_pca_transBack[:, 0], x_pca_transBack[:, 1], c='red', label='PCA降维之后的数据',s=5)
plt.legend(prop={"size": 15, "weight": "black"}) # 这句代码是控制图例的字体大小
plt.xlim(0,50)
plt.ylim(0,50)
plt.grid(True)
plt.show()

总结
(如果您发现我哪里写的有错误,欢迎在评论区批评指正)