李宏毅学习笔记28.More About Auto-Encoder
文章目录
- 简介
- Beyond Reconstruction
-
- How to evaluate an encoder?
- Sequential Data
-
- Skip thought
- Quick thought
- Contrastive Predictive Coding(CPC)
- Feature Disentangle
-
- Voice Conversion
- Adversarial Training
- Designed Network Architecture
- Discrete Representation
-
- VQVAE
- Sequence as Embedding
- Tree as Embedding
简介
本节是新加的内容,AUTO-ENCODER有很多内容在本节中补充。
公式输入请参考:在线Latex公式

AUTO-ENCODER模型构架如上图所示,中间的vector也被称为:
Embedding,Latent Representation,Latent Code
那么本节要从两个方面来讲:
·More than minimizing reconstruction error
·More interpretable embedding
之前要做embedding的根本原因是:An embedding should represent the object.

额,二次元的世界我不懂。。。推测上面左边的二次元人物的形象是脖子上挂铁三角,因此铁三角可以作为她的embedding表示。so进入第一个话题:
Beyond Reconstruction
How to evaluate an encoder?
接上面的例子,实际上我们是有这样的encoder(吃图片,吐vector表示):

这个模型相当于GAN里面的Discriminator(相当于binary classifier)

这个模型训练吃图片,判断是否和标签是不是一对。

oss of the classification task is 输出与标签的交叉熵 L D L_D LD
我们用 ϕ \phi ϕ来表示Discriminator的参数,那么训练模型参数来最小化 L D L_D LD可以写为:
L D ∗ = m i n ϕ L D (1) L^*_D=\underset{\phi}{min}L_D\tag1 LD∗=ϕminLD(1)
如果训练后我们发现 L D ∗ L^*_D LD∗很小,那么我们可以下结论:The embeddings are representative. 机器就可以根据图片和向量表示判断他们是一对的
如果发现 L D ∗ L^*_D LD∗很大,那么我们可以说,向量表示不好,图片和向量无法判断是否一对:


既然我们知道如何来评估向量表示的好和不好,我们就是要调整encoder的参数 θ \theta θ,然后用评估方法(根据 L D ∗ L^*_D LD∗来评估)来让生成向量最优。
θ ∗ = a r g min θ L D ∗ \theta^*=arg\underset{\theta}{\text{min}}L^*_D θ∗=argθminLD∗
把公式1代入:
θ ∗ = a r g min θ min ϕ L D \theta^*=arg\underset{\theta}{\text{min}}\underset{\phi}{\text{min}}L_D θ∗=argθminϕminLD
也就是说我们要训练encoder的参数 θ \theta θ和discriminator的参数 ϕ \phi ϕ,使得 L D L_D LD最小化,这个东西实际可以类比到最原始的auto-encoder模型要同时训练encoder和decoder使得reconstruction error最小。也就是说auto-encoder模型:

实际上就是下面encoder+discriminator模型的special case

这一节把之前的auto-encoder进行了扩展,变成了encoder+discriminator模型。
Sequential Data
这小节来看看,如果输入数据是Sequential的数据会是什么情况。最常见的Sequential data就是文章。
之前有解决这个问题的模型叫:Skip thought
Skip thought
就是根据中间句来预测上下句。

这个模型训练过程和训练word embedding很像,因为训练word embedding的时候有这么一个原则,就是两个词的上下文很像的时候,这两个词的embedding就会很接近。换到句子的模型上,如果两个句子的上下文很像,那么这两个句子的embedding就应该很接近。
例如:
这个东西多少钱?答:10元。
这个东西多贵?答:10元。
发现答案一样,所以问句的embedding是很接近的。
Quick thought
文献:https://arxiv.org/pdf/1803.02893.pdf
由于Skip thought要训练encoder和decoder,因此训练速度比较慢,因此有出现一个改进版本Quick thought,顾名思义就是训练速度上很快。在Quick thought里面只训练encoder,不训练decoder。

丢一个句子进encoder得到的向量表示要和下一个句子丢进encoder得到的向量表示要越接近越好,而与随机句子丢进encoder得到的向量表示要越接远越好。
模型中的classifier吃当前句子(Spring had come.)的向量表示,还吃下一句(And yet his crops didn’t grow.)和其它几个随机生成的句子的向量表示,这个classifier可以输出正确的下一句。
classifier和encoder是一起训练的。
实作上classifier做的事情很简单,就是直接拿当前句子的向量表示和所有句子的向量表示做内积,看谁的内积最大,谁就是下一个句子。这里为了防止机器作弊,直接把输入作为下一句(这样内积最大),还要附加条件:使得当前句的向量表示和随机句子的向量表示越不像越好。
Contrastive Predictive Coding(CPC)
这个模型和Quick thought的思想是一样的,不过是用在声音信号上的。(不展开)

下面看第二个话题(More interpretable embedding)
Feature Disentangle
Disentangle意思是解开

·An object contains multiple aspect information. 例如

中间的vector包含不仅仅是声音信息,还有讲话人的声音特点,环境噪音等其他信息。

图片向量化后可以包含图片本身的信息之外还有画风,图片中的物品等信息。
但是现在我们只用一个向量来表示一个object,我们是无法知道向量的那些维度包含那些信息,例如表示声音的向量,那些维度包含内容信息,那些包含讲话人的性别信息等。也就是说这些信息是交织在一起的,我们希望模型可以帮我们把这些信息disentangle开来。
两种方法:
一种是在训练出来的vector上已经把不同内容分开了:

一种是训练两个encoder分别抽取不同内容,然后把两个部分拼接起来,才能还原原来的内容。。

Voice Conversion
方法一的例子:


人和说话的内容是放在同一个向量里面的。
然后把女生说话的内容,和男生说话的特点合起来,就变成了男生在说How are you?(抠男飘过)
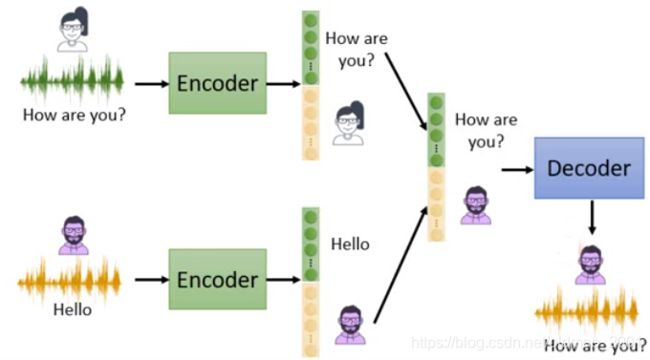
·The same sentence has different impact when it is said by different people.

Adversarial Training
训练模型的过程很有意思,假设encoder输出的向量一共有200维,我们希望把语者(说话人)信息(就是性别)放到后面100中(如下图所示的黄色部分),那么我们就把前面100维(绿色部分)接到一个Speaker Classifier上,Classifier用来分辨语者的性别,encoder的原目标要加上一个限制,就是要使得不能让Classifier分辨出语者的性别,因此在训练的过程中就会把语者的性别放到后100维中去了,前100维就只剩下内容的信息了。
在实作过程中,通常是利用GAN来完成这个过程,也就是把encoder看做generator,把Classifier看做discriminator。Speaker classifier and encoder are learned iteratively.

Designed Network Architecture
当然也可以用第二种方法来解决变声器的问题

IN=instance normalization (remove global information)
AdaIN=adaptive instance normalization (only influence global information)
这里不展开,两个normalization 的方法应该会有归一化专题讲解。
Discrete Representation
如果模型可以从连续型的向量表示变成输出离散的表示,那么对于表示的解释性估计会有更好的理解。(·Easier to interpret or clustering)
例如:用独热编码表示图片,做法很简单,在连续向量后面接相同维度的独热编码,看连续变量的哪个维度最大就用哪个做独热编码的1.

同样可以用Binary向量来表示图片,只不过判断0/1的方法不一样,这里如果大于0.5取1,小于取0

但是上面的模型在连续向量转离散向量的步骤上是不可做偏导的(无法GD)但是有办法:https://arxiv.org/pdf/1611.01144.pdf
当然,上面两个离散向量的模型比较起来,Binary模型要好,原因有两点:
1、同样的类别Binary需要的参数量要比独热编码少,例如1024个类别Binary只需要10维即可,独热需要1024维;
2、使用Binary模型可以处理在训练数据中未出现过的类别。
除了上面的两个模型之外,在实作上有:
VQVAE
Vector Quantized Variational Auto-encoder(VQVAE)
文献:https://arxiv.org/abs/1711.00937

第一步:先用Encoder抽取为连续型的向量vector;
第二步:再用vector与Codebook中的离散变量 V e c t o r i Vector_i Vectori进行相似度计算,例如上图中黄色的 V e c t o r 3 Vector_3 Vector3;
第三步:用 V e c t o r 3 Vector_3 Vector3还原输入信息。
上面的模型中,如果输入的是语音信息,那么语者信息和噪音信息会被过滤掉,因为上面的Codebook中保存的是离散变量,而内容信息是一个个的token,是容易用离散向量来表示的,而其他信息不适合用离散变量表示,因此会被过滤掉。
因此过滤信息是VQVAE的一个应用。
既然可以用离散向量来表示输入信息,那么我们也可以考虑用序列来embedding
Sequence as Embedding
文献:https://arxiv.org/abs/1810.02851
This is a seq2seq2seq auto-encoder.
Using a sequence of words as latent representation.

例如:一篇文章经过encoder得到一串文字,然后这串文字再通过decoder还原回文章。
Only need a lot of documents to train the model.
中间的文字是什么?摘要。
但是这个模型效果是不好的,例如:
台湾大学会被机器抽取为:湾学,而不是台大。因为模型只要还原原文,而没有要求抽取出来的东西要符合语法规则。
因此模型可以改进为:

例子:


做得不好的例子:


Tree as Embedding
除了向量表示,序列表示,还有tree表示(不展开)
https://arxiv.org/abs/1806.07832

https://arxiv.org/abs/1904.03746
