基于物品的协同过滤算法的电影推荐系统的Python实现
一、算法原理
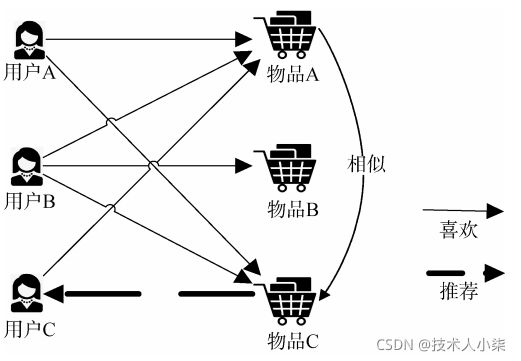
基于物品的协同过滤推荐的原理和基于用户的原理类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。例如下图,用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,通过这些用户的喜好可以判定物品A和物品C相似,喜欢物品A的用户同时也喜欢物品C,因此给喜欢物品A的用户C也推荐了物品C。
二、算法设计
3.1 基于物品的推荐算法流程
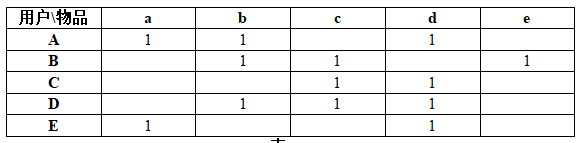
3.1.1 构建用户:
列表示用户,行表示物品,1表示用户喜欢该商品:
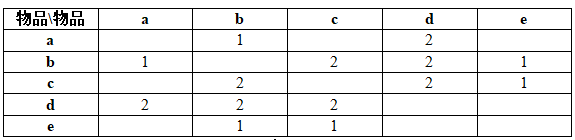
3.1.2 构建物品与物品的同现矩阵:
共现矩阵C表示同时喜欢两个物品的用户数,是根据用户物品倒排表计算出来的。如根据上面的用户物品倒排表可以计算出如表的共现矩阵C:
3.1.3 计算物品之间的相似度,即计算相似矩阵:
两个物品之间相似度的计算,设|N(i)|表示喜欢物品i的用户数,|N(i)⋂N(j)|表示同时喜欢物品i,j的用户数,则物品i与物品j的相似度为::
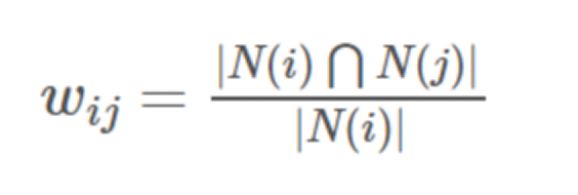
(1)式有一个问题,当物品j是一个很热门的商品时,人人都喜欢,那么wij就会很接近于1,即(1)式会让很多物品都和热门商品有一个很大的相似度,所以可以改进一下公式:
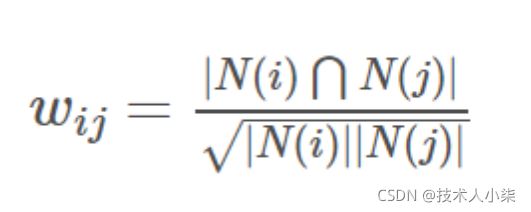
算法流程1.2中的共现矩阵C其实就是式(2)的分子,矩阵N(用于计算分母)表示喜欢某物品的用户数(是总的用户数),则(2)式中的分母便很容易求解出来了。矩阵N如表所示:

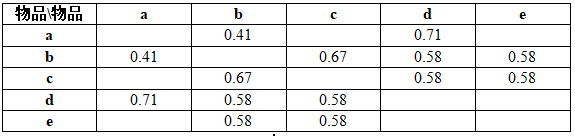
利用式(2)便能计算物品之间的余弦相似矩阵如表:
3.1.4 根据用户的历史记录,给用户推荐物品;
最终推荐的是什么物品,是由预测兴趣度决定的。
物品j预测兴趣度=用户喜欢的物品i的兴趣度×物品i和物品j的相似度
三、代码实现
电影数据使用的是基于用户的协同过滤算法的电影推荐系统的Python实现中的数据。
from math import sqrt
import operator
#构建用户-->物品的倒排(此推荐无需使用)
def loadData(files):
data ={};
for line in files:
user,score,item=line.split(",");
data.setdefault(user,{});
data[user][item]=score;
print("用户:物品的倒排:" )
print(data )
return data
#计算
# 构造物品-->物品的共现矩阵
# 计算物品与物品的相似矩阵
def similarity(data):
# 构造物品:物品的共现矩阵
N={};#喜欢物品i的总人数
C={};#喜欢物品i也喜欢物品j的人数
for user,item in data.items():
for i,score in item.items():
N.setdefault(i,0);
N[i]+=1;
C.setdefault(i,{});
for j,scores in item.items():
if j not in i:
C[i].setdefault(j,0);
C[i][j]+=1;
print("2.构造的共现矩阵:" )
print ('N:',N);
print ('C',C);
#计算物品与物品的相似矩阵
W={};
for i,item in C.items():
W.setdefault(i,{});
for j,item2 in item.items():
W[i].setdefault(j,0);
W[i][j]=C[i][j]/sqrt(N[i]*N[j]);
print("3.计算的相似矩阵:" )
print(W )
return W
#根据用户的历史记录,给用户推荐物品
def recommandList(data,W,user,k=3,N=10):
rank={};
for i,score in data[user].items():#获得用户user历史记录,如A用户的历史记录为{'a': '1', 'b': '1', 'd': '1'}
for j,w in sorted(W[i].items(),key=operator.itemgetter(1),reverse=True)[0:k]:#获得与物品i相似的k个物品
if j not in data[user].keys():#该相似的物品不在用户user的记录里
rank.setdefault(j,0);
rank[j]+=float(score) * w;
print("4.推荐:" )
print(sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:N] )
return sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:N];
if __name__=='__main__':
print("***基于物品的协同过滤算法的电影推荐实例实现***")
print("1.构造数据:" )
data ={ 'UserA': {'《战狼2》': 4.5, '《红海行动》': 4.5,'《湄公河行动》': 4.0, '《你好 李焕英》': 3.5,'《泰囧》': 3.0, '《港囧》': 2.5},
'UserB': {'《战狼2》': 4.0, '《红海行动》': 3.5,'《湄公河行动》': 4.5, '《你好 李焕英》': 3.0, '《泰囧》': 3.0,'《港囧》': 3.5},
'UserC': {'《战狼2》': 4.5, '《红海行动》': 4.0, '《你好 李焕英》': 3.5, '《泰囧》': 3.0},
'UserD': { '《红海行动》': 4.5, '《湄公河行动》': 4.0,'《你好 李焕英》': 4.0, '《泰囧》': 3.5,'《港囧》': 2.5},
'UserE': {'《战狼2》': 4.0, '《红海行动》': 4.0,'《湄公河行动》': 4.0, '《你好 李焕英》': 4.5, '《泰囧》': 3.0,'《港囧》': 3.0},
'UserF': {'《战狼2》': 4.0, '《红海行动》': 4.0, '《你好 李焕英》': 3.5, '《泰囧》': 3.0,'《港囧》': 3.5},
'UserG': { '《红海行动》': 4.5, '《你好 李焕英》': 4.0, '《港囧》': 2.0}
}
W=similarity(data);#计算物品相似矩阵
recommandList(data,W,'UserG',10,10);#推荐