python实现 基于邻域的算法之协同过滤(电影推荐实战)
1 介绍
1.1 用户行为数据
用户行为数据通常把包括:网页浏览、购买点击、评分和评论等。
用户行为在个性化推荐系统中一般分为两种:
显性反馈行为(explicit feedback)
包括:用户明确表示明确对物品喜好的行为,网站中收集显性反馈的方式就是评分喜欢/不喜欢。隐形反馈行为(implicit feedback)
指那些不能明确反应用户喜好的行为,最具有代表性的隐形反馈行为就是页面浏览行为。
安装反馈方向分,又可以分为正反馈和负反馈
- 正反馈
指用户的行为倾向于指用户喜欢该物品 - 负反馈
指用户的行为倾向于指用户不喜欢该物品。
在显性反馈行为中,很容易区分一个用户行为是正反馈还是负反馈,而在隐形反馈行为中,就相对难以确定。
1.2 用户行为分析
在利用用户行为数据设计推荐算法之前,研究人员需要对用户行为数据进行分析,了解数据中蕴含的一般规律,这样才能对算的设计起到指导作用。
- 用户活跃度和物品流行度
- 用户活跃度和物品流行度的关系。
协同规律有很多方法:
- 基于领域的方法(neighborhood-based)(最著名)
- 隐语义模型(latent factor model)
- 基于图的随机游走算法(radom walk on graph)
基于领域的方法(neighborhood-based)
基于用户的协同过滤算法:给用户推荐和他兴趣相似的其他用户喜欢的物品。基于物品的协同过滤算法:给用户推荐和他之前喜欢的武平相似的物品。
2 基于领域的算法
基于领域的算法是推荐系统中最基本的算法,该算法不仅在学术界得到了深入研究,而且在业界得到了广泛应用。
2.2 基于用户的协同过滤算法(UserCF)
基本思想:
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有的物品推荐给A。
步骤:
(1)找到和目标用户兴趣相似的用户集合。
(2)找到这个集合中的用户喜欢的,且目标用户木有听说过的物品推荐给目标用户。
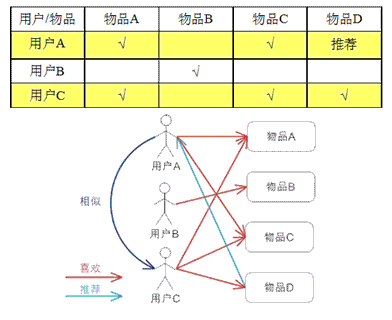
2.3 基于物品的协同过滤算法(ItemCF)
ItemCollaborationFilter
核心:
给用户推荐那些和他们之前喜欢的物品相似的物品。
主要步骤:
(1)计算物品之间的相似度;
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表;
3 ItemCF电影推荐
3.1 计算电影的相似矩阵 & 计算物品相似矩阵w
3.1.1 计算电影的相似矩阵
原理: 用户看过的电影之间的联系
用户A:看过电影 film1 和 film2,则 film1 与 film2 关系值为1。
用户B:也看过 电影 film1 和 film2,则关系值 +1
以此类推。
3.1.2 计算电影之间的相似性
使用余弦相似度

|N(i)|:喜欢物品 i 的用户数
|N(j)|:喜欢物品 j 的用户数
|N(i)&N(j)|:同时喜欢物品 i 和物品 j 的用户数
举例:
(1)用户 A 对 a、b、d 有过行为,用户 B 对物品 b、c、e 有过行为。。。
A:a、b、d
B:b、c、e
C:c、d
D:b、c、d
E:a、d
(2)依次构建用户—物品到排表:
eg. 物品 a 被用户 A、E 有过行为,。。。
a:A、E
b:A、B、D
c:B、C、D
d:A、C、D、E
d:B
(3)建立物品相似度矩阵 C

其中,C[i][j]记录了同时喜欢物品i和物品j的用户数,这样我们就可以得到物品之间的相似度矩阵W。
3.1.3 代码
# 计算电影间的相似度
def calc_movie_sim(self):
print('=' * 100)
print('二、计算电影的相似矩阵......')
# 建立movies_popular字典
print('-' * 35 + '1.计算电影的流行度字典movie——popular...' + '-' * 26)
for user, movies in self.trainSet.items():
for movie in movies:
"""
若该movie没在movies_popular字典中,则把其插入字典并赋值为0,否则+1,
最终的movie_popular字典键为电影名,值为所有用户总的观看数
"""
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
else:
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
# print(self.movie_popular)
print("训练集中电影总数 = %d" % self.movie_count)
print('-' * 35 + '2.建立电影联系矩阵... ' + '-' * 43)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
"""
下面三步的作用是:
分别将每个用户看过的每一部电影与其他所有电影的联系值置1,若之后又有用户同时看了两部电影, 则+1
"""
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print("建立电影的相似矩阵成功!")
# print("矩阵进行相似计算前movieId=1的一行为:")
# print(self.movie_sim_matrix['1'])
# 计算电影之间的相似性
print('-' * 35 + '3.计算最终的相似矩阵... ' + '-' * 40)
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为 0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('计算电影的相似矩阵成功!')
3.3 预测
计算用户u对外拍哪个j的兴趣:
根据物品的相似度和用户的历史行为给用户生成推荐列表
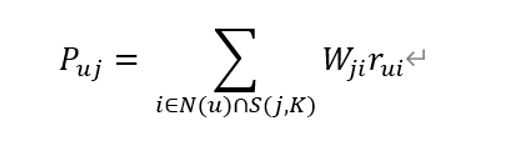
Puj:表示用户 u 对物品 j 的兴趣。
N(u):表示用户喜欢的物品集合(i:用户喜欢的某一个物品)。
S(i, k):表示和物品 i 最相似的 k 个物品集合( j 是这个集合中的某一个物品)。
Wji:表示物品 j 和 i 的相似度。
Rui:表示用户 u 对物品 i 的兴趣。
计算结果:和用户历史上感兴趣的物品越相似的物品,越可能得到高的排名。
def recommend(self, user):
K = int(self.n_sim_movie)
N = int(self.n_rec_movie)
rank = {}
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
"""
对目标用户每一部看过的电影,从相似电影矩阵中取与这部电影关联值最大的前K部电影,
若这K部电影用户之前没有看过,则把它加入rank字典中,其键为movieid名,
其值(即推荐度)为w(相似电影矩阵的值)与rating(用户给出的每部电影的评分)的乘积
"""
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
# 计算推荐度
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
4 UserCF和itemCF的比较
- User代表网站:新闻网站
- ItemCF代表网站:图书、电商、电影
从原理上:
UserCF给用户推荐那些和他们有共同兴趣安好的用户喜欢的物品。
ItemCF给用户推荐那些和他喜欢的物品类似的物品。
从原理角度可以看出,UserCF的推荐更社会化,反应了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反应了用户自己的兴趣传承。
UserCF可以给用户推荐和他有相似爱好的一群塔器用户今天都在看的新闻,这样在抓住任店和时效性的同时,保证了一定程度的个性化。同时,在新闻网站中,物品的更新速度远远快于新用户的加入速度,而却对于新用户,完全可以推荐最热门的新闻,因此UserCF利更大。
但是在图书、电商网站中,用户的兴趣是比较固定和持久的。技术人员往往会购买专业书籍,但是很多优质数据并不是热门书籍,所以ItemCF算法非常适合。
一天更新一次,对网站压力会较小,但是,需要维护物品的相似性矩阵,需要更多存储空间。
| User-based | Item-based | |
|---|---|---|
| 性能 | 适合用户较少,否则计算用户相似举证代价大 | 适用于武平数量明显小于用户数的场合,反之,计算物品相似度代价大 |
| 领域 | 时效性强,用户个性化兴趣不太明显的领域 | 用户个性化需求强的领域 |
| 冷启动 | 新用户对很少的物品产生行为后,不能建立对她进行个性化推荐,因为用户相似度表是每隔一段时间离线计算的,新物品上线后一段时间,一旦有用户对物品产生行为,就可以将新物品推荐给和她产生行为的用户兴趣相似的其他用户 | 新用户只要对一个物品产生行为,就可以给他推荐与该物品相关的其他物品,但没有办法在不离线更新物品相似度表的情况下新物品推荐给用户 |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户推荐解释,可以令用户比较信服 |
参考地址:
https://www.jianshu.com/p/a21944550656
https://blog.csdn.net/qq_40965177/article/details/106636012
https://blog.csdn.net/qq_35704904/article/details/103031962
https://blog.csdn.net/yeruby/article/details/44154009