数据科学导论大作业:数模国赛C题(古代玻璃文物分类)
本来只是学习阶段的一次大作业,但是自己毕竟苦苦搜寻学习了好几天.不在这个世界上留下点记录觉得对不起自己的劳动成果(不是).于是乎有了这篇文章.顺带当作业报告写一写.
一、问题重述
2022年高教社杯全国大学生数学建模竞赛C题
【1】项目背景
2022全国大学生数学建模竞赛论文展示 - 中国大学生在线
【2】问题重述: 古代玻璃制品的成分分析与鉴别
丝绸之路是古代中西方文化交流的通道, 其中玻璃是早期贸易往来的宝贵物证. 早期的玻璃在西亚和埃及地区常被制作成珠形饰品传入我国, 我国古代玻璃吸收其技术后在本土就地取材制作, 因此与外来的玻璃制品外观相似, 但化学成分却不相同.
玻璃的主要原料是石英砂, 主要化学成分是二氧化硅(SiO2). 由于纯石英砂的熔点较高, 为了降低熔化温度, 在炼制时需要添加助熔剂. 古代常用的助熔剂有草木灰、天然泡碱、硝石和铅矿石等, 并添加石灰石作为稳定剂, 石灰石煅烧以后转化为氧化钙(CaO). 添加的助熔剂不同, 其主要化学成分也不同. 例如, 铅钡玻璃在烧制过程中加入铅矿石作为助熔剂, 其氧化铅(PbO)、氧化钡(BaO)的含量较高, 通常被认为是我国自己发明的玻璃品种, 楚文化的玻璃就是以铅钡玻璃为主. 钾玻璃是以含钾量高的物质如草木灰作为助熔剂烧制而成的, 主要流行于我国岭南以及东南亚和印度等区域.
古代玻璃极易受埋藏环境的影响而风化. 在风化过程中, 内部元素与环境元素进行大量交换, 导致其成分比例发生变化, 从而影响对其类别的正确判断. 如图1的文物标记为表面无风化, 表面能明显看出文物的颜色、纹饰, 但不排除局部有较浅的风化;图2的文物标记为表面风化, 表面大面积灰黄色区域为风化层, 是明显风化区域, 紫色部分是一般风化表面. 在部分风化的文物中, 其表面也有未风化的区域.
现有一批我国古代玻璃制品的相关数据, 考古工作者依据这些文物样品的化学成分和其他检测手段已将其分为高钾玻璃和铅钡玻璃两种类型. 附件表单1给出了这些文物的分类信息, 附件表单2给出了相应的主要成分所占比例(空白处表示未检测到该成分). 这些数据的特点是成分性, 即各成分比例的累加和应为100%, 但因检测手段等原因可能导致其成分比例的累加和非100%的情况. 本题中将成分比例累加和介于85%~105%之间的数据视为有效数据.
请依据附件中的相关数据进行分析建模, 解决以下问题:
问题1 对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析; 结合玻璃的类型, 分析文物样品表面有无风化化学成分含量的统计规律, 并根据风化点检测数据, 预测其风化前的化学成分含量.
问题2 依据附件数据分析高钾玻璃、铅钡玻璃的分类规律; 对于每个类别选择合适的化学成分对其进行亚类划分, 给出具体的划分方法及划分结果, 并对分类结果的合理性和敏感性进行分析.
问题3 对附件表单3中未知类别玻璃文物的化学成分进行分析, 鉴别其所属类型, 并对分类结果的敏感性进行分析.
问题4 针对不同类别的玻璃文物样品, 分析其化学成分之间的关联关系, 并比较不同类别之间的化学成分关联关系的差异性.
二:简述
三:过程记录
所有的代码和需要用到的数据集将会在文末放一个打包好的云盘连接.
1.数据预处理
题目中提到,化学成分(表单二)中的化学成分是具有成分性的.不在规定范围内的数据是无效数据.简单的利用Excel拉一个求和,筛选一下不在80-105范围内的数据直接删除即可.
表单2中15,17为无效数据,直接删除√
再次观察化学成分表单,发现里面有很多空缺值.根据题目可得这些空缺成分是无法检出或者不含有该化学成分.官网中的示范论文有的将这些空缺成分进行了填补,目的在于补全因为仪器限制没有检出的微量化学成分.笔者并不决定这样做.理由在于对文物化学成分的检测属于一种实验,数据应该充分反应实验的实际结果.没有检出就是没有检出,用别的算法去填补空缺数据并非一个尊重事实的方法.故笔者在此对所有的空缺化学成分补0.
观察表单1,可以发现颜色项有四个空缺值.初步想法是利用sklearn里的随机森林进行模型填补.
但是用随机森林建立模型之后发现仍然有两个缺失值无法被模型填补.所以有理由怀疑模型填补的合理性.在观察数据集之后发现,所有有颜色缺失的项目风化状况全是"风化".根据以上结果,合理猜测很有可能是文物风化严重使得颜色无法识别.故对缺失的颜色填补"无法识别"项.
这里进行模型填补的努力失败再次印证了对实验数据(数据来源客观可靠,粗心大意错误出现频率很小的数据集)进行算法填补的不合理性.
对于成分数据,其累加和应该是100%.但是受到检测手段限制,有效数据里的成分并非100%.于是利用等比例转换,将所有的成分数据化为定和为100%的数据.具体做法是累加每一行的数据,并把该行每一列的数据除以行累加和.
2.四个小题的完成笔记
第一题:
总共被我分为了三个小部分:
(1)对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析建立分类模型
(2)结合玻璃的类型, 分析文物样品表面有无风化化学成分含量的统计规律
(3)并根据风化点检测数据, 预测其风化前的化学成分含量
对于第一第二小问,笔者使用的数据集是经过表单1和经过合并处理的表单1和表单2.因为要结合表单1的类型和表单2的化学成分共同建模.
第一小问
表单一中有所有文物的大体信息.包括纹饰,颜色,玻璃所属大类和是否表面风化.其中列出的文物有一部分在表单二里没有.于是在合并数据集中删除表单1中的该文物.于此同时,表单2中有一些单个文物的多个采样点,在复制表单一的时候进行了行的复制操作.对于风化情况,未风化用0代替,风化用1代替,严重风化用2代替.结合之后的数据集如下:
<待上传文件:class_weathering_chemical.csv>
随后我们以斯皮尔曼相关系数作为标准绘制所有变量之间的相关性热力图,并参考假设检验表(取n=60,显著性水平0.05)对热力图中没有95%把握断定两变量相关的格子用白色覆盖.绘制该图的目的是初步观察表单1中变量间的相关情况.由于邻接矩阵是对称的,所以观察下三角就可以了.
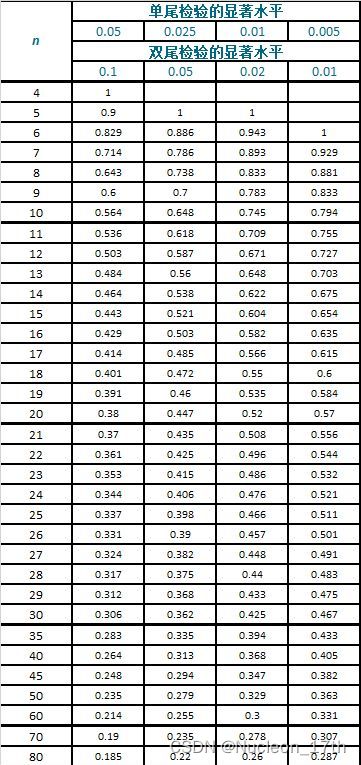
相关系数假设检验临界值
对应的热力图展示如下.白色缺失区域的相关系数不满足95%置信度,故不予显示

从图中可以初步看出:
1.纹饰A:跟纹饰C存在强负相关,跟深绿色存在弱负相关
2.纹饰B:跟纹饰C存在负相关,跟铅钡玻璃存在负相关,和无风化存在弱负相关,与高钾玻璃存在正相关,跟蓝绿色存在正相关,和风化存在弱正相关
3.纹饰C:和蓝绿色存在负相关,和深绿色存在正相关.
4.铅钡类型:更容易风化
5.高钾类型:不容易风化
6.浅蓝色:跟蓝绿色存在负相关
初步观察完相关系数之后我们着手建模.笔者选择了决策树对数据进行分类.在建立决策树之前,为了防止过拟合,除了算法中自带的剪枝之外,还需要限制决策树的深度.结合数据集大小,我们对可能的决策树深度[1,16)进行网格搜索调参.使用sklearn包中的GridSearchCV进行网格搜索和交叉验证.使用网格搜索交叉验证出的最优决策树深度进行决策树的训练.
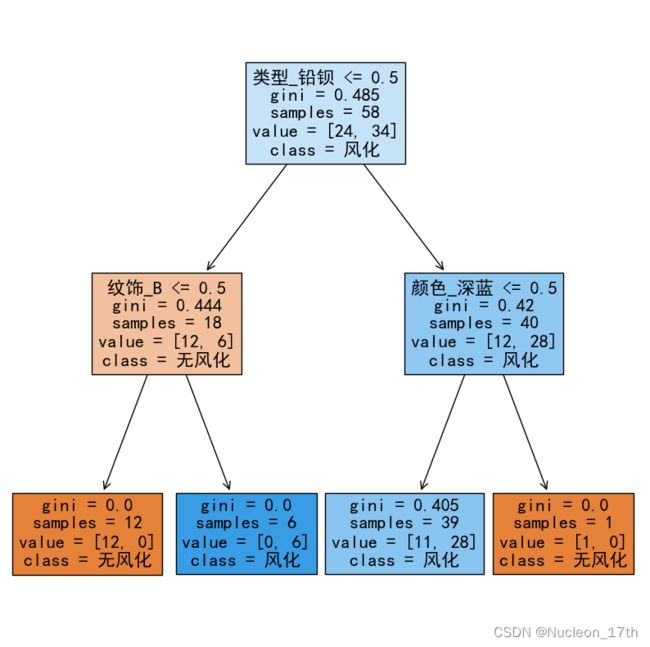
网格搜索结论是决策树深度为2的时候交叉验证准确率较高,为0.7030.选择决策树深度2建立决策树.在训练完模型之后from sklearn.tree import plot_tree进行决策树可视化,可视化结果如图:
多次运行下来决策树的右枝条会有变化.变化如图:
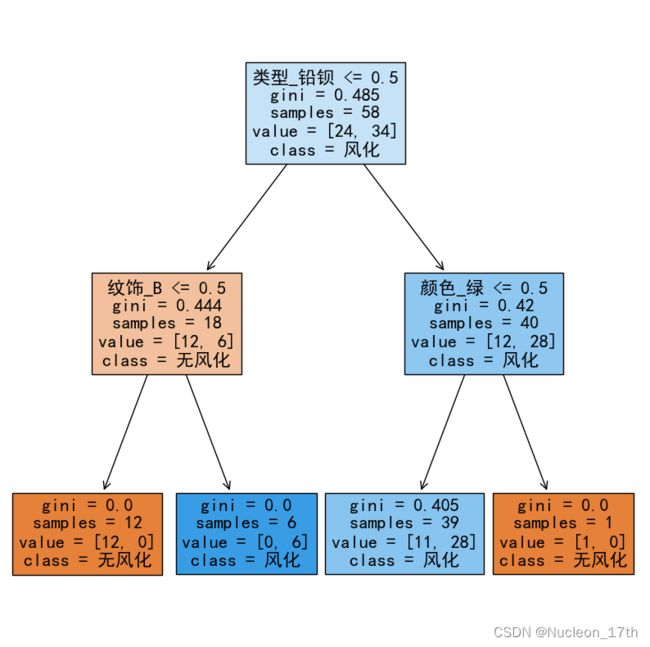
从树图中可以看出,右边枝条其实对风化情况的区分并不明显.附加的颜色条件最多只能区分1个样本.这一点也符合热力图分析.而玻璃类型对风化与否的区分较为明显.值得注意的是,在高钾玻璃中纹饰B全部风化.热力图中我们也无法拒绝纹饰B和风化之间的关系.
综上所述,我们认为风化情况主要跟玻璃类别有关.铅钡玻璃更容易风化,高钾玻璃中纹饰B更容易风化.风化与否与颜色并无较大关联,在除高钾玻璃之外,风化与否与纹饰也并没有较大关联.
第一小问所有代码:
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV # 通过网格方式来搜索参数
from sklearn import tree
from matplotlib import pyplot as plt
import matplotlib
font = {#中文绘图
'family':'SimHei',
'weight':'bold',
'size':12
}
matplotlib.rc("font", **font)
import seaborn as sns
data = pd.read_csv("表单1.csv")#导入数据集
features = ["文物编号","纹饰","类型","颜色"]
X = data[features]#设置待估Xy
y = data["表面风化"]
X.set_index("文物编号",inplace=True)#更改索引
features = ["纹饰","类型","颜色"]
plt.figure(figsize=[15, 10])#生成热力图,初步观察变量相关情况
sns.heatmap(pd.get_dummies(data[["纹饰","类型","颜色","表面风化"]]).corr(method='spearman'),cmap="Greens",mask=abs(pd.get_dummies(data[["纹饰","类型","颜色","表面风化"]]).corr(method='spearman').corr(method='spearman'))<0.279, linewidths=0.5, annot=True)
plt.show()
X = pd.get_dummies(X[features])#onehot
# 设置需要搜索的参数值,在这里寻找最优的决策树深度
parameters = {'max_depth':[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]}
model = tree.DecisionTreeClassifier() # 注意:在这里不用指定参数
# GridSearchCV
clf = GridSearchCV(model, parameters, cv=5)
clf.fit(X, y)
# 输出最好的参数以及对应的准确率
print ("best score is: %.4f"%clf.best_score_, " best param: ",clf.best_params_,)
model = tree.DecisionTreeClassifier(max_depth=2)
model = model.fit(X, y)
fig = plt.figure(figsize=(10,10))
class_names = ["无风化","风化"]
from sklearn.tree import plot_tree # 树图
plot_tree(
model,
feature_names = X.columns,
class_names= class_names,
filled=True,
)第二小问
(2)结合玻璃的类型, 分析文物样品表面有无风化化学成分含量的统计规律
在这里我仍然选择使用热力图先初步观察一下.过程同第一小问.

从图中可以发现明显的相关关系.正值代表正相关,负值代表负相关.绝对值越接近1,越接近线性相关.越接近0,关系越小.
由于该题询问的是统计规律,所以我们使用Excel进行描述统计分析.题目要求结合玻璃类型进行分析,于是我们把数据分为四组:高钾风化,高钾不风化,铅钡风化,铅钡不风化.在此笔者只对高钾风化玻璃文物的描述统计进行文字分析.其余的描述统计和图表参考文件:
<待上传的文件:四分组化学成分描述统计.xlsx>

上图展示了高钾风化玻璃数据集和其描述统计量.其中有整列为0的统计量是由化学成分缺失导致的.用到了一些不常用的统计量:偏度系数和峰度系数 .具体描述参考链接,我们直接进行描述统计:
从平均值角度,SiO2在玻璃中占比毫无疑问的最大,它是所有玻璃的主成分.别的所有微量成分的占比都在2%以下.
从峰度系数角度,二氧化硅,氧化钾,氧化镁,三氧化二铁四个组分的峰度系数为负,说明这四个组分的分布比正态分布更平缓,两侧具有较多的离散值.其余组分峰度系数为正,说明其分布比正态分布更陡峭,两侧"尾巴"比较瘦,分布更集中.
从偏度系数角度,二氧化硅,氧化钙,氧化镁,三氧化二铝,氧化铜成正偏态,指示该成分分布中有右长尾,可能存在离对应化学成分均值较远,较大的成分.其余成分分布偏左,体现出可能具有距离对应化学成分均值较远较小的化学成分.
然后对高钾玻璃的各个成分进行可视化.由相关系数可知,二氧化硅是随着风化而流失的.但风化后二氧化硅占比反而上升,说明微量成分更容易流失.
考虑到二氧化硅占比巨大,于是在微量成分分析之中去掉了二氧化硅.

对于微量元素分析发现风化前后有部分微量元素从图表中消失.他们是氧化钾,氧化镁.根据相关系数,它们可能是在风化过程中完全流失了.结合峰度系数和相关系数分析可以猜测风化进程使得随风化流失的成分分布变得极端.而氧化铜,三氧化二铝这样的成分可能不容易流失,尤其是三氧化二铝可能具有抗风化作用.所以占比变大.
在做第三小题的时候,顺便使用第三小题的岭回归模型去试探性探索了风化程度,玻璃类型和化学成分之间的定量关系:
1. 高钾,铅钡和风化程度是自变量,各个化学成分是因变量.
在线性模型中,负号指示对自变量有负贡献.,正指示对自变量有正贡献,系数矩阵如下:
回归截距
(高钾)rich_k 0.6396314
(铅钡)PbBa 0.3603686
(风化)weathering 0.4576642
高钾 铅钡 风化程度
SiO2 0.04857851 -0.04857851 -0.02583662
Na2O -3.66590529 3.66590529 -5.57513205
K2O 3.97230658 -3.97230658 -1.60494187
CaO 0.00000000 0.00000000 0.00000000
MgO -0.73045301 0.73045301 -1.92845812
Al2O3 -1.91151436 1.91151436 -1.82996762
Fe2O3 -0.10065749 0.10065749 -6.48401062
CuO 1.18870830 -1.18870830 1.11851119
PbO -1.00796999 1.00796999 0.75990028
BaO -1.51898888 1.51898888 -0.88100097
P2O5 -0.27666001 0.27666001 4.06530995
SrO 0.00000000 0.00000000 0.00000000
SnO2 0.00000000 0.00000000 0.00000000
SO2 0.74433109 -0.74433109 6.83425779
从该矩阵可以看出线性模型如何分出高钾和铅钡两类玻璃,并能够表现出各个化学成分对风化程度的贡献.该矩阵与相关性系数热力图互相验证.
2.高钾玻璃各个成分作为自变量,风化程度作为因变量岭回归的系数矩阵:
回归截距
0.3591105
风化程度
SiO2 0.5155128
Na2O -1.7055526
K2O -1.5235123
CaO -1.6537503
MgO -5.6838663
Al2O3 -1.8538162
Fe2O3 -1.0543517
CuO -0.5243118
PbO -6.3371961
BaO -3.1674837
P2O5 -2.3377587
SrO -24.2124372
SnO2 -8.6608621
SO2 -18.8954178
3.铅钡玻璃各个成分作为自变量,风化程度作为因变量岭回归的系数矩阵:
回归截距
0.5840007
风化程度
SiO2 -1.3158729
Na2O -1.8380630
K2O -16.6983000
CaO -6.9069850
MgO 5.1302300
Al2O3 2.0967995
Fe2O3 -4.1001075
CuO 0.3635241
PbO 1.4328986
BaO -0.2036333
P2O5 4.1038535
SrO -14.5897249
SnO2 36.3990629
SO2 6.4818275
从2,3两个系数矩阵可以发现,铅钡玻璃和高钾玻璃之间有明显不同的风化进程.
用到的R代码如下,需要注意的是笔者在这里使用了很多共用的变量,所以这三个模型需要依次分块执行,不能一次全部运行,否则得到的结果将是最后一个模型的结果.
library(foreign)
library(glmnet)
class_weathering_chemical <- read.csv("./class_weathering_chemical.csv")
#####完全多变量回归#####
x <- as.matrix(class_weathering_chemical[,c(-1,-16:-18)])#定义回归自变量因变量
y <- as.matrix(class_weathering_chemical[,c(16:18)])
fit <- glmnet(x,y,"mgaussian",nlambda = 1000,alpha=1)#为了查看变量影响因素而进行的回归
plot(fit, xvar="lambda", label=TRUE)
lasso_fit <- cv.glmnet(x,y,family="mgaussian",alpha=1,type.measure = "mse",nlambda=1000)#交叉验证,最佳lambda
plot(lasso_fit)
lasso_best <- glmnet(x,y,family="mgaussian",alpha = 1,lambda = lasso_fit$lambda.min)#用λmin建立预测模型
lasso_best$a0#回归截距
k <- as.matrix(lasso_best$beta$rich_k)
k <- cbind(k,as.numeric(lasso_best$beta$PbBa))
k <- cbind(k,as.numeric(lasso_best$beta$weathering))
k <- as.data.frame(k)
names(k) <- c("高钾","铅钡","风化程度")#k为回归系数矩阵
print(k)
#####高钾玻璃的风化情况#####
richK_weathering_chemical <- read.csv("./richK_weathering_chemical.csv")
x <- as.matrix(richK_weathering_chemical[,c(-1,-16)])#定义回归自变量因变量
y <- as.matrix(richK_weathering_chemical[,16])#风化程度
fit <- glmnet(x,y,"gaussian",nlambda = 1000,alpha=0)#为了查看变量影响因素而进行的回归
plot(fit, xvar="lambda", label=TRUE)
lasso_fit <- cv.glmnet(x,y,family="gaussian",alpha=0,type.measure = "mse",nlambda=1000)#交叉验证,最佳lambda
plot(lasso_fit)
lasso_best <- glmnet(x,y,family="gaussian",alpha = 0,lambda = lasso_fit$lambda.min)#用λmin建立预测模型
lasso_best$a0#回归截距
k <- as.data.frame(as.matrix(lasso_best$beta))
names(k) <- "风化程度(0-2)"
print(k)
#####铅钡玻璃的风化情况#####
PbBa_weathering_chemical <- read.csv("./PbBa_weathering_chemical.csv")
x <- as.matrix(PbBa_weathering_chemical[,c(-1,-16)])#定义回归自变量因变量
y <- as.matrix(PbBa_weathering_chemical[,16])#风化程度
fit <- glmnet(x,y,"gaussian",nlambda = 1000,alpha=0)#为了查看变量影响因素而进行的回归
plot(fit, xvar="lambda", label=TRUE)
lasso_fit <- cv.glmnet(x,y,family="gaussian",alpha=0,type.measure = "mse",nlambda=1000)#交叉验证,最佳lambda
plot(lasso_fit)
lasso_best <- glmnet(x,y,family="gaussian",alpha = 0,lambda = lasso_fit$lambda.min)#用λmin建立预测模型
lasso_best$a0#回归截距
k <- as.data.frame(as.matrix(lasso_best$beta))
names(k) <- "风化程度(0-2)"
print(k)第三小问
(3)根据风化点检测数据, 预测其风化前的化学成分含量
根据待预测对象的性质,并参考下面这张著名的sklearn cheat-sheet,笔者选择了岭回归模型对化学成分进行预测.

本题我们结合表单1和表单2之中的信息,以纹饰,风化程度,颜色,作为自变量,化学成分作为因变量
结合玻璃的类型,我们对大集合进行了划分.在预测风化前成分的时候,分为高钾和铅钡两类分别进行预测.我们导入数据,里面有风化和无风化的数据.提取所有的数据作为训练集;提取出所有的风化后的文物数据作为待预测的集合,并把预测集合的所有的风化程度设置为0.
铅钡玻璃风化前成分预测结果: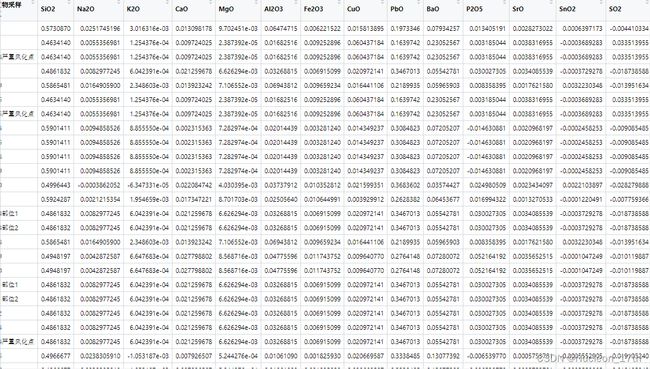
笔者在这里遇到了一些仍没有解决的问题:就是虽然预测之后的成分结果仍然是定和为1的,但是出现了负成分的数字.虽然可以直接将负成分去掉并把所有的成分重新定和,但我并不确定这样的做法靠不靠谱.别的预测结果可以通过运行代码直接执行出来,目前我还没有专门去保存.
第三小问代码如下:
library(foreign)
library(glmnet)
##########高钾玻璃的风化前预测##########
#####数据准备#####
rich_K_weathering_chemical <- read.csv("./predict_b4_weathering.csv")
rich_K_train <- data.frame()#划分训练集与测试集.有风化的做测试集,并把风化位置为0后作为预测集
for (i in c(1:nrow(rich_K_weathering_chemical))) {#从大集合中取出高钾玻璃作为训练集
if(rich_K_weathering_chemical[i,"rich_k"] == 1){
rich_K_train <- rbind(rich_K_train,rich_K_weathering_chemical[i,])
}
}
rich_K_predict <- data.frame()
for (i in c(1:nrow(rich_K_train))) {#从训练集中取出有风化的作为测试集,并把风化程度置为0
if(rich_K_train[i,"weathering"] != 0){
rich_K_predict <- rbind(rich_K_predict,rich_K_train[i,])
}
}
rich_K_predict[,"weathering"] <- 0#并把风化程度置为0
train_y <- as.matrix(rich_K_train[,2:15])#定义回归训练自变量因变量
train_x <- as.matrix(rich_K_train[,16:30])#自变量
#####模型拟合#####
fit <- glmnet(train_x,train_y,"mgaussian",nlambda = 1000,alpha=0)#为了查看变量影响因素而进行的回归
plot(fit, xvar="lambda", label=TRUE)
lasso_fit <- cv.glmnet(train_x,train_y,family="mgaussian",alpha=0,type.measure = "mse",nlambda=1000)#交叉验证,最佳lambda
plot(lasso_fit)
lasso_best <- glmnet(train_x,train_y,family="mgaussian",alpha = 0,lambda = lasso_fit$lambda.min)#用λmin建立预测模型
#####模型预测#####
#定义回归预测自变量
predict_x <- as.matrix(rich_K_predict[,16:30])#自变量
predict_result <- as.data.frame(predict(lasso_best,predict_x))#进行预测
predict_result <- cbind(rich_K_predict[,1],predict_result)#优化预测表格格式
names(predict_result) <- names(rich_K_predict[,1:15])
#print(predict_result)
##########铅钡玻璃的风化前预测##########
#####数据准备#####
PbBa_weathering_chemical <- read.csv("./predict_b4_weathering.csv")
PbBa_train <- data.frame()#划分训练集与测试集.有风化的做测试集,并把风化位置为0后作为预测集
for (i in c(1:nrow(PbBa_weathering_chemical))) {#从大集合中取出铅钡玻璃作为训练集
if(PbBa_weathering_chemical[i,"PbBa"] == 1){
PbBa_train <- rbind(PbBa_train,PbBa_weathering_chemical[i,])
}
}
PbBa_predict <- data.frame()
for (i in c(1:nrow(PbBa_train))) {#从训练集中取出有风化的作为测试集,并把风化程度置为0
if(PbBa_train[i,"weathering"] != 0){
PbBa_predict <- rbind(PbBa_predict,PbBa_train[i,])
}
}
PbBa_predict[,"weathering"] <- 0#并把风化程度置为0
train_y <- as.matrix(PbBa_train[,2:15])#定义回归训练自变量因变量
train_x <- as.matrix(PbBa_train[,16:30])#自变量
#####模型拟合#####
fit <- glmnet(train_x,train_y,"mgaussian",nlambda = 1000,alpha=0)#为了查看变量影响因素而进行的回归
plot(fit, xvar="lambda", label=TRUE)
lasso_fit <- cv.glmnet(train_x,train_y,family="mgaussian",alpha=0,type.measure = "mse",nlambda=1000)#交叉验证,最佳lambda
plot(lasso_fit)
lasso_best <- glmnet(train_x,train_y,family="mgaussian",alpha = 0,lambda = lasso_fit$lambda.min)#用λmin建立预测模型
#####模型预测#####
#定义回归预测自变量
predict_x <- as.matrix(PbBa_predict[,16:30])#自变量
predict_result <- as.data.frame(predict(lasso_best,predict_x))#进行预测
predict_result <- cbind(PbBa_predict[,1],predict_result)#优化预测表格格式
names(predict_result) <- names(PbBa_predict[,1:15])
#print(predict_result)第二题
笔者参考了他人第二大题的思路进行建模.第二大题被我分成如下三问:
(1)依据附件数据分析高钾玻璃、铅钡玻璃的分类规律;
(2)对于每个类别选择合适的化学成分对其进行亚类划分, 给出具体的划分方法及划分结果;
(3)并对分类结果的合理性和进行分析;
在第二题,由于化学成分数据维数很高,无法直观的理解聚类之后的关系,直接聚类也可能出现维数灾难.故我首先使用PCA进行降维,随后使用Kmeans进行聚类,为集合打上亚类标签.但由于降维后的主成分不具有良好的可解释性,所以另外利用化学成分,使用决策树对分类标签进行监督学习,从而得到可视化的易于理解的分类标准.
第一小问
(有时间再继续写)
代码集&使用的数据集 <----点击这里
代码&数据集末次更新日期:2022年12月4日
提取码: dffm