带你玩转序列模型之seq2seq模型&定向(集束)搜索
目录
一.基础模型
二.选择最可能的句子
三.定向搜索
四.改进定向搜索
五.定向搜索的误差分析
一.基础模型
在这一周,你将会学习seq2seq(sequence to sequence)模型,从机器翻译到语音识别,它们都能起到很大的作用,从最基本的模型开始。之后你还会学习集束搜索(Beam search)和注意力模型(Attention Model),一直到最后的音频模型,比如语音。
现在就开始吧,比如你想通过输入一个法语句子,比如这句 “Jane visite I'Afrique en septembre.”,将它翻译成一个英语句子,“Jane is visiting Africa in September.”。和之前一样,我们用x^<1>一直到x^<5>来表示输入的句子的单词,然后我们用y^<1>到y^<6>来表示输出的句子的单词,那么,如何训练出一个新的网络来输入序列和输出序列呢?

这里有一些方法,这些方法主要都来自于两篇论文,作者是Sutskever,Oriol Vinyals 和 Quoc Le,另一篇的作者是Kyunghyun Cho,Bart van Merrienboer,Caglar Gulcehre,Dzmitry Bahdanau,Fethi Bougares,Holger Schwen 和 Yoshua Bengio。
首先,我们先建立一个网络,这个网络叫做编码网络(encoder network)(上图编号1所示),它是一个RNN的结构, RNN的单元可以是GRU 也可以是LSTM。每次只向该网络中输入一个法语单词,将输入序列接收完毕后,这个RNN网络会输出一个向量来代表这个输入序列。之后你可以建立一个解码网络,我把它画出来(上图编号2所示),它以编码网络的输出作为输入,编码网络是左边的黑色部分(上图编号1所示),之后它可以被训练为每次输出一个翻译后的单词,一直到它输出序列的结尾或者句子结尾标记,这个解码网络的工作就结束了。和往常一样我们把每次生成的标记都传递到下一个单元中来进行预测,就像之前用语言模型合成文本时一样。
深度学习在近期最卓越的成果之一就是这个模型确实有效,在给出足够的法语和英语文本的情况下,如果你训练这个模型,通过输入一个法语句子来输出对应的英语翻译,这个模型将会非常有效。这个模型简单地用一个编码网络来对输入的法语句子进行编码,然后用一个解码网络来生成对应的英语翻译。

还有一个与此类似的结构被用来做图像描述,给出一张图片,比如这张猫的图片(上图编号1所示),它能自动地输出该图片的描述,一只猫坐在椅子上,那么你如何训练出这样的网络?通过输入图像来输出描述,像这个句子一样。
方法如下,在之前的卷积网络课程中,你已经知道了如何将图片输入到卷积神经网络中,比如一个预训练的AlexNet结构(上图编号2方框所示),然后让其学习图片的编码,或者学习图片的一系列特征。现在幻灯片所展示的就是AlexNet结构,我们去掉最后的softmax单元(上图编号3所示),这个预训练的AlexNet结构会给你一个4096维的特征向量,向量表示的就是这只猫的图片,所以这个预训练网络可以是图像的编码网络。现在你得到了一个4096维的向量来表示这张图片,接着你可以把这个向量输入到RNN中(上图编号4方框所示),RNN要做的就是生成图像的描述,每次生成一个单词,这和我们在之前将法语译为英语的机器翻译中看到的结构很像,现在你输入一个描述输入的特征向量,然后让网络生成一个输出序列,或者说一个一个地输出单词序列。
事实证明在图像描述领域,这种方法相当有效,特别是当你想生成的描述不是特别长时。据我所知,这种模型首先是由Junhua Mao,Wei Xu,Yi Yang,Jiang Wang,Zhiheng Huang和Alan Yuille提出的,尽管有几个团队都几乎在同一时间构造出了非常相似的模型,因为还有另外两个团队也在同一时间得出了相似的结论。我觉得有可能Mao的团队和Oriol Vinyals,Alexander Toshev,Samy Bengio和Dumitru Erhan,还有Andrej Karpathy和Fei-Fei Yi是同一个团队。
现在你知道了基本的seq2seq模型是怎样运作的,以及image to sequence模型或者说图像描述模型是怎样运作的。不过这两个模型运作方式有一些不同,主要体现在如何用语言模型合成新的文本,并生成对应序列的方面。一个主要的区别就是你大概不会想得到一个随机选取的翻译,你想要的是最准确的翻译,或者说你可能不想要一个随机选取的描述,你想要的是最好的最贴切的描述,我们将在下节视频中介绍如何生成这些序列。
二.选择最可能的句子
在seq2seq机器翻译模型和我们在第一周课程所用的语言模型之间有很多相似的地方,但是它们之间也有许多重要的区别,让我们来一探究竟。
你可以把机器翻译想成是建立一个条件语言模型,在语言模型中上方是一个我们在第一周所建立的模型,这个模型可以让你能够估计句子的可能性,这就是语言模型所做的事情。你也可以将它用于生成一个新的句子,如果你在图上的该处(下图编号1所示),有x^<1>和x^<2>,那么在该例中x^<2>=yhat^<1>,但是x^<1>、x^<2>等在这里并不重要。为了让图片看起来更简洁,我把它们先抹去,可以理解x^<1>为是一个全为0的向量,然后x^<2>、x^<3>等都等于之前所生成的输出,这就是所说的语言模型。
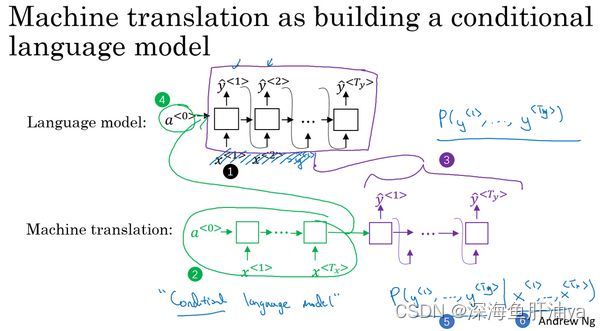
而机器翻译模型是下面这样的,我这里用两种不同的颜色来表示,即绿色和紫色,用绿色(上图编号2所示)表示encoder网络,用紫色(上图编号3所示)表示decoder网络。你会发现decoder网络看起来和刚才所画的语言模型几乎一模一样,机器翻译模型其实和语言模型非常相似,不同在于语言模型总是以零向量(上图编号4所示)开始,而encoder网络会计算出一系列向量(上图编号2所示)来表示输入的句子。有了这个输入句子,decoder网络就可以以这个句子开始,而不是以零向量开始,所以我把它叫做条件语言模型(conditional language model)。相比语言模型,输出任意句子的概率,翻译模型会输出句子的英文翻译(上图编号5所示),这取决于输入的法语句子(上图编号6所示)。换句话说,你将估计一个英文翻译的概率,比如估计这句英语翻译的概率,"Jane is visiting Africa in September.",这句翻译是取决于法语句子,"Jane visite I'Afrique en septembre.",这就是英语句子相对于输入的法语句子的可能性,所以它是一个条件语言模型。

现在,假如你想真正地通过模型将法语翻译成英文,通过输入的法语句子模型将会告诉你各种英文翻译所对应的可能性。x在这里是法语句子"Jane visite l'Afrique en septembre.",而它将告诉你不同的英语翻译所对应的概率。显然你不想让它随机地进行输出,如果你从这个分布中进行取样得到P(y|x),可能取样一次就能得到很好的翻译,"Jane is visiting Africa in September."。但是你可能也会得到一个截然不同的翻译,"Jane is going to be visiting Africa in September.",这句话听起来有些笨拙,但它不是一个糟糕的翻译,只是不是最好的而已。有时你也会偶然地得到这样的翻译,"In September, Jane will visit Africa.",或者有时候你还会得到一个很糟糕的翻译,"Her African friend welcomed Jane in September."。所以当你使用这个模型来进行机器翻译时,你并不是从得到的分布中进行随机取样,而是你要找到一个英语句子y(上图编号1所示),使得条件概率最大化。所以在开发机器翻译系统时,你需要做的一件事就是想出一个算法,用来找出合适的y值,使得该项最大化,而解决这种问题最通用的算法就是束搜索(Beam Search),你将会在下节课见到它。
不过在了解束搜索之前,你可能会问一个问题,为什么不用贪心搜索(Greedy Search)呢?贪心搜索是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型挑选出最有可能的第一个词进入你的机器翻译模型中,在挑选出第一个词之后它将会继续挑选出最有可能的第二个词,然后继续挑选第三个最有可能的词,这种算法就叫做贪心搜索,但是你真正需要的是一次性挑选出整个单词序列,从y^<1>、y^<2>到y^

第一串(上图编号1所示)翻译明显比第二个(上图编号2所示)好,所以我们希望机器翻译模型会说第一个句子的P(y|x)比第二个句子要高,第一个句子对于法语原文来说更好更简洁,虽然第二个也不错,但是有些啰嗦,里面有很多不重要的词。但如果贪心算法挑选出了"Jane is"作为前两个词,因为在英语中going更加常见,于是对于法语句子来说"Jane is going"相比"Jane is visiting"会有更高的概率作为法语的翻译,所以很有可能如果你仅仅根据前两个词来估计第三个词的可能性,得到的就是going,最终你会得到一个欠佳的句子,在P(y|x)模型中这不是一个最好的选择。
我知道这种说法可能比较粗略,但是它确实是一种广泛的现象,当你想得到单词序列y^<1>、y^<2>一直到最后一个词总体的概率时,一次仅仅挑选一个词并不是最佳的选择。当然,在英语中各种词汇的组合数量还有很多很多,如果你的字典中有10,000个单词,并且你的翻译可能有10个词那么长,那么可能的组合就有10,000的10次方这么多,这仅仅是10个单词的句子,从这样大一个字典中来挑选单词,所以可能的句子数量非常巨大,不可能去计算每一种组合的可能性。所以这时最常用的办法就是用一个近似的搜索算法,这个近似的搜索算法做的就是它会尽力地,尽管不一定总会成功,但它将挑选出句子y使得条件概率最大化,尽管它不能保证找到的值一定可以使概率最大化,但这已经足够了。
最后总结一下,在本视频中,你看到了机器翻译是如何用来解决条件语言模型问题的,这个模型和之前的语言模型一个主要的区别就是,相比之前的模型随机地生成句子,在该模型中你要找到最有可能的英语句子,最可能的英语翻译,但是可能的句子组合数量过于巨大,无法一一列举,所以我们需要一种合适的搜索算法,让我们在下节课中学习集束搜索。
三.定向搜索
也可以叫做集束搜索。
这节视频中你会学到集束搜索(beam search)算法,上节视频中我们讲了对于机器翻译来说,给定输入,比如法语句子,你不会想要输出一个随机的英语翻译结果,你想要一个最好的,最可能的英语翻译结果。对于语音识别也一样,给定一个输入的语音片段,你不会想要一个随机的文本翻译结果,你想要最好的,最接近原意的翻译结果,集束搜索就是解决这个最常用的算法。这节视频里,你会明白怎么把集束搜索算法应用到你自己的工作中,就用我们的法语句子的例子来试一下集束搜索吧。
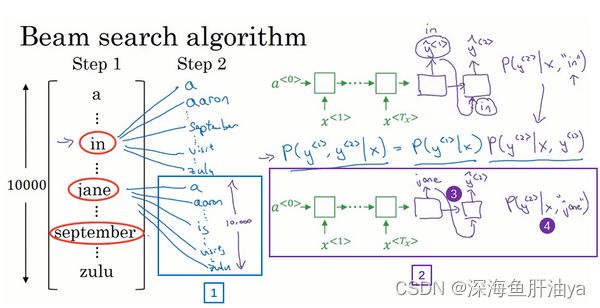
“Jane visite l'Afrique en Septembre.”(法语句子),我们希望翻译成英语,"Jane is visiting Africa in September".(英语句子),集束搜索算法首先做的就是挑选要输出的英语翻译中的第一个单词。这里我列出了10,000个词的词汇表(下图编号1所示),为了简化问题,我们忽略大小写,所有的单词都以小写列出来。在集束搜索的第一步中我用这个网络部分,绿色是编码部分(下图编号2所示),紫色是解码部分(下图编号3所示),来评估第一个单词的概率值,给定输入序列
x,即法语作为输入,第一个输出y的概率值是多少。

贪婪算法只会挑出最可能的那一个单词,然后继续。而集束搜索则会考虑多个选择,集束搜索算法会有一个参数B,叫做集束宽(beam width)。在这个例子中我把这个集束宽设成3,这样就意味着集束搜索不会只考虑一个可能结果,而是一次会考虑3个,比如对第一个单词有不同选择的可能性,最后找到in、jane、september,是英语输出的第一个单词的最可能的三个选项,然后集束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。如果集束宽设的不一样,如果集束宽这个参数是10的话,那么我们跟踪的不仅仅3个,而是10个第一个单词的最可能的选择。所以要明白,为了执行集束搜索的第一步,你需要输入法语句子到编码网络,然后会解码这个网络,这个softmax层(上图编号3所示)会输出10,000个概率值,得到这10,000个输出的概率值,取前三个存起来。
让我们看看集束搜索算法的第二步,已经选出了in、jane、september作为第一个单词三个最可能的选择,集束算法接下来会针对每个第一个单词考虑第二个单词是什么,单词in后面的第二个单词可能是a或者是aaron,我就是从词汇表里把这些词列了出来,或者是列表里某个位置,september,可能是列表里的 visit,一直到字母z,最后一个单词是zulu(下图编号1所示)。

为了评估第二个词的概率值,我们用这个神经网络的部分,绿色是编码部分(上图编号2所示),而对于解码部分,当决定单词in后面是什么,别忘了解码器的第一个输出y^<1>,我把y^<1>设为单词in(上图编号3所示),然后把它喂回来,这里就是单词in(上图编号4所示),因为它的目的是努力找出第一个单词是in的情况下,第二个单词是什么。这个输出就是y^<2>(上图编号5所示),有了这个连接(上图编号6所示),就是这里的第一个单词in(上图编号4所示)作为输入,这样这个网络就可以用来评估第二个单词的概率了,在给定法语句子和翻译结果的第一个单词in的情况下。
注意,在第二步里我们更关心的是要找到最可能的第一个和第二个单词对,所以不仅仅是第二个单词有最大的概率,而是第一个、第二个单词对有最大的概率(上图编号7所示)。按照条件概率的准则,这个可以表示成第一个单词的概率(上图编号8所示)乘以第二个单词的概率(上图编号9所示),这个可以从这个网络部分里得到(上图编号10所示),对于已经选择的in、jane、september这三个单词,你可以先保存这个概率值(上图编号8所示),然后再乘以第二个概率值(上图编号9所示)就得到了第一个和第二个单词对的概率(上图编号7所示)。


针对第二个单词所有10,000个不同的选择,最后对于单词september也一样,从单词a到单词zulu,用这个网络部分,我把它画在这里。来看看如果第一个单词是september,第二个单词最可能是什么。所以对于集束搜索的第二步,由于我们一直用的集束宽为3,并且词汇表里有10,000个单词,那么最终我们会有3乘以10,000也就是30,000个可能的结果,因为这里(上图编号1所示)是10,000,这里(上图编号2所示)是10,000,这里(上图编号3所示)是10,000,就是集束宽乘以词汇表大小,你要做的就是评估这30,000个选择。按照第一个词和第二个词的概率,然后选出前三个,这样又减少了这30,000个可能性,又变成了3个,减少到集束宽的大小。假如这30,000个选择里最可能的是“in September”(上图编号4所示)和“jane is”(上图编号5所示),以及“jane visits”(上图编号6所示),画的有点乱,但这就是这30,000个选择里最可能的三个结果,集束搜索算法会保存这些结果,然后用于下一次集束搜索。
注意一件事情,如果集束搜索找到了第一个和第二个单词对最可能的三个选择是“in September”或者“jane is”或者“jane visits”,这就意味着我们去掉了september作为英语翻译结果的第一个单词的选择,所以我们的第一个单词现在减少到了两个可能结果,但是我们的集束宽是3,所以还是有
y^<1>,y^<2>对的三个选择。
在我们进入集束搜索的第三步之前,我还想提醒一下因为我们的集束宽等于3,每一步我们都复制3个,同样的这种网络来评估部分句子和最后的结果,由于集束宽等于3,我们有三个网络副本(上图编号7所示),每个网络的第一个单词不同,而这三个网络可以高效地评估第二个单词所有的30,000个选择。所以不需要初始化30,000个网络副本,只需要使用3个网络的副本就可以快速的评估softmax的输出,即y^<2>的10,000个结果。
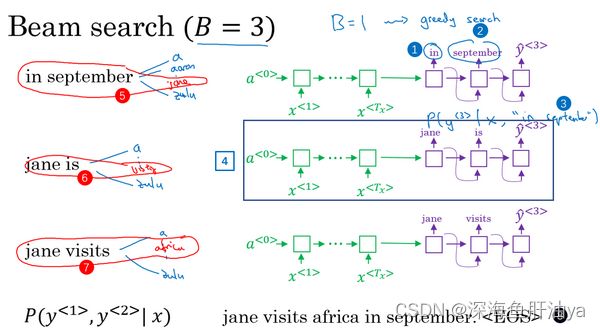
让我们快速解释一下集束搜索的下一步,前面说过前两个单词最可能的选择是“in September”和“jane is”以及“jane visits”,对于每一对单词我们应该保存起来,给定输入x,即法语句子作为x的情况下,y^<1>和y^<2>的概率值和前面一样,现在我们考虑第三个单词是什么,可以是“in September a”,可以是“in September aaron”,一直到“in September zulu”。为了评估第三个单词可能的选择,我们用这个网络部分,第一单词是in(上图编号1所示),第二个单词是september(上图编号2所示),所以这个网络部分可以用来评估第三个单词的概率,在给定输入的法语句子x和给定的英语输出的前两个单词“in September”情况下(上图编号3所示)。对于第二个片段来说也一样,就像这样一样(上图编号4所示),对于“jane visits”也一样,然后集束搜索还是会挑选出针对前三个词的三个最可能的选择,可能是“in september jane”(上图编号5所示),“Jane is visiting”也很有可能(上图编号6所示),也很可能是“Jane visits Africa”(上图编号7所示)。
然后继续,接着进行集束搜索的第四步,再加一个单词继续,最终这个过程的输出一次增加一个单词,集束搜索最终会找到“Jane visits africa in september”这个句子,终止在句尾符号(上图编号8所示),用这种符号的系统非常常见,它们会发现这是最有可能输出的一个英语句子。在本周的练习中,你会看到更多的执行细节,同时,你会运用到这个集束算法,在集束宽为3时,集束搜索一次只考虑3个可能结果。注意如果集束宽等于1,只考虑1种可能结果,这实际上就变成了贪婪搜索算法,上个视频里我们已经讨论过了。但是如果同时考虑多个,可能的结果比如3个,10个或者其他的个数,集束搜索通常会找到比贪婪搜索更好的输出结果。
你已经了解集束搜索是如何工作的了,事实上还有一些额外的提示和技巧的改进能够使集束算法更高效,我们在下个视频中一探究竟。
四.改进定向搜索
上个视频中, 你已经学到了基本的束搜索算法(the basic beam search algorithm),这个视频里,我们会学到一些技巧, 能够使算法运行的更好。长度归一化(Length normalization)就是对束搜索算法稍作调整的一种方式,帮助你得到更好的结果,下面介绍一下它。


这些符号看起来可能比实际上吓人,但这就是我们之前见到的乘积概率(the product probabilities)。如果计算这些,其实这些概率值都是小于1的,通常远小于1。很多小于1的数乘起来,会得到很小很小的数字,会造成数值下溢(numerical underflow)。数值下溢就是数值太小了,导致电脑的浮点表示不能精确地储存,因此在实践中,我们不会最大化这个乘积,而是取log值。如果在这加上一个log,最大化这个log求和的概率值,在选择最可能的句子时,你会得到同样的结果。所以通过取log,我们会得到一个数值上更稳定的算法,不容易出现四舍五入的误差,数值的舍入误差(rounding errors)或者说数值下溢(numerical underflow)。因为log函数它是严格单调递增的函数,最大化P(y),因为对数函数,这就是log函数,是严格单调递增的函数,所以最大化logP(y|x)和最大化P(y|x)结果一样。如果一个y值能够使前者最大,就肯定能使后者也取最大。所以实际工作中,我们总是记录概率的对数和(the sum of logs of the probabilities),而不是概率的乘积(the production of probabilities)。
对于目标函数(this objective function),还可以做一些改变,可以使得机器翻译表现的更好。如果参照原来的目标函数(this original objective),如果有一个很长的句子,那么这个句子的概率会很低,因为乘了很多项小于1的数字来估计句子的概率。所以如果乘起来很多小于1的数字,那么就会得到一个更小的概率值,所以这个目标函数有一个缺点,它可能不自然地倾向于简短的翻译结果,它更偏向短的输出,因为短句子的概率是由更少数量的小于1的数字乘积得到的,所以这个乘积不会那么小。顺便说一下,这里也有同样的问题,概率的log值通常小于等于1,实际上在log的这个范围内,所以加起来的项越多,得到的结果越负,所以对这个算法另一个改变也可以使它表现的更好,也就是我们不再最大化这个目标函数了,我们可以把它归一化,通过除以翻译结果的单词数量(normalize this by the number of words in your translation)。这样就是取每个单词的概率对数值的平均了,这样很明显地减少了对输出长的结果的惩罚(this significantly reduces the penalty for outputting longer translations.)。
在实践中,有个探索性的方法,相比于直接除T_y,也就是输出句子的单词总数,我们有时会用一个更柔和的方法(a softer approach),在T_y上加上指数a,a可以等于0.7。如果a等于1,就相当于完全用长度来归一化,如果a等于0,T_y的0次幂就是1,就相当于完全没有归一化,这就是在完全归一化和没有归一化之间。a就是算法另一个超参数(hyper parameter),需要调整大小来得到最好的结果。不得不承认,这样用a实际上是试探性的,它并没有理论验证。但是大家都发现效果很好,大家都发现实践中效果不错,所以很多人都会这么做。你可以尝试不同的a值,看看哪一个能够得到最好的结果。
总结一下如何运行束搜索算法。当你运行束搜索时,你会看到很多长度等于1的句子,很多长度等于2的句子,很多长度等于3的句子,等等。可能运行束搜索30步,考虑输出的句子可能达到,比如长度30。因为束宽为3,你会记录所有这些可能的句子长度,长度为1、2、 3、 4 等等一直到30的三个最可能的选择。然后针对这些所有的可能的输出句子,用这个式子(上图编号1所示)给它们打分,取概率最大的几个句子,然后对这些束搜索得到的句子,计算这个目标函数。最后从经过评估的这些句子中,挑选出在归一化的log概率目标函数上得分最高的一个(you pick the one that achieves the highest value on this normalized log probability objective.),有时这个也叫作归一化的对数似然目标函数(a normalized log likelihood objective)。这就是最终输出的翻译结果,这就是如何实现束搜索。这周的练习中你会自己实现这个算法。

最后还有一些实现的细节,如何选择束宽B。B越大,你考虑的选择越多,你找到的句子可能越好,但是B越大,你的算法的计算代价越大,因为你要把很多的可能选择保存起来。最后我们总结一下关于如何选择束宽B的一些想法。接下来是针对或大或小的B各自的优缺点。如果束宽很大,你会考虑很多的可能,你会得到一个更好的结果,因为你要考虑很多的选择,但是算法会运行的慢一些,内存占用也会增大,计算起来会慢一点。而如果你用小的束宽,结果会没那么好,因为你在算法运行中,保存的选择更少,但是你的算法运行的更快,内存占用也小。在前面视频里,我们例子中用了束宽为3,所以会保存3个可能选择,在实践中这个值有点偏小。在产品中,经常可以看到把束宽设到10,我认为束宽为100对于产品系统来说有点大了,这也取决于不同应用。但是对科研而言,人们想压榨出全部性能,这样有个最好的结果用来发论文,也经常看到大家用束宽为1000或者3000,这也是取决于特定的应用和特定的领域。在你实现你的应用时,尝试不同的束宽的值,当B很大的时候,性能提高会越来越少。对于很多应用来说,从束宽1,也就是贪心算法,到束宽为3、到10,你会看到一个很大的改善。但是当束宽从1000增加到3000时,效果就没那么明显了。对于之前上过计算机科学课程的同学来说,如果你熟悉计算机科学里的搜索算法(computer science search algorithms), 比如广度优先搜索(BFS, Breadth First Search algorithms),或者深度优先搜索(DFS, Depth First Search),你可以这样想束搜索,不像其他你在计算机科学算法课程中学到的算法一样。如果你没听说过这些算法也不要紧,但是如果你听说过广度优先搜索和深度优先搜索,不同于这些算法,这些都是精确的搜索算法(exact search algorithms),束搜索运行的更快,但是不能保证一定能找到argmax的准确的最大值。如果你没听说过广度优先搜索和深度优先搜索,也不用担心,这些对于我们的目标也不重要,如果你听说过,这就是束搜索和其他算法的关系。
好,这就是束搜索。这个算法广泛应用在多产品系统或者许多商业系统上,在深度学习系列课程中的第三门课中,我们讨论了很多关于误差分析(error analysis)的问题。事实上在束搜索上做误差分析是我发现的最有用的工具之一。有时你想知道是否应该增大束宽,我的束宽是否足够好,你可以计算一些简单的东西来指导你需要做什么,来改进你的搜索算法。我们在下个视频里进一步讨论。
五.定向搜索的误差分析
在这五门课中的第三门课里,你了解了误差分析是如何能够帮助你集中时间做你的项目中最有用的工作,束搜索算法是一种近似搜索算法(an approximate search algorithm),也被称作启发式搜索算法(a heuristic search algorithm),它不总是输出可能性最大的句子,它仅记录着B为前3或者10或是100种可能。那么如果束搜索算法出现错误会怎样呢?
本节视频中,你将会学习到误差分析和束搜索算法是如何相互起作用的,以及你怎样才能发现是束搜索算法出现了问题,需要花时间解决,还是你的RNN模型出了问题,要花时间解决。我们先来看看如何对束搜索算法进行误差分析。

我们来用这个例子说明: “Jane visite l'Afrique en septembre”。假如说,在你的机器翻译的dev集中,也就是开发集(development set),人工是这样翻译的: Jane visits Africa in September,我会将这个标记为y^*。这是一个十分不错的人工翻译结果,不过假如说,当你在已经完成学习的RNN模型,也就是已完成学习的翻译模型中运行束搜索算法时,它输出了这个翻译结果:Jane visited Africa last September,我们将它标记为yhat。这是一个十分糟糕的翻译,它实际上改变了句子的原意,因此这不是个好翻译。
你的模型有两个主要部分,一个是神经网络模型,或说是序列到序列模型(sequence to sequence model),我们将这个称作是RNN模型,它实际上是个编码器和解码器( an encoder and a decoder)。另一部分是束搜索算法,以某个集束宽度B运行。如果你能够找出造成这个错误,这个不太好的翻译的原因,是两个部分中的哪一个,不是很好吗? RNN (循环神经网络)是更可能是出错的原因呢,还是束搜索算法更可能是出错的原因呢?你在第三门课中了解到了大家很容易想到去收集更多的训练数据,这总归没什么坏处。所以同样的,大家也会觉得不行就增大束宽,也是不会错的,或者说是很大可能是没有危害的。但是就像单纯获取更多训练数据,可能并不能得到预期的表现结果。相同的,单纯增大束宽也可能得不到你想要的结果,不过你怎样才能知道是不是值得花时间去改进搜索算法呢? 下面我们来分解这个问题弄清楚什么情况下该用什么解决办法。




所以误差分析过程看起来就像下面这样。你先遍历开发集,然后在其中找出算法产生的错误,这个例子中,假如说P(y^*|x)的值为2 x 10-10,而P(yhat|x)的值为 1 x10-10,根据上页幻灯片中的逻辑关系,这种情况下我们得知束搜索算法实际上选择了比y^*可能性更低的yhat,因此我会说束搜索算法出错了。我将它缩写为B。接着你继续遍历第二个错误,再来看这些可能性。也许对于第二个例子来说,你认为是RNN模型出现了问题,我会用缩写R来代表RNN。再接着你遍历了更多的例子,有时是束搜索算法出现了问题,有时是模型出现了问题,等等。通过这个过程,你就能够执行误差分析,得出束搜索算法和RNN模型出错的比例是多少。有了这样的误差分析过程,你就可以对开发集中每一个错误例子,即算法输出了比人工翻译更差的结果的情况,尝试确定这些错误,是搜索算法出了问题,还是生成目标函数(束搜索算法使之最大化)的RNN模型出了问题。并且通过这个过程,你能够发现这两个部分中哪个是产生更多错误的原因,并且只有当你发现是束搜索算法造成了大部分错误时,才值得花费努力增大集束宽度。相反地,如果你发现是RNN模型出了更多错,那么你可以进行更深层次的分析,来决定是需要增加正则化还是获取更多的训练数据,抑或是尝试一个不同的网络结构,或是其他方案。你在第三门课中,了解到各种技巧都能够应用在这里。
这就是束搜索算法中的误差分析,我认为这个特定的误差分析过程是十分有用的,它可以用于分析近似最佳算法(如束搜索算法),这些算法被用来优化学习算法(例如序列到序列模型/RNN)输出的目标函数。也就是我们这些课中一直讨论的。学会了这个方法,我希望你能够在你的应用里更有效地运用好这些类型的模型。