《机器学习》西瓜书课后习题9.4——python实现K-means算法
《机器学习》西瓜书课后习题9.4——python实现K-means算法
9.4 试编程实现k均值算法,设置三组不同的k值、三组不同的初始中心点,在西瓜数据集4.0上进行实验比较,
并讨论什么样的初始中心有利于取得好结果.
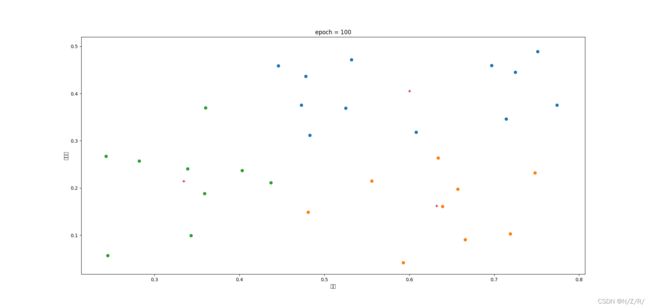
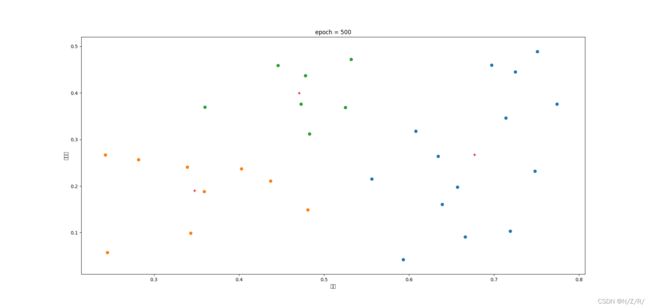
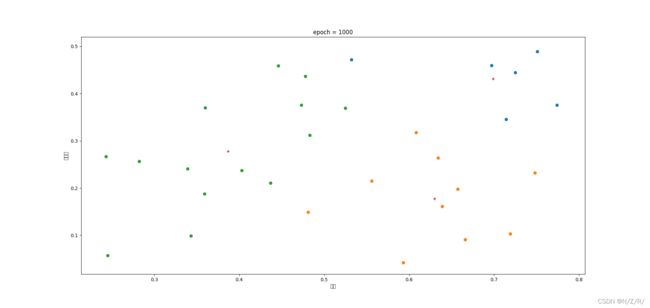
本文主要适用python语言编程实现了K-means算法的过程,并使用了西瓜数据集4.0作为测试数据,在初始化均值向量时使用随机选择的方法,因此相同参数的情况下代码每次运行的结果可能会有所不同。最后,为了验证聚类效果,可视化了最终的结果集,可以发现的是,随着迭代的此时的增多,聚类的效果更好,直至趋于稳定。
具体的算法伪代码和原理部分参见《机器学习》周志华 P203。
西瓜数据集4.0内容:
编号,密度,含糖率
1,0.697,0.460
2,0.774,0.376
3,0.634,0.264
4,0.608,0.318
5,0.556,0.215
6,0.403,0.237
7,0.481,0.149
8,0.437,0.211
9,0.666,0.091
10,0.243,0.267
11,0.245,0.057
12,0.343,0.099
13,0.639,0.161
14,0.657,0.198
15,0.360,0.370
16,0.593,0.042
17,0.719,0.103
18,0.359,0.188
19,0.339,0.241
20,0.282,0.257
21,0.748,0.232
22,0.714,0.346
23,0.483,0.312
24,0.478,0.437
25,0.525,0.369
26,0.751,0.489
27,0.532,0.472
28,0.473,0.376
29,0.725,0.445
30,0.446,0.459
下面我将对代码逐段解释……
一、数据预处理
先将数据集下载并加载进来!代码如下:
def loadData(filename):
data = open(filename, 'r', encoding='GBK')
reader = csv.reader(data)
headers = next(reader)
dataset = []
for row in reader:
row[1] = float(row[1])
row[2] = float(row[2])
dataset.append([row[1],row[2]])
return dataset
二、k-means算法
1、创建一个Kmeans类,所有的操作均封装
Kmeans类中以下的参数是必不可少的:
- k:聚类的个数
- train_data:数据集
- epoch:迭代次数
在该类中,首先是对均值向量进行初始化,随机选择k个数据作为均值向量。其次,我们需要计算数据和均值向量之间的距离,并按最近距离进行划分类。然后,我们需要更新均值向量,具体做法是取每个类中的均值作为新的均值向量。如此,直到达到要求的迭代次数。
class Kmeans:
k = 0
train_data = []
category_k = {}
vector_k = []
epoch = 0
def __init__(self,k,train_data,epoch):
self.train_data = np.array(train_data, dtype=float)
self.epoch = epoch
# 初始化均值向量
for i in range(0,k):
self.vector_k.append(self.train_data[random.randint(0,len(train_data)-1)])
self.vector_k = np.array(self.vector_k, dtype=float)
# 第i轮迭代
for epoch_i in range(0,epoch):
self.category_k = {}
# 计算距离并分类
for data_i in self.train_data:
category_i = self.dist(data_i)
if category_i not in self.category_k:
self.category_k[category_i] = [data_i]
else:
self.category_k[category_i].append(data_i)
# 更新均值向量
self.update_category()
2、计算距离并分类
# 计算第i个数据和所有均值向量的距离,并
def dist(self,data_i):
dist = (self.vector_k-data_i)**2
mean_dist = dist.mean(axis=1)
return mean_dist.argmin()
3、更新均值向量
# 计算每个类别的均值并更新均值向量
def update_category(self):
for i in range(0,len(self.vector_k)):
self.vector_k[i] = np.array(self.category_k[i]).mean(axis=0)
4、绘制图像
# 绘制散点图
def draw_scatter(self):
for i in self.category_k:
x = np.array(self.category_k[i])[:,0]
y = np.array(self.category_k[i])[:,1]
plt.scatter(x,y)
# 绘制均值向量点的位置
print(self.vector_k)
x_mean = self.vector_k[:,0]
y_mean = self.vector_k[:,1]
plt.title("epoch = "+str(self.epoch))
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.scatter(x_mean,y_mean,marker='+')
plt.show()
三、完整的程序源代码
'''
9.4 试编程实现k均值算法,设置三组不同的k值、三组不同的初始中心点,在西瓜数据集4.0上进行实验比较,
并讨论什么样的初始中心有利于取得好结果.
'''
import random
import numpy as np
import csv
import matplotlib.pyplot as plt
class Kmeans:
k = 0
train_data = []
category_k = {}
vector_k = []
epoch = 0
def __init__(self,k,train_data,epoch):
self.train_data = np.array(train_data, dtype=float)
self.epoch = epoch
# 初始化均值向量
for i in range(0,k):
self.vector_k.append(self.train_data[random.randint(0,len(train_data)-1)])
self.vector_k = np.array(self.vector_k, dtype=float)
# 第i轮迭代
for epoch_i in range(0,epoch):
self.category_k = {}
# 计算距离并分类
for data_i in self.train_data:
category_i = self.dist(data_i)
if category_i not in self.category_k:
self.category_k[category_i] = [data_i]
else:
self.category_k[category_i].append(data_i)
# 更新均值向量
self.update_category()
def get_category(self):
return self.category_k
# 计算第i个数据和所有均值向量的距离,并
def dist(self,data_i):
dist = (self.vector_k-data_i)**2
mean_dist = dist.mean(axis=1)
return mean_dist.argmin()
# print(mean_dist.argmin())
# 计算每个类别的均值并更新均值向量
def update_category(self):
for i in range(0,len(self.vector_k)):
self.vector_k[i] = np.array(self.category_k[i]).mean(axis=0)
# 绘制散点图
def draw_scatter(self):
for i in self.category_k:
x = np.array(self.category_k[i])[:,0]
y = np.array(self.category_k[i])[:,1]
plt.scatter(x,y)
# 绘制均值向量点的位置
print(self.vector_k)
x_mean = self.vector_k[:,0]
y_mean = self.vector_k[:,1]
plt.title("epoch = "+str(self.epoch))
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.scatter(x_mean,y_mean,marker='+')
plt.show()
def loadData(filename):
data = open(filename, 'r', encoding='GBK')
reader = csv.reader(data)
headers = next(reader)
dataset = []
for row in reader:
row[1] = float(row[1])
row[2] = float(row[2])
dataset.append([row[1],row[2]])
return dataset
filename = '西瓜数据集4.0.csv'
traindata = loadData(filename)
kmeans = Kmeans(3,traindata,100)
print(kmeans.get_category())
kmeans.draw_scatter()
四、结果分析
在这里我们令k=3,迭代次数依次为100,500,1000次,然后根据图像来观察聚类效果,如图所示:
图中相同颜色的点表示划分为同一个簇,红色的“+”号代表最终的均值向量,标题上标注了迭代的次数