进程、线程和协程(进阶篇)
目录
进程通信
进程通信机制的简单概括
管道
匿名管道
有名管道 FIFO
消息队列
内存映射(Memory Map)
共享内存
信号量和 PV 操作
信号量的工作原理
信号量的特点
信号量的函数原型
信号量配合共享内存使用
信号
套接字(Socket)
常用调度算法
先来先服务调度算法FCFS
短作业(进程)优先调度算法SJF(非抢占)/SPF(抢占)
优先权调度算法 HPF
高响应比优先调度算法 HRRN
时间片轮转法RR
多级反馈队列调度算法FB
线程安全
互斥锁(互斥量)
自旋锁
读写锁
条件变量
信号量
互斥锁、条件变量和信号量的区别
总结
进程、线程和协程是高并发和高可用的基础知识之一,我们在进程、线程和协程(基础篇)中详细的介绍了它们的概念和关系,尤其与它们相关的一些基础知识,但是我们知道了这些基础知识还远不远不够。在我们使用中,经常会遇到这些问题:线程安全问题、进程通信问题和在我们要频繁使用进程、线程和协程的时候,而引入的进程池,线程池和协程池问题等。那么我们就这些问题仔细的学习一下,废话不多说直接开始吧~~~~~~~~~~~
进程通信
什么是进程通信呢?进程通信( InterProcess Communication,IPC)就是指进程之间的信息交换。能达到进程与进程之间协调和协同工作的作用,和传递数据的能力。我们从进程、线程和协程(基础篇) 中知道,每一个进程都会自己独立的进程地址空间,一般是不能相互访问的。但是从操作系统层面来说,他们是共享内核空间的,所以进程之间想要进行信息交换就必须通过内核。
常见的进程通信机制:
- 管道(也称作共享文件)
- 消息队列(也称作消息传递)
- 共享内存(也称作共享存储)
- 信号量和 PV 操作
- 信号
- 套接字(Socket)
程通信机制示意图如下:
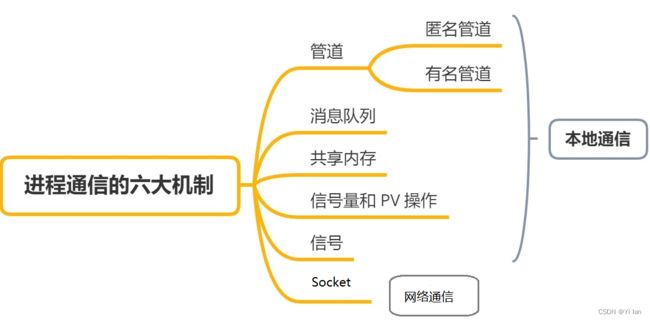
进程通信机制的简单概括
1. 最简单的方式就是管道,管道的本质是存放在内存中的特殊的文件。也就是说,内核在内存中开辟了一个缓冲区,这个缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区的操作。管道分为匿名管道和有名管道,匿名管道只能在父子进程之间进行通信,而有名管道没有限制
2. 虽然管道使用简单,但是效率比较低,不适合进程间频繁地交换数据,并且管道只能传输无格式的字节流。为此消息队列应用而生。消息队列的本质就是存放在内存中的消息的链表,而消息本质上是用户自定义的数据结构。如果进程从消息队列中读取了某个消息,这个消息就会被从消息队列中删除
3. 消息队列的速度比较慢,因为每次数据的写入和读取都需要经过用户态与内核态之间数据的拷贝过程,共享内存可以解决这个问题。所谓共享内存就是:两个不同进程的逻辑地址通过页表映射到物理空间的同一区域,它们所共同指向的这块区域就是共享内存。如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
对于共享内存机制来说,仅在建立共享内存区域时需要系统调用,一旦建立共享内存,所有的访问都可作为常规内存访问,无需借助内核。这样,数据就不需要在进程之间来回拷贝,所以这是最快的一种进程通信方式。
4. 共享内存速度虽然非常快,但是存在冲突问题,为此,我们可以使用信号量和 PV 操作来实现对共享内存的互斥访问,并且还可以实现进程同步。
5. 信号和信号量是完全不同的两个概念!信号是进程通信机制中唯一的异步通信机制,它可以在任何时候发送信号给某个进程。通过发送指定信号来通知进程某个异步事件的发送,以迫使进程执行信号处理程序。信号处理完毕后,被中断进程将恢复执行。用户、内核和进程都能生成和发送信号。
6. 上面介绍的 5 种方法都是用于同一台主机上的进程之间进行通信的,如果想要跨网络与不同主机上的进程进行通信,就需要使用 Socket 通信。Socket 也能完成同主机上的进程通信
管道
管道的本质就是内核在内存中开辟了一个缓冲区,这个缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区的操作。它使用简单,但是效率比较低,不适合进程间频繁地交换数据,并且管道只能传输无格式的字节流。
匿名管道
管道特点:
- 是一种半双工的通信方式
- 只能在具有亲缘关系(父子关系)的进程间使用
- 它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中
- 生命周期跟随进程
- 管道大小为64k
- 当读写的数据小于pipe size(4k)的时候,管道保证读写的原子性
有名管道 FIFO
匿名管道由于没有名字,只能用于父子进程间的通信。为了克服这个缺点,提出了有名管道,也称做 FIFO。它是一种文件类型,可以当做文件来操作。
FIFO的特点:
- FIFO可以在无关的进程之间交换数据,与无名管道不同
- FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中
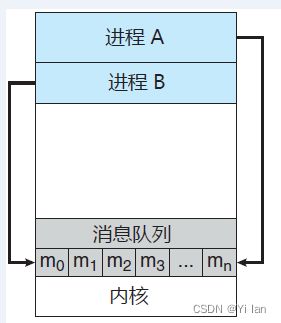
消息队列
消息队列的本质就是存放在内核之中的消息的链表,而消息本质上是用户自定义的数据结构。消息传递对于交换较少数量的数据很有用,因为无需避免冲突。但是如果我们需要交换数据量较大,使用消息队列就会造成频繁的系统调用(数据从用户态拷贝数据到内核态和从内核态拷贝数据到用户态的过程),也就是需要消耗更多的时间以便内核介入。
消息队列的特点:
- 消息队列可以有一个或者多个进程对它进行读写
- 消息队列可以实现消息的随机查询,不一定非要以先进先出的次序读取消息,也可以按消息的类型读取
- 消息队列的生命周期随内核,即如果没有主动释放消息或者关闭系统,消息队列会一直存在
消息队列示意图如下:
消息队列常用函数:
// 创建或打开消息队列:成功返回队列ID,失败返回-1
int msgget(key_t key, int flag);
// 添加消息:成功返回0,失败返回-1
int msgsnd(int msqid, const void *ptr, size_t size, int flag);
// 读取消息:成功返回消息数据的长度,失败返回-1
int msgrcv(int msqid, void *ptr, size_t size, long type,int flag);
// 控制消息队列:成功返回0,失败返回-1
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
例子代码如下:
//send.c
#include
#include
#define BUF_TEXT 256
#define BUF_SIZ 256
struct msg_buf
{
long msg_type; //标志位
char msg_text[BUF_TEXT]; //发送数据缓冲区
};
int main(void)
{
struct msg_buf data;
int msg = -1; //标识id
int running = 1;
char buffer[BUF_SIZ];
msg = msgget((key_t)123456, 0777|IPC_CREAT);
if(msg == -1)
{
fprintf(stderr, "msgget error %d!\n", errno);
return 1;
}
while(running)
{
fgets(buffer, BUF_SIZ, stdin);
data.msg_type = 1;
stpcpy(data.msg_text, buffer);
if(msgsnd(msg, (void *)&data, BUF_TEXT, 0) == -1)
{
fprintf(stderr, "msgsnd error %d \n", errno);
break;
}
if(strncmp(data.msg_text, "quit", 4) == 0)
{
running = 0;
}
sleep(2);
}
return 0;
}
//recv.c
#include
#include
//msgget
#include
#include
#include
//exit头文件
#include
#include
//errno头文件
#include
#include
#define BUF_SIZ 256
struct msg_buf
{
long msg_type; //标志位
char msg_text[BUF_SIZ];
};
int main(void)
{
struct msg_buf data;
int msg = -1; //标识id
int running = 1;
char buffer[BUF_SIZ];
long int msgtype = 0;
//打开消息队列
msg = msgget((key_t)123456, 0777|IPC_CREAT);
if(msg == -1)
{
fprintf(stderr, "msgget error %d!\n",errno);
return 1;
}
while(running)
{
if(msgrcv(msg, (void *)&data, BUF_SIZ, msgtype, 0) == -1)
{
fprintf(stderr, "msgrcv error %d \n",errno);
break;
}
printf("queue get data: %s \n",data.msg_text);
if(strncmp(data.msg_text, "quit", 4) == 0) //以quit结束
{
running = 0;
}
}
//断开消息队列的连接
if(msgctl(msg, IPC_RMID, 0) == -1) //msgctl删除消息队列
{
fprintf(stderr, "magctl error %d \n",errno);
break;
}
return 0;
} 内存映射(Memory Map)
内存映射文件,是由一个文件到一块内存的映射。内存映射文件与 虚拟内存有些类似,通过内存映射文件可以保留一个地址的区域,同时将物理存储器提交给此区域,内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作。 每一个使用该机制的进程通过把同一个共享的文件映射到自己的进程地址空间来实现多个进程间的通信(这里类似于共享内存,只要有一个进程对这块映射文件的内存进行操作,其他进程也能够马上看到)。
使用内存映射文件不仅可以实现多个进程间的通信,还可以用于 处理大文件提高效率。
函数原型:
void *mmap(void*start,size_t length,int prot,int flags,int fd,off_t offset);
//mmap函数将一个文件或者其它对象映射进内存。 第一个参数为映射区的开始地址,设置为0表示由系统决定映射区的起始地址,第二个参数为映射的长度,第三个参数为期望的内存保护标志,第四个参数是指定映射对象的类型,第五个参数为文件描述符(指明要映射的文件),第六个参数是被映射对象内容的起点。成功返回被映射区的指针,失败返回MAP_FAILED[其值为(void *)-1]。
int munmap(void* start,size_t length);//munmap函数用来取消参数start所指的映射内存起始地址,参数length则是欲取消的内存大小。如果解除映射成功则返回0,否则返回-1,错误原因存于errno中错误代码EINVAL。
int msync(void *addr,size_t len,int flags); //msync函数实现磁盘文件内容和共享内存取内容一致,即同步。第一个参数为文件映射到进程空间的地址,第二个参数为映射空间的大小,第三个参数为刷新的参数设置。
共享内存
两个不同进程的逻辑地址通过页表映射到物理空间的同一区域,它们所共同指向的这块区域就是共享内存。它不像消息队列那样需要频繁的调用系统,只在创建的使用调用。一旦创建成功,之后的所有操作就是常规的内存访问,不再经过内核(也就没有内核和用户态的拷贝)。可以使用ipcs -m 查看系统下已有的共享内存;ipcrm -m shmid可以用来删除共享内存。
如图所示:
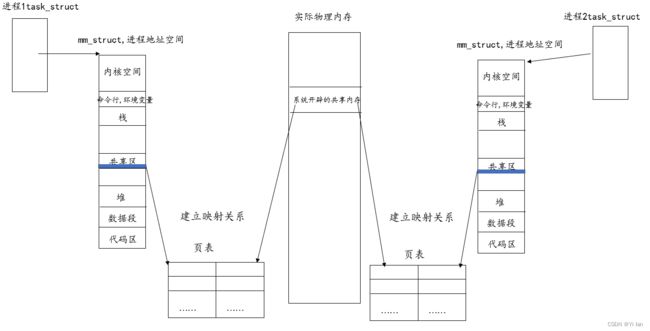
共享内存的特点:
- 共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
- 因为多个进程可以同时操作,所以需要进行同步。
- 信号量 + 共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
- IPC(进程将通信)资源生命周期不随进程,而是随内核的,不释放会一直占用,除非重启系统
共享内存的数据结构:
/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */ //所有者和权限
int shm_segsz; /* size of segment (bytes) *///共享内存空间大小
__kernel_time_t shm_atime; /* last attach time *///挂接时间
__kernel_time_t shm_dtime; /* last detach time *///取消挂接时间
__kernel_time_t shm_ctime; /* last change time *///改变时间
__kernel_ipc_pid_t shm_cpid; /* pid of creator */ //建立者的PID
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */ //最后调用函数 shmat ()/shmdt ()
unsigned short shm_nattch; /* no. of current attaches *///进程挂接数
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct ipc_perm
{
__kernel_key_t key;//共享内存的唯一标识符
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode; //权限
unsigned short seq;
};
共享内存函数:
// 创建或获取一个共享内存:成功返回共享内存ID,失败返回-1
int shmget(key_t key, size_t size, int flag);
// 连接共享内存到当前进程的地址空间:成功返回指向共享内存的指针,失败返回-1
void *shmat(int shm_id, const void *addr, int flag);
// 断开与共享内存的连接:成功返回0,失败返回-1
int shmdt(void *addr);
// 控制共享内存的相关信息:成功返回0,失败返回-1
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
例子代码如下:
//write.c
#include
#include
#include
#include
#include
#define PATHNAME "./"
#define PROJ_ID 0x666
#define SIZE 4096
int main(){
key_t k = ftok(PATHNAME,PROJ_ID);
if(k==-1){
perror("ftok error");
return 1;
}
int shmid = shmget(k, SIZE, IPC_CREAT | IPC_EXCL | 0666);
if(shmid == -1){
perror("shmget error");
return 1;
}
//与进程地址空间产生关联
char *str = (char *)shmat(shmid, NULL, 0);
char c='a';
for(;c<='z';c++){
str[c-'a']=c;
sleep(5);
}
//删除关联
shmdt(str);
//不用释放共享内存,服务器端释放
return 0;
}
//read.c
#include
#include
#include
#include
#include
#define PATHNAME "./"
#define PROJ_ID 0x666
#define SIZE 4096
int main(){
key_t k = ftok(PATHNAME,PROJ_ID);
if(k==-1){
perror("ftok error");
return 1;
}
int shmid = shmget(k,SIZE, 0);
if(shmid == -1){
perror("shmget error");
return 1;
}
//与进程地址空间产生关联
char *str = (char *)shmat(shmid, NULL, 0);
//读数据
while(1){
printf("%s\n",str);
if(strlen(str) == 26)
{
break;
}
sleep(1);
}
//删除关联
shmdt(str);
int sh = shmctl(shmid,IPC_RMID,NULL);
if(sh == -1){
perror("shmctl");
return 1;
}
return 0;
}
信号量和 PV 操作
信号量与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
信号量的工作原理
信号量只能进行两种操作等待和发送信号,即PV操作:
P:如果value的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行
V:如果有其他进程因等待value而被挂起,就让它恢复运行,如果没有进程因等待value而挂起,就给它加1.
代码如下:
typedef struct semaphore{
int value; //信号量值
struct pcb *list; //信号量队列指针
}
//P操作
void P ( semaphore s )
{
s.value --;
if ( s.value < 0 )
{
asleep(s.list);
}
}
//V操作
void V ( semaphore s )
{
s.value ++;
if ( s.value <= 0 )
{
wakeup(s.list);
}
}信号量的特点
- 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
- 信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
- 每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
- 支持信号量组
信号量的函数原型
// 创建或获取一个信号量组, nsems:创建的信号量的个数; 若成功返回信号量集ID,失败返回-1
int semget(key_t key, int num_sems, int sem_flags);
// 对信号量组进行操作,改变信号量的值:成功返回0,失败返回-1
int semop(int semid, struct sembuf semoparray[], size_t numops);
// 控制信号量的相关信息
int semctl(int semid, int sem_num, int cmd, ...);
在函数原型中我们知道,有两个数据结构体,如下:
struct sembuf
{
short sem_num; //信号量组中的编号(即指定对哪个信号量操作) semget实际是获取一 组信号量 如果只获取了一个信号量,则该成员取0
short sem_op; // -1, 表示P操作 1, 表示V操作
short sem_flg; // SEM_UNDO : 如果进程在终止时,没有释放信号量 如果不设置指定 标志,应该设置为0 则,自动释放该信号量
}union semun
{
int val;
struct semid_ds *buf;
unsigned short *array;
struct seminfo *_buf;
}
信号量配合共享内存使用
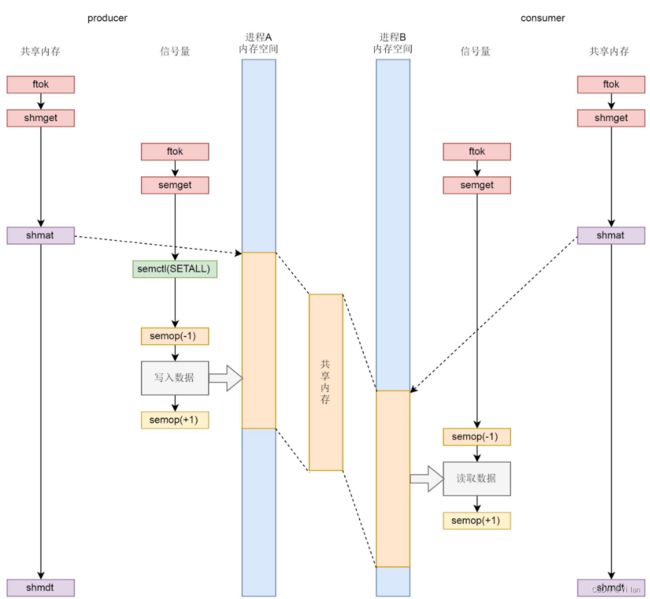
例子如下:
//semp1.c
#include
#include
#include
#include
#include
#include
union semun {
int val;
struct semid_ds *buf;
unsigned short *array;
struct seminfo *__buf;
};
void P(int semid,unsigned short num)
{
struct sembuf set;
set.sem_num = num; //信号量在数组里的序号
set.sem_op = -1; //信号量的操作值
set.sem_flg = SEM_UNDO; //信号量的操作标识
semop(semid, &set,1);
printf("get key\n");
}
void V(int semid,unsigned short num)
{
struct sembuf set;
set.sem_num = num;
set.sem_op = 1;
set.sem_flg = SEM_UNDO;
semop(semid, &set,1);
printf("put key\n");
}
int main()
{
key_t key1,key2;
key1 = ftok(".",1); //获取键值
key2 = ftok(".",2);
int shmid = shmget(key1,1024*4,IPC_CREAT|0666); //打开或者创建共享内存
int semid = semget(key2,2,IPC_CREAT|0666);//打开或者创建信号量组
union semun seminit; //信号量初始化
seminit.val = 1; //第一个信号量设置为1
semctl(semid,0,SETVAL,seminit);
seminit.val = 0;//第二个信号量设置为0
semctl(semid,1,SETVAL,seminit);
P(semid,0); //给第一个信号量上锁
char *shmaddr = shmat(shmid,0,0); //共享内存连接到当前进程的地址空间
printf("shmat ok\n");
strcpy(shmaddr,"hello world"); //向内存中写入数据
shmdt(shmaddr); //断开进程和内存的连接
V(semid,1); //释放第二个信号量
P(semid,0); //等待第一个信号量的释放
shmctl(shmid,IPC_RMID,0); //删除共享内存段
semctl(semid,0,IPC_RMID); //删除信号量组
printf("quit\n");
return 0;
}
//semp2.c
#include
#include
#include
#include
#include
#include
union semun {
int val;
struct semid_ds *buf;
unsigned short *array;
struct seminfo *__buf;
};
void P(int semid,unsigned short num)
{
struct sembuf set;
set.sem_num = num; //信号量在数组里的序号
set.sem_op = -1; //信号量的操作值
set.sem_flg = SEM_UNDO; //信号量的操作标识
semop(semid, &set,1);
printf("get key\n");
}
void V(int semid,unsigned short num)
{
struct sembuf set;
set.sem_num = num;
set.sem_op = 1;
set.sem_flg = SEM_UNDO;
semop(semid, &set,1);
printf("put key\n");
}
int main()
{
key_t key1,key2;
key1 = ftok(".",1); //获取键值
key2 = ftok(".",2);
int shmid = shmget(key1,1024*4,IPC_CREAT|0666); //打开或者创建共享内存
int semid = semget(key2,1,IPC_CREAT|0666);//打开或者创建信号量组
P(semid,1); //等待第二个信号量释放
char *shmaddr = shmat(shmid,0,0); //共享内存连接到当前进程的地址空间
printf("shmat ok\n"); //表示连接成功
printf("data : %s\n",shmaddr); //将内存地址中的数据读出,打印
shmdt(shmaddr); //断开内存和当前进程的连接
V(semid,0); //释放第一个信号量
printf("quit\n");
return 0;
}
信号
信号是进程通信机制中唯一的异步通信机制,它可以在任何时候发送信号给某个进程。通过发送指定信号来通知进程某个异步事件的发送,以迫使进程执行信号处理程序。信号处理完毕后,被中断进程将恢复执行. 注意!信号和信号量是完全不同的两个概念!
信号的函数原型:
//接收函数,第二个参数指向信号处理函数
sighandler_t signal(int signum, sighandler_t handler);
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
//发送函数
int kill(pid_t pid, int sig);int sigqueue(pid_t pid, int signo, const union sigval value);
struct sigaction数据结构如下:
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
}
常见的信号有:
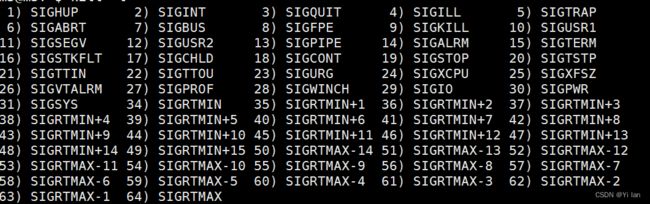
套接字(Socket)
Socket 套接字是网络通信的基石,是支持 TCP/IP 协议的网络通信的基本操作单元。详细的介绍查看网络编程。
常用调度算法
1. 先来先服务调度算法FCFS
2. 短作业(进程)优先调度算法SJF(非抢占)/SPF(抢占)
3. 优先权调度算法 HPF
4. 高响应比优先调度算法 HRRN
5. 时间片轮转法RR
6. 多级反馈队列调度算法FB
先来先服务调度算法FCFS
1. 根据提交作业,或者进程转换为就绪状态的先后顺序分派CPU
2. 新的作业要等当前的作业或者进程执行完或者堵塞让出CPU才能获得CPU
3.有利于CPU繁忙型的作业,而不利于I/O繁忙的作业
4.该算法实现基本公平原则,但是对短作业(进程)很不利
短作业(进程)优先调度算法SJF(非抢占)/SPF(抢占)
1. 对短作业或短进程优先调度的算法
2.未考虑作业的紧迫程度,因而不能保证紧迫性作业(进程)的及时处理、对长作业的不利、作业(进程)的长短含主观因素,不一定能真正做到短作业优先
3. 平均周转时间,带权平均周转时间都改善
优先权调度算法 HPF
1. 两种方式:非抢占式优先权算法、抢占式优先权算法
2.类型:静态优先权:创建进程时确定,整个运行期间保持不变。动态优先权:创建进程时赋予的优先权可随进程的推进或随其等待时间的增加而改变
3.
非抢占式优先权算法: 就是此时优先权最高的进程获取cpu,就会一直执行下去,直到完成或者发生某事件使该进程放弃处理机时,才会交出执行权(CPU)。主要应用于批处理系统中;也可用于某些对实时性要求不严的实时系统中
抢占式优先权算法: 就是此时优先权最高的进程获取cpu,使之执行。但是一旦出现优先权更高的作业(进程)时,会直接停止该作业(进程)的执行,而重新分配CPU按照优先权。主要应用要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中
高响应比优先调度算法 HRRN
1. 该算法综合考虑作业/进程的等待时间和要求服务时间
2. 计算公式 :响应比=(等待时间+要求服务时间)/要求服务时间, 即 RR=(w+s)/s=1+w/s
3. 在作业完成时、新作业产生时(抢占、非抢占)、时间片完成时、进程阻塞时进行计算各进程的响应比
时间片轮转法RR
1.把CPU划分成若干时间片,并且按顺序赋给就绪队列中的每一个进程,进程轮流占有CPU,当时间片用完时,即使进程未执行完毕,系统也剥夺该进程的CPU,将该进程排在就绪队列末尾。同时系统选择另一个进程运行
2.进程阻塞情况发生时,未用完时间片也要出让CPU
多级反馈队列调度算法FB
1. 设置多个就绪队列,各队列有不同的优先级,优先级从第一个队列依次降低
2. 赋予各队列进程执行时间片大小不同, 优先权越高,时间片越短
3. 仅当优先权高的队列(如第一队列)空闲时,调度程序才调度第二队列中的进程运行
4. 高优先级抢占时,被抢占的进程放回原就绪队列末尾
5. 通一个队列中,按照FCFS原则排队等待调度
线程安全
从进程、线程和协程的关系 中我们可以知道一个进程可以有许多线程同时在执行,而这些线程可能同时访问相同的代码或者访问修改相同的数据,这时候我们得到的结果完全不确定。我们希望的结果是确定的,这就依靠线程同步来实现,即线程安全。
线程同步的方法:
1.互斥锁(互斥量)
2.条件变量
3. 读写锁
4.自旋锁
5.信号量
互斥锁(互斥量)
互斥锁本质就是一个特殊的全局变量,拥有lock和unlock两种状态,unlock的互斥锁可以由某个线程获得,当互斥锁由某个线程持有后,这个互斥锁会锁上变成lock状态,此后只有该线程有权力打开该锁,其他想要获得该互斥锁的线程都会阻塞,直到互斥锁被解锁
互斥锁的类型:
普通锁(PTHREAD_MUTEX_NORMAL):互斥锁默认类型。当一个线程对一个普通锁加锁以后,其余请求该锁的线程将形成一个 等待队列,并在该锁解锁后按照优先级获得它,这种锁类型保证了资源分配的公平性。一个 线程如果对一个已经加锁的普通锁再次加锁,将引发死锁;对一个已经被其他线程加锁的普 通锁解锁,或者对一个已经解锁的普通锁再次解锁,将导致不可预期的后果。
检错锁(PTHREAD_MUTEX_ERRORCHECK):一个线程如果对一个已经加锁的检错锁再次加锁,则加锁操作返回EDEADLK;对一个已 经被其他线程加锁的检错锁解锁或者对一个已经解锁的检错锁再次解锁,则解锁操作返回 EPERM。
嵌套锁(PTHREAD_MUTEX_RECURSIVE):该锁允许一个线程在释放锁之前多次对它加锁而不发生死锁;其他线程要想获得这个锁,则必须要等当前锁的拥有者必须执行多次解锁操作;对一个已经被其他线程加锁的嵌套锁解锁,或者对一个已经解锁的嵌套锁再次解锁,则解锁操作返回EPERM。
默认锁(PTHREAD_MUTEX_ DEFAULT):一个线程如果对一个已经加锁的默认锁再次加锁,或者虽一个已经被其他线程加锁的默 认锁解锁,或者对一个解锁的默认锁解锁,将导致不可预期的后果;这种锁实现的时候可能 被映射成上述三种锁之一。
函数的原型:
// 静态方式创建互斥锁
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;// 动态方式创建互斥锁,其中参数mutexattr用于指定互斥锁的类型,具体类型见上面四种,如果为NULL,就是普通锁。
int pthread_mutex_init (pthread_mutex_t* mutex,const pthread_mutexattr_t* mutexattr);int pthread_mutex_lock(pthread_mutex_t *mutex); // 加锁,阻塞
int pthread_mutex_trylock(pthread_mutex_t *mutex); // 尝试加锁,非阻塞
int pthread_mutex_unlock(pthread_mutex_t *mutex); // 解锁int pthread_mutex_destroy(pthread_mutex_t *mutex);//销毁互斥
应用例子:
#include
#include
#define NUM (2)
int g_num=10;
void *worker(void *arg) {
pthread_mutex_t* pMutex = (pthread_mutex_t*)arg;
while(g_num>0) {
pthread_mutex_lock(&pMutex);
if(g_num>0) {
g_num--;
}
printf("thread1 g_num=%d\n", g_num);
pthread_mutex_unlock(&pMutex);
}
}
int main() {
pthread_mutex_t mutex;
pthread_t tid[NUM];
pthread_mutex_init (mutex, nullptr);
for(int i = 0 ; i < NUM; i++)
{
pthread_create(&tid[i], NULL, &worker, (void*)&mutex);
}
for(int i = 0 ; i < NUM; i++)
{
pthread_join(tid[i], NULL);
}
pthread_mutex_destroy(&mutex);
return 0;
}
自旋锁
上锁受阻时线程不阻塞而是在循环中轮询查看能否获得该锁,没有线程的切换因而没有切换开销,不过对CPU的霸占会导致CPU资源的浪费。 所以自旋锁适用于并行结构(多个处理器)或者适用于锁被持有时间短而不希望在线程切换产生开销的情况。所以需要注意,不要在持有自旋锁情况下可能会进入休眠状态的函数,如果调用了这些函数,会浪费CPU资源,其他线程需要获取自旋锁需要等待的时间更长了
函数的原型:
int pthread_spin_destroy(pthread_spinlock_t *); //销毁自旋锁
int pthread_spin_init(pthread_spinlock_t *, int pshared); //初始化自旋锁
int pthread_spin_lock(pthread_spinlock_t *); //自旋锁上锁(阻塞)
int pthread_spin_trylock(pthread_spinlock_t *); //自旋锁上锁(非阻塞)
int pthread_spin_unlock(pthread_spinlock_t *); //自旋锁解锁
pthread_spin_init函数的pshared参数说明,pshared表示进程共享属性。如果值为PTHREAD_PROCESS_SHARED,那么表示自旋锁可以被能访问到底层内存的线程所获取,即使这些线程处于不同的进程;如果为PTHREAD_PROCESS_PROVATE,旋锁就只能被初始化该锁的进程内部的线程访问到
应用例子:
#include
#include
#include
#include
#include
#include
#include
#include
#include
pthread_spinlock_t g_spinlock;
int g_data;
void *thread_work1(void *argv)
{
while(1)
{
pthread_spin_lock(&g_spinlock); //上锁
printf("g_data=%d\n",g_data);
g_data++;
pthread_spin_unlock(&g_spinlock); //解锁
sleep(1);
}
}
void *thread_work2(void *argv)
{
while(1)
{
pthread_spin_lock(&g_spinlock); //上锁
g_data++;
pthread_spin_unlock(&g_spinlock); //解锁
sleep(1);
}
}
int main(int argc,char **argv)
{
pthread_t thread_id[2];
//初始化自旋锁
pthread_spin_init(&g_spinlock,PTHREAD_PROCESS_PRIVATE);
if(pthread_create(&thread_id[0],NULL,thread_work1,NULL)!=0)
{
return -1;
}
if(pthread_create(&&thread_id[1],NULL,thread_work2,NULL)!=0)
{
return -1;
}
for( int i = 0; i < 2; i++)
{
pthread_join(thread_id[i],NULL);
}
pthread_spin_destroy(&g_spinlock);
return 0;
}
读写锁
当以写模式加锁而处于写状态时任何试图加锁的线程(不论是读或写)都阻塞,当以读状态模式加锁而处于读状态时“读”线程不阻塞,“写”线程阻塞。读模式共享,写模式互斥
那么有了读写锁为什么还要互斥锁呢?因为虽然读写锁提高了并行性,但是就速度而言并不比互斥量快。所以我们一般在一些写操作比较多或是本身需要同步的地方并不多的程序中我们应该使用互斥量,而在读操作远大于写操作的一些程序中我们应该使用读写锁来进行同步
函数的原型:
int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *rwlockattr);//初始化读写锁
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);//销毁读写锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);//读模式锁定读写锁 阻塞
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);//写模式锁定读写锁 阻塞
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);//解锁读写锁int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); //读模式锁定读写锁 非阻塞
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);/写模式锁定读写锁 非阻塞
应用例子:
#include
#include
#include
#include
#define READ 0
#define WRITE 1
int g_data = 0;
pthread_rwlock_t g_rwlock;
void *thread_work(void *argv)
{
int type= (int)argv;
while (1)
{
if (READ == type)
{
pthread_rwlock_rdlock(&g_rwlock);
printf("%d:%d\n", pthread_self(), g_data);
sleep(1);
pthread_rwlock_unlock(&g_rwlock);
}
else
{
pthread_rwlock_wrlock(&g_rwlock);
g_data++;
printf("add g_data=%d\n",g_data);
pthread_rwlock_unlock(&g_rwlock);
sleep(1);
}
}
return NULL;
}
int main(int argc, char **argv)
{
pthread_t thread_id[3];
pthread_rwlock_init(&g_rwlock, NULL);
for( int i = 0; i < 3 ; i++)
{
if( i== 2 )
{
pthread_create(&thread_id[i], NULL, thread_work, (void *)WRITE);
}
else
{
pthread_create(&thread_id[i], NULL, thread_work, (void *)READ);
}
}
for( int i = 0; i < 3 ; i++)
{
pthread_join(thread_id[i], NULL);
}
pthread_rwlock_destroy(&g_rwlock);
return 0;
} 条件变量
条件变量是线程可用的另一种同步机制。互斥量用于上锁,条件变量则用于等待,并且条件变量总是需要与互斥量一起使用,运行线程以无竞争的方式等待特定的条件发生。条件变量本身是由互斥量保护的,线程在改变条件变量之前必须首先锁住互斥量。其他线程在获得互斥量之前不会察觉到这种变化,因为互斥量必须在锁定之后才能计算条件
函数的原型:
//初始化条件变量
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
//销毁条件变量
int pthread_cond_destroy(pthread_cond_t *cond);//无条件等待条件变量变为真
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);//在给定时间内,等待条件变量变为真
int pthread_cond_timewait(pthread_cond_t *cond, pthread_mutex_t *mutex, const struct timespec *tsptr);int pthread_cond_signal(pthread_cond_t *cond); //通知线程条件已经满足
int pthread_cond_broadcast(pthread_cond_t *cond); //通知线程条件已经满足
函数说明:
pthread_cond_signal——通知线程条件已经满足,一次只能通知一个线程
pthread_cond_broadcast——通知线程条件已经满足,一次通知所有睡眠的线程pthread_cond_wait ——函数一进入wait状态就会自动release mutex,把该线程唤醒,使pthread_cond_wait()通过(返回)时,该线程又自动获得该mutex
应用例子
#include
#include
#include
#include
//链表的结点
struct msg
{
int num;
struct msg *next;
};
struct msg *head = NULL;
struct msg *temp = NULL;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t has_producer = PTHREAD_COND_INITIALIZER;
void *producer(void *arg)
{
while (1)
{
pthread_mutex_lock(&mutex); //加锁
temp = malloc(sizeof(struct msg));
temp->num = rand() % 100 + 1;
temp->next = head;
head = temp; //头插法
printf("---producered---%d\n", temp->num);
pthread_mutex_unlock(&mutex); //解锁
pthread_cond_signal(&has_producer); //唤醒消费者线程
usleep(2);
}
return NULL;
}
void *consumer(void *arg)
{
while (1)
{
pthread_mutex_lock(&mutex); //加锁
while (head == NULL)
{
pthread_cond_wait(&has_producer, &mutex);
}
temp = head;
head = temp->next;
printf("------------------consumer--%d\n", temp->num);
free(temp); //删除节点,头删法
temp = NULL; //防止野指针
pthread_mutex_unlock(&mutex); //解锁
usleep(1);
}
return NULL;
}
int main(void)
{
pthread_t thread_t[2];
//创建生产者和消费者线程
pthread_create(&thread_t[1], NULL, producer, NULL);
pthread_create(&thread_t[2], NULL, consumer, NULL);
for(int i = 0 ; i < 2; i++)
{
pthread_join(thread_t[i], NULL);
}
return 0;
}
信号量
线程的信号量和进程的信号量类似,使用线程的信号量可以高效地完成基于线程的资源计数。每对公共资源控制一次,信号量就会减1;对公共资源释放一次,信号量就会加1;只有当信号量的值大于0的时候,才能访问信号量所代表的公共资源。它包括无名线程信号量和命名线程信号量。
函数原型
int sem_init (sem_t *sem, int pshared, unsigned int value); //初始化无名信号量
sem_t *sem_open (const char *name, int oflag, ...); //创建并初始化有名信号量
int sem_close (sem_t *sem); //关闭有名信号量
int sem_unlink (const char *name); //从系统中删除有名信号量
int sem_getvalue (sem_t *sem, int *sval); // 获取信号量的当前值
int sem_wait(sem_t *sem); //信号量减少1 非阻塞
int sem_timedwait (sem_t *sem, const struct timespec *abstime); //信号量减少1,有超时
int sem_trywait (sem_t *sem); //信号量非阻塞等待,信号量减少1
int sem_post(sem_t *sem); //信号量增加1
int sem_destroy (sem_t *sem); //销毁信号量
互斥锁、条件变量和信号量的区别

总结
这篇文章主要学习一下进程、线程和协程的通信机制和线程安全问题,希望能帮助到您,感谢阅读!觉得能帮助到您,可以点个赞,关注一下哈~谢谢~
