物体检测综述(RCNN系列和YOLO系列)、发展历程、学习资源汇总

1 二阶段检测的代表文章
最经典的就是Faster-RCNN,之前的没有必要了。所谓的两阶段检测的思路,可以概述为下:
第一阶段是为了区分前景和背景,仅做二分类,同时回归得到前景所在的区域范围,称作RoI(Region of Interest),通常用矩形框表示,俗称bbox (bounding box);
第二阶段利用RoI在CNN提取的特征图上抠取对应范围的特征,再次进行分类和回归预测。不同于第一阶段,此处的分类是多分类,需要区分出不同物体类别(而非仅仅是前景和背景)。而回归则是预测出物体所在的位置,通常也是用bbox表示。
可以将第二阶段理解为对第一阶段的精调:第一阶段仅仅做个“粗略”的预测,为的是尽量保持召回率(即尽量不要漏掉任何前景);第二阶段在第一阶段预测的基础上结合CNN提取的特征做进一步调整和预测,使得最终预测的结果更为精确。
非常清楚的网络模型结构图:
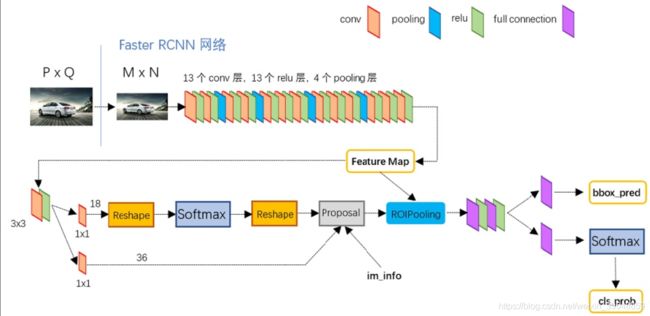
代表性博客:
懒人元 faster rcnn
知乎 一文读懂Faster RCNN
Faster RCNN参数详细解释
2 一阶段检测的代表文章
一阶段检测,最核心的思路就是舍弃RPN这样的提取框的过程,直接对设定的若干个框进行回归和分类。
关于YOLO系列的学习,要牢记下面这张图:
对算法的改进分析也要从这三方面进行思考。
2.1 YOLO- V1
Yolo三部曲解读——Yolov1
YOLO- V1的生动解释
yolov1的创新在于,把图片划为预设的若干区域,网络直接对这些区域进行分类和框回归。所以网络主体和分类的网络十分接近。
- 模型设计

直接关注最后的输出 7 * 7 * 30,其中7 * 7就是对原图划分为7 * 7个区域:
每一个小方格,负责一个检测,哪个物体的中心落在小方格里,这个小方格就负责他的检测。所以yolov1最多检测7*7=49个物体。
30是由(4+1)*2+20得到的。其中4+1是矩形框的中心点坐标 x,y,长宽 w,h以及是否属于被检测物体的置信度c;2是一个格子共回归两个矩形框,分别对应大物体检测和小物体检测;每个矩形框分别产生5个预测值([x,y,w,h,c]);20代表预测20个类别。这里有几点需要注意:1. 每个方格(grid) 产生2个预测框,2也是参数,可以调,但是一旦设定为2以后,那么每个方格只产生两个矩形框,最后选定置信度更大的矩形框作为输出,也就是最终每个方格只输出一个预测矩形框。
- 两个的错误分析
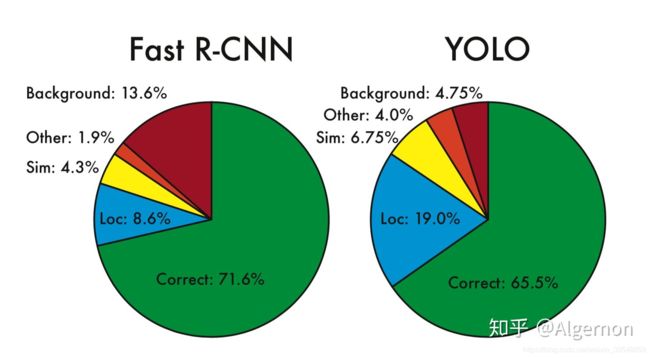
Yolo的Localization错误率更高,直接对位置进行回归,确实不如滑窗式的检测方式准确率高。但是Yolo对于背景的误检率更低,由于Yolo在推理时,可以“看到”整张图片,所以能够更好的区分背景与待测物体。
2.2 YOLO- V2
YOLO- V1有两个特别明显的问题:
- 预测的框不准确:准确度不足。
- 很多目标找不到:recall不足。
YOLO-V2主要是针对这两个问题做改进:
-
准确率的改进:
借鉴RCNN系列,不直接预测框的大小,改为预测基于grid的偏移值。
除此之外,直接预测位置会导致神经网络在一开始训练时不稳定,使用偏移量会使得训练过程更加稳定,性能指标提升了5%左右。
差不多同时期的Resnet更是利用这种残差思想,开启了一个时代。 -
召回率的提高
YOLO v2首先把 7 * 7个区域改为 13 * 13 个区域,每个区域有5个anchor,且每个anchor对应着1个类别,那么,输出的尺寸就应该为:[N,13,13,125]。
![]()
这里面有两个问题需要解释:
1.为什么要用Anchor呢?
答:一开始YOLO v1的初始训练过程很不稳定,在YOLO v2中,作者观察了很多图片的所有Ground Truth,发现:比如车,GT都是矮胖的长方形,再比如行人,GT都是瘦高的长方形,且宽高比具有相似性。那能不能根据这一点,从数据集中预先准备几个几率比较大的bounding box,再以它们为基准进行预测呢?这就是Anchor的初衷。
2.每个区域的5个anchor是如何得到的?
anchor是从数据集中统计得到的(Faster-RCNN中的Anchor的宽高和大小是手动挑选的)。
2.3 YOLO- V3
yolo系列之yolo v3【深度解析】
对于YOLO来说,还有一个大问题没有解决:
- 小物体检测
YOLO- V3主要就是解决这个问题。
为什么对小物体检测不够好?因为实现划分好的格子是固定大小的,对于小物体,格子可能画大了,对于大物体,格子可能又小了。
于是答案呼之欲出,我们需要有大小不一的格子,而不是固定一种格子。
于是YOLO- V3给出的解决方案如下:
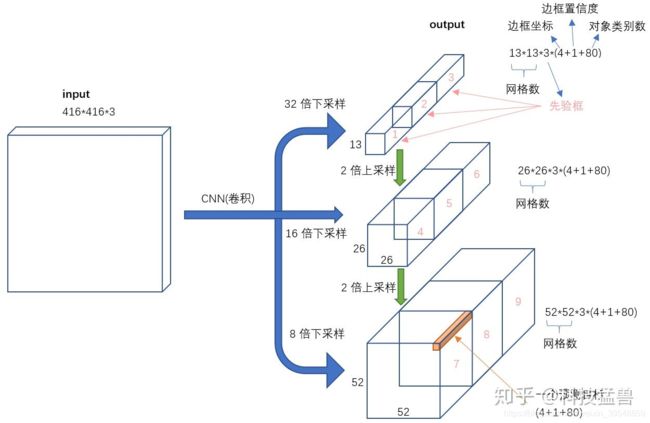
我们发现3个分支分别为32倍下采样,16倍下采样,8倍下采样,分别取预测大,中,小目标。为什么这样子安排呢?
因为32倍下采样每个点感受野更大,所以去预测大目标,8倍下采样每个点感受野最小,所以去预测小目标。专人专事。
发现预测地更准确了,性能又提升了。
每个分支预测3个框,每个框预测5元组+80个one-hot vector类别,所以一共size是:
3*(4+1+80)
每个分支的输出size为:
[13,13,3*(4+1+80)]
[26,26,3*(4+1+80)]
[52,52,3*(4+1+80)]
读到这里,请你数一下YOLO v3可以预测多少个bounding box?
![]()
YOLO- V3的一个特别优秀的图,也就是上面那个引用链接的图:
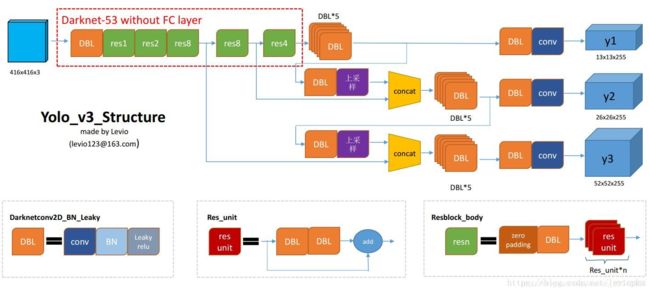
2.4 YOLO- V4
v3是一个集大成者,v4并没有做出突破性改进,只是在一些细节上进行了完善。分别是以下三个细节:
- 1.Using multi-anchors for single ground truth
之前的YOLO v3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。方法是:对于 G T j GT_j GTj 来说,只要 I o U ( a n c h o r i , G T j ) > t h r e s h o l d IoU(anchor_i, GT_j) > threshold IoU(anchori,GTj)>threshold,就让 a n c h o r i anchor_i anchori 去负责 G T j GT_j GTj 。
这就相当于你anchor框的数量没变,但是选择的正样本的比例增加了,就缓解了正负样本不均衡的问题。
- 2.Eliminate_grid sensitivity
还记得之前的YOLO v2的这幅图吗?YOLO v2,YOLO v3都是预测4个这样的偏移量
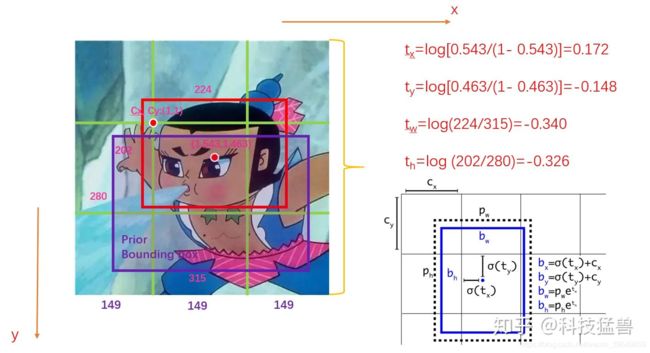
图3:YOLO v2,YOLO v3要预测的值
这里其实还隐藏着一个问题:
模型预测的结果是: t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th,那么最终的结果是: b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh 。这个 b b b 按理说应该能取到一个grid里面的任意位置。但是实际上边界的位置是取不到的,因为sigmoid函数的值域是:(0,1) ,它不是 [0,1] 。所以作者提出的Eliminate_grid sensitivity的意思是:将 b x , b y , b_x,b_y, bx,by, 的计算公式改为:
![]()
![]()
这里的1.1就是一个示例,你也可以是1.05,1.2等等,反正要乘上一个略大于1的数,作者发现经过这样的改动以后效果会再次提升。
- 3.CIoU-loss
之前的YOLO v2,YOLO v3在计算geo_loss时都是用的MSE Loss,之后人们开始使用IoU Loss。

它可以反映预测检测框与真实检测框的检测效果。
但是问题也很多:不能反映两者的距离大小(重合度)。同时因为loss=0,当GT和bounding box不挨着时,没有梯度回传,无法进行学习训练。如下图4所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差:

所以接下来的改进是:
![[公式]](http://img.e-com-net.com/image/info8/a19b5c7e12fc40fb86c11afefe600d51.jpg)
, C C C为同时包含了预测框和真实框的最小框的面积。
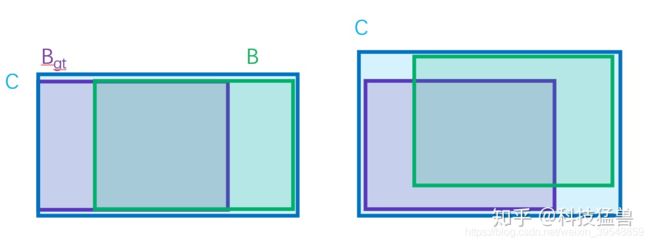
GIoU Loss可以解决上面IoU Loss对距离不敏感的问题。但是GIoU Loss存在训练过程中发散等问题。
接下来的改进是:
![]()
其中, b b b , b g t b^{gt} bgt 分别代表了预测框和真实框的中心点,且 ρ \rho ρ代表的是计算两个中心点间的欧式距离。 c c c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。

DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
DIoU loss除了这一点之外,还有一个好处是:

如上图所示,此3种情况IoU Loss和GIoU loss都一样,但是DIoU Loss右图最小,中间图次之,左图最大。
这里就是一道面试题:请总结DIoU loss的好处是?
答:
收敛快(需要的epochs少)。
缓解了Bounding box全包含GT问题。
但是DIoU loss只是缓解了Bounding box全包含GT问题,依然没有彻底解决包含的问题,即:

这2种情况 b b b 和 b g t b^{gt} bgt是重合的,DIoU loss的第3项没有区别,所以在这个意义上DIoU loss依然存在问题。
接下来的改进是:
惩罚项如下面公式:

其中 α \alpha α是权重函数,而 v v v用来度量长宽比的相似性,定义为:

完整的 CIoU 损失函数定义:

最后,CIoU loss的梯度类似于DIoU loss,但还要考虑 v v v的梯度。在长宽在 [0,1] 的情况下, w 2 + h 2 w^2 + h^2 w2+h2的值通常很小,会导致梯度爆炸,因此在 1 w 2 + h 2 \frac{1}{w^2+h^2} w2+h21实现时将替换成1。
所以最终的演化过程是:
MSE Loss —> IoU Loss —> GIoU Loss —> DIoU Loss —> CIoU Loss
所以YOLO- V4的损失函数改为:

2.5 YOLO-V5
关于v5,议论纷纷,主要是觉得创新性不足吧。主要的改进是改成自适应anchor了。详见:
深入浅出Yolo系列之Yolov5核心基础知识完整讲解
2.6 关于backbone的改进
上面主要定位于检测头的改进,其实backbone的改进也是至关重要,尤其是v3中为什么可以多那么多检测头,核心原因就是Resent的出现。
具体详见:
YOLO系列对于backbone方面的优化和对输入端的改进
3 检测中常用模块
2.1 FPN上下文
Feature Pyramid Networks for Object Detection 论文笔记
对FPN的原理进行了分析,主要是论文解读。
一文看尽物体检测中的各种FPN
对2020年以来的各种FPN结构进行了总结对比。