python:使用knn训练mnist训练集
首先在:mnist训练集网站上下载4组训练测试数据:
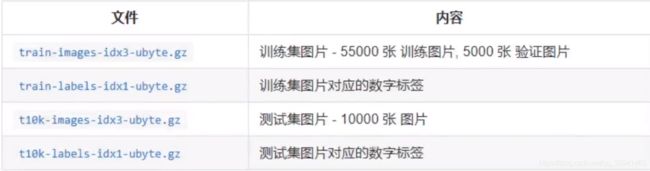
将四组数据放入knn训练项目下,如图:
在MNIST_data中放入这四个文件

然后在knn项目下新建一个knn_mnist.py文件,写入以下代码:
# @Time : 2019/10/24
# @File : knn_mnist.py
# @Author : Snipe
# @Contact : [email protected]
# @Software : Window10 + Python3.6 + PyCharm
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 1.load data 2 one_hot : 1 0000 1 fileName
# 2.knn下测试图片和训练图像的距离计算 5*500 = 2500 784维(宽乘高)
# 3.根据2.中的距离找到knn中k个最近的图片,我们使用5张测试图片和500张训练图片做差,每1张测试图片-->500张训练图像,然后在500张训练图像中找到4张和测试图片最接近的训练图像
# 4.k个最近的图片-->获得它的label
# 5.label-->具体的数字
# 6.完成检测概率的统计
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 属性设置
trainNum = 55000
testNum = 10000
trainSize = 500
testSize = 5
k = 4
# data 分解 trainSize 范围0-trainNum replace=False
trainIndex = np.random.choice(trainNum, trainSize, replace=False)
print(trainIndex)
testIndex = np.random.choice(testNum, testSize, replace=False)
print(testIndex)
trainData = mnist.train.images[trainIndex] # 训练图片
trainLabel = mnist.train.labels[trainIndex] # 训练标签
testData = mnist.test.images[testIndex]
testLabels = mnist.test.labels[testIndex]
print('trainData.shape = ', trainData.shape) # (500,784) (图片个数,28*28=784) # 加载的图片是28*28的
print('trainLabel.shape = ', trainLabel.shape) # (500,10)
print('testData.shape = ', testData.shape) # (5,784)
print('testLabel.shape', testLabels.shape) # (5,10) (代表5行10列)
print('testLabel = ', testLabels)
# tf input()
trainDataInput = tf.placeholder(shape=[None, 784], dtype=tf.float32)
trainLabelInput = tf.placeholder(shape=[None, 10], dtype=tf.float32)
testDataInput = tf.placeholder(shape=[None, 784], dtype=tf.float32)
testLabelsInput = tf.placeholder(shape=[None, 10], dtype=tf.float32)
# knn distance
f1 = tf.expand_dims(testDataInput, 1) # 5*784-->5*1*784 维度扩展
f2 = tf.subtract(trainDataInput, f1)
f3 = tf.reduce_sum(tf.abs(f2), reduction_indices=2) # 完成数据累加 784 abs
# f3表示距离是一个5*500的矩阵,[输入的测试图片的下标,输入的训练图片的下标]
f4 = tf.negative(f3) # 取反
f5, f6 = tf.nn.top_k(f4, k=4) # 选取f4中最大的4个值
# f5最小的四个值
# f6 index-->trainLabelInput
f7 = tf.gather(trainLabelInput, f6)
# f8 数字的获取 reduce_sum()函数就是一个累加的过程,累加成一个1维的数据
f8 = tf.reduce_sum(f7, reduction_indices=1)
# 选取在某一个维度上最大的值,并记录它的下标index
f9 = tf.argmax(f8, dimension=1) # f9的内容就是所有的检测图片(本例中为5),即5个image检测出来的5个num
with tf.Session() as sess:
p1 = sess.run(f1, feed_dict={testDataInput: testData[0:testSize]})
print('p1 = ', p1.shape) # p1 = (5,1,784)
p2 = sess.run(f2, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize]})
print('p2 = ', p2.shape) # p2 = (5,500,784) (1,100)
p3 = sess.run(f3, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize]})
print('p3 = ', p3.shape)
print('p3[0,0]', p3[0, 0]) # [0,0]坐标下训练图像和测试图像的距离差值
p4 = sess.run(f4, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize]})
print('p4 = ', p4.shape)
print('p4[0,0]', p4[0, 0])
p5, p6 = sess.run((f5, f6), feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize]})
# p5 = (5, 4)
# p6 = (5, 4)
print('p5 = ', p5.shape)
print('p6 = ', p6.shape)
print('p5[0,0]', p5[0, 0])
print('p6[0,0]', p6[0, 0]) # p6 index
p7 = sess.run(f7, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize],
trainLabelInput: trainLabel})
print('p7 = ', p7.shape) # p7 = {5,4,10}
print('p7[ ] = ', p7)
p8 = sess.run(f8, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize],
trainLabelInput: trainLabel})
print('p8 = ', p8.shape)
print('p8[ ] = ', p8)
p9 = sess.run(f9, feed_dict={trainDataInput: trainData,
testDataInput: testData[0:testSize],
trainLabelInput: trainLabel})
print('p9 = ', p9.shape)
print('p9[ ] = ', p9)
p10 = np.argmax(testLabels[0:testSize], axis=1)
print('p10[] = ', p10)
j = 0
for i in range(0, testSize):
if p10[i] == p9[i]:
j = j+1
print('ac = ', j*100/testSize, '%')
运行结果如下:
![]()