MAML:User Diverse Preference Modeling by Multimodal AttentiveMetric Learning
一、摘要
大多数现有的推荐系统用特征向量表示用户的偏好,当预测该用户对不同项目的偏好时,假设该特征向量是固定的。然而,同一个向量不能准确地捕捉用户对所有项目的不同偏好,特别是在考虑各种项目的不同特征时。为了解决这个问题,在本文中,提出了一种新的多模态注意度量学习(MAML)方法,以模拟用户对各种项目的不同偏好。特别是,对于每个用户项目对,提出了一个注意力神经网络,它利用项目的多模态特征来估计用户对该项目不同方面的特殊注意力。
MAML和CML之间的唯一区别是前者通过使用注意力机制来模拟用户的不同偏好。
二、介绍
仅仅依赖交互信息也会导致一些缺点,例如
1)无法在特征级别或方面级别对细粒度用户偏好进行建模;
2)当项目或用户的交互数据不足时的性能退化问题
在附带信息中,用户评论包含用户对项目不同方面的意见,因此已被广泛用于建模细粒度用户偏好。此外,物品图像有助于捕捉用户对物品视觉外观的偏好,这在时尚推荐中得到了广泛探索。
不同类型的辅助信息被认为是相互补充的。
用户对项目各个方面的偏好不同是很常见的,即使项目属于同一类别,用户也不会平等对待不同项目的各个方面。大多数现有的推荐方法都使用相同的向量来表示用户对所有项目的偏好,这无法准确预测各种项目的不同偏好。

三、模型介绍

我们认为使用相同的向量pu来预测用户对所有项目的偏好可能不是最优的,因为在真实场景中,用户对不同项目的偏好是不同的,这是很常见的。例如,偏好餐厅口味和价格的用户可能会更关注另一家餐厅的氛围和服务,因为这两家餐厅的服务目的不同。当预测用户u对项目i的偏好时,u最关注的项目i的那些方面应该主导用户对项目i。
提出了一种多模态注意度量学习(MAML)模型。对于每个用户项(u,i)对,模型计算权重向量au,i∈ Rf表示i的方面对u的重要性。此外,利用项目的辅助信息来估计权重向量,因为辅助信息传达了项目的丰富特征,特别是文本评论和项目图像,它们被公认为在不同方面提供项目的显著和互补特征[9,54]。我们采用注意力机制的最新进展[6,10]来估计注意力向量。使用注意力(权重)向量,用户u与模型中项目i之间的欧几里德距离变为:

是点乘哦!
使用注意力向量,模型不仅可以准确捕捉用户对于不同的项目的不同偏好,还解决了CML中的几何限制问题,从等式1中可以发现,CML试图将用户和所有交互项目放入潜在空间中的同一点,然而,每个项目又有许多交互用户。由于aui对于每个用户-项目对都是唯一的,因此它作为一个转换向量,将目标用户和项目转换为一个新的距离计算空间。
采用成对学习进行优化,损失函数定义为:
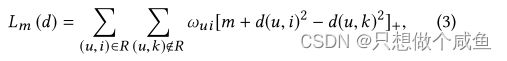
ωui是分级损失权重(见第3.2.3节),m>0是安全边际大小。
1、注意机制
用于捕获用户u对项目i的特定注意力aui。由于文本评论和图像包含关于用户偏好和项目特征的丰富信息,因此它们用于捕获用户对i各个方面的注意力。使用两层神经网络计算注意力向量:
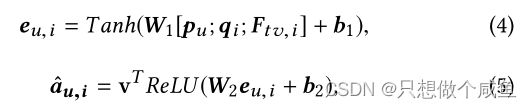
v是将隐藏层投影到输出注意力权重向量中的向量。Ftv,i是项目特征向量,其是i的文本特征和图像特征的融合(稍后描述)
接下来有一个步骤用softmax函数来规范化(normalize)aui,该函数将注意力权重转换为概率分布。不幸的是,这种标准解决方案在实践中并不奏效。这是因为在我们的模型中,注意力权重直接用于元素与pu和qi之间的欧氏距离的乘积(见等式2)。对于每个维度l,加权距离
![]()
。在softmax标准化之后,权重将非常小。例如,当维度f为100时,权重的平均值仅为0.01。请注意,pu和qi的每个维度之间的距离已经很小了。
在这样小的权重au,i,l的情况下,距离du,i,i变得更小。当所有维度的距离都很小时,不同维度(方面)之间的差异可以忽略不计。这将削弱我们模型的识别能力,导致性能下降。为了缓解这个问题,我们建议将归一化权重放大一个因子α。在我们的模型中,最终注意力权重向量计算如下:

将α设置为权重向量的维数,即α=f,这种设置的动机是考虑到,当权重向量为二进制时,只有权重为1的方面才会对最终决策产生影响,而极端的情况是所有方面都具有相同的重要性。接下来,我们将介绍如何获得融合项目特征向量Ftv,i。
2、项目特征
对于每个项目,其文本和视觉特征都是从其相关评论和图像中提取的。
文本特征Ft,i由PV-DM[28]模型提取,该模型以无监督的方式学习文本文档的连续分布向量表示。
视觉特征Fv,i由Caffe参考模型[23]提取,该模型由5个卷积层和3个完全连接层组成。
在提取项目的文本和视觉特征后,我们将其融合以更好地表示项目的特征,采用了广泛使用的策略文本和视觉特征,然后将其输入多层神经网络。

即Ftv,i=zL。注意到,我们在本文中的重点是开发项目的多模态特征,以捕捉用户对各种项目的不同方面的不同关注。
3、权重损失进行排名
采用加权近似等级成对(W ARP)损失[48]来计算ωui。该方案对较低等级的正项目的惩罚比最高等级的更严重,

在W ARP中,rankd(u,i)是通过一个连续采样过程来估计的,该过程重复采样负项以找到冒名顶替者。对于每个用户项对(u,i),设J表示项的总数,M表示N个样本中的冒名顶替者的数量。rankd(u,i)近似为⌊(J×M)/N⌋
WARP:
正面标签在标签列表中排名靠前,那么将为损失分配一个小权重,并且不会花费太多损失。但是,如果正面标签没有排在最前面,将为损失分配更大的权重,从而将正面标签推到顶部。
4、正则化
由于文本评论和项目图像代表项目的特征,我们希望具有相似文本和视觉特征的项目在潜在特征向量中更接近。为了实现该目标,我们定义了以下L2损失函数,

当qi偏离提取的特征Ftv,i时,该函数惩罚项目i的特征向量qi。
为了防止特征空间中每个维度的冗余,我们然后使用另一种正则化技术,协方差正则化[13]来减少深度神经网络中激活之间的相关性。该技术也可以在我们的模型中用于去关联特征空间中的维度,从而最大化给定空间的利用率。设yn表示对象的潜在向量,可以是用户或项目;并且n对大小为n的一批中的对象进行索引。矩阵C中所有维度对i和j之间的协方差定义为:

我们定义损耗Lc以正则化协方差:

5、最终的优化器
考虑到所有正则化项,我们的MAML的最终目标函数是,

四、实验部分
1、总体对比
方法在所有测试数据集上在不同指标方面始终优于所有竞争对手

MAML和CML之间的唯一区别是前者通过使用注意力机制来模拟用户的不同偏好。
2、注意机制的影响
将所有注意权重的总和放大一个因子α来调整标准注意机制。α的值被设置为等于用户/项目特征向量的维数,即α=f

注 意力向量au,i表征了用户对项目不同方面的注意力。