python机器学习 | K近邻算法学习(1)
K近邻算法学习
- 1 K近邻算法介绍
-
- 1.1算法定义
- 1.2算法原理
- 1.3算法讨论
-
- 1.3.1 K值选择
- 1.3.2距离计算
- 1.3.3 KD树
- 2 K近邻算法实现
-
- 2.1scikit-learn工具介绍
- 2.2scikit-learn实现K近邻算法——分类问题
- 2.3scikit-learn深入(流程)介绍- 以鸢尾花数据为例
-
- 2.3.1数据集获取
- 2.3.2特征直观绘图
- 2.3.3数据分割
- 2.3.4 处理特征化工程
- 2.3.5 交叉验证、网格搜索api
-
- 2.3.5.1交叉验证
- 2.3.5.2网格搜索
- 2.3.5.3交叉验证、网格搜索api
1 K近邻算法介绍
1.1算法定义
(1)K-近邻(K-Nearest Neighboor)算法定义:
基于检测样本与k个在特征空间中最相似的样本中的多数类别,来推测样本是属于哪一个类别。
(2)举个例子理解:
已知《战狼》《红海行动》《碟中谍 6》是动作片,而《前任 3》《春娇救志明》《泰坦尼克号》是爱情片。但是如果一旦现在有一部新的电影《美人鱼》,有没有一种方法让机器也可以掌握一个分类的规则,这里的分类规则就是特征,自动的将新电影进行分类?
在这里,我们将打斗次数和接吻次数视作我们提取的特征。然后我们就看《美人鱼》的打斗次数和接吻次数和哪个或者哪些片子(哪个或者哪些就是K)的特征分布最为相似或相近,进而根据哪个或者哪些片子主导什么类型进行《美人鱼》影片类型的定义。
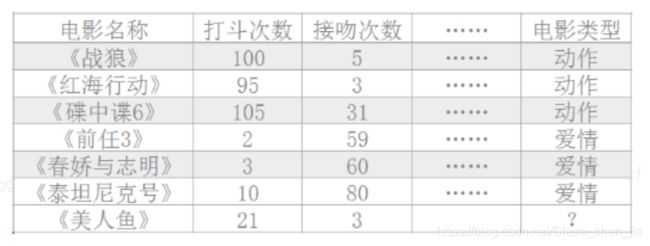
当然,我们可以先直接对各个影片特征进行可视化分析,得出直观结论。如:
# 导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# 设置数据
x = [5,3,31,59,60,80,20]
y = [100,95,105,2,3,10,3]
labels = ["《战狼》","《红海行动》","《碟中谍6》","《前任3》","《春娇与志明》","《泰坦尼克号》","《美人鱼》"]
plt.scatter(x,y,s=120)
plt.xlabel("亲吻次数")
plt.ylabel("打斗次数")
plt.xticks(range(0,150,10))
plt.yticks(range(0,150,10))
count = 0
for x_i,y_i in zip(x,y):
plt.annotate(f"{labels[count]}",xy=(x_i,y_i),xytext=(x_i,y_i))
count+=1

1.2算法原理
通过图片展示,我们可以发现《美人鱼》与《春娇与志明》距离最相近,而《春娇与志明》又是爱情片,所以《美人鱼》就是爱情片。
通过这里,我们就知道它是通过特征空间的距离来预测分类的。但K是什么呢?又有什么用处呢?需要注意我们根据一个影片来推断硬盘类型太武断了,我们需要根据与它K个邻近的影片的主导类型来推断《美人鱼》属于哪一类才更准确。
那么下面我们就用编程来实现一下。问题来了:距离要用什么来算呢?我们常用的就是欧式距离,我们初高中就接触过了呀。
形式如下

大概计算方式如下.我们通过两种来实现,1种是糙的算一下各自距离,1种是根据K邻近来推断
# 1 粗糙的算一下各自距离
mv_df = pd.read_excel("电影数据.xlsx",sheet_name=0)
dis = np.sqrt((mv_df["打斗次数"] - mv_df.loc[6,"打斗次数"])**2 + (mv_df["接吻次数"] - mv_df.loc[6,"接吻次数"])**2)
mv_df["美人鱼和其他影片的特征距离"] = dis
mv_df # 美人鱼与前任三、春娇与志明距离最近
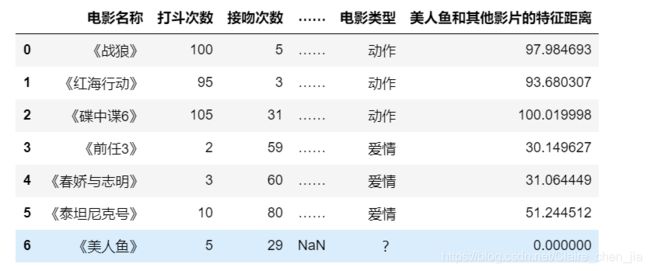
# 2 根据K邻近来推断
"""
- 准备 训练特征 + 训练目标
- 准备 预测数据
- 计算 预测数据 与 训练数据 的 欧氏距离
- 获取到 k个 欧氏距离最小的值
- 将获取到的 k个 临近的点 进行分类统计,谁占大头,预测值就属于哪个类
"""
"""
# 计算预测数据 与 训练数据的 距离
# 选择距离最小k个值
# 计算k个值当中 的类别 占比
"""
class MyKnn(object):
def __init__(self,train_df,k=3):
self.k = k
self.train_df = train_df
def predict(self,x_new_test):
# 计算距离列 添加列
self.train_df["dis"] = np.sqrt((x_new_test["打斗次数"]-self.train_df["打斗次数"])**2+(x_new_test["接吻次数"]-self.train_df["接吻次数"])**2)
# 获取距离最小的 前k个值 的类别
mv_types = self.train_df.sort_values(by="dis").iloc[:self.k]["电影类型"]
# 对k个点的分类进行统计,看谁占大头,预测值就属于哪个类
# value_counts 按值排序
new_mv_type = mv_types.value_counts().index[0]
return new_mv_type
def main():
# 1.读取数据
mv_df = pd.read_excel("电影数据.xlsx",sheet_name=0)
# 2.特征化特征:打斗次数,接吻次数 初始化目标(标签):电影类型
train_df = mv_df.loc[:5,["打斗次数","接吻次数","电影类型"]]
# 3.预测数据
x_new_test = mv_df.loc[6,["打斗次数","接吻次数"]]
# 4.实例化类 设定k值为3
mk = MyKnn(train_df,k=3)
new_mv_type = mk.predict(x_new_test)
print(f"预测类型为:{new_mv_type}")
main()
1.3算法讨论
1.3.1 K值选择
前文我们对K值是什么,应该有个大概的了解。那么K值该取多大呢?这就需要出于实际问题实际考虑了。具体而言:
1)如果 K 值比较小,就相当于未分类物体与它的邻居非常接近才行。这样产生的一个问题就是,如果邻居点是个噪声点,那么未分类物体的分类也会产生误差,这样 KNN 分类就会产生过拟合。
2)如果== K 值比较大==,相当于距离过远的点也会对未知物体的分类产生影响,虽然这种情况的好处是稳健性强,但是不足也很明显,会产生欠拟合情况,也就是没有把未分类物体真正分类出来。
所以 K 值应该是个实践出来的结果,并不是我们事先而定的。在工程上,我们一般采用交叉验证的方式选取 K 值。
交叉验证的思路就是,把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在 KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。
1.3.2距离计算
前面我们讲的是欧式距离的计算,常用有的距离计算方法有欧氏距离(欧几里得距离)、曼哈顿距离、闵可夫斯基距离、切比雪夫距离、余弦距离。
- 欧氏距离(欧几里得距离): 两点在n维空间中的距离
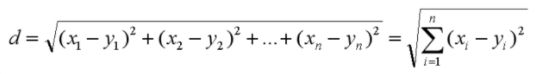
- 曼哈顿距离:在几何空间中用的比较多
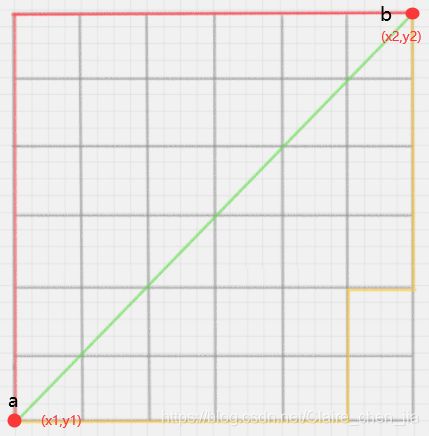
二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离:
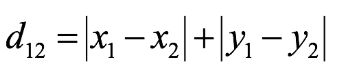
n维空间点(x11,x12,…,x1n)与b(x21,x22,…,x2n)的曼哈顿距离:

- 切比雪夫距离:在国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
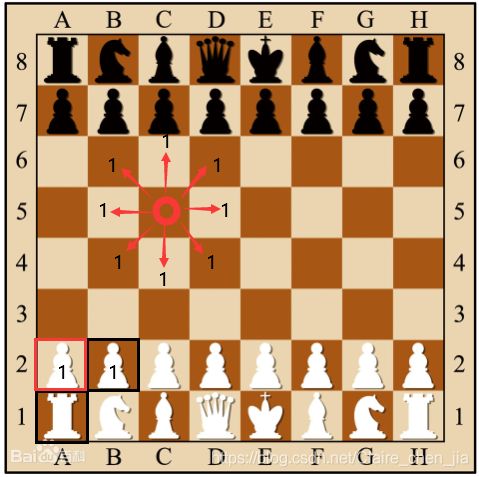
二维平面两点a(x1,x2)与b(x2,y2)间的切比雪夫距离:

n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的切比雪夫距离:

- 闵可夫斯基距离:一类距离的统称,是对多个距离度量公式的概括性的表述。
其中p是一个变参数:
• 当p=1时,就是曼哈顿距离;
• 当p=2时,就是欧氏距离;
• 当p→∞时,就是切比雪夫距离。
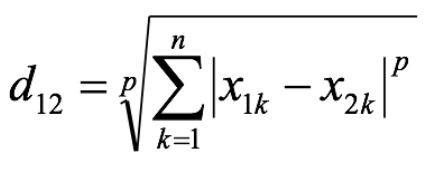
- 余弦距离:计算的是两个向量的夹角,是在方向上计算两者之间的差异,对绝对数值不敏感。两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦为:
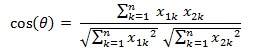
1.3.3 KD树
KNN 的计算过程是大量计算样本点之间的距离。为了减少计算距离次数,提升 KNN 的搜索效率,人们提出了 KD 树(K-Dimensional 的缩写)。KD 树是对数据点在 K 维空间中划分的一种数据结构。在 KD 树的构造中,每个节点都是 k 维数值点的二叉树。既然是二叉树,就可以采用二叉树的增删改查操作,这样就大大提升了搜索效率。
2 K近邻算法实现
先总结KNN工作流程:
• 1.计算待分类物体与其他物体之间的距离;
• 2.统计距离最近的 K 个邻居;
• 3.对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
2.1scikit-learn工具介绍
scikit-learn 是基于 Python 语言的机器学习工具。
(1)特点:
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
(2)学习文档:http://scikitlearn.com.cn/ (文档是中文的,可以学习一下噢~)
(3)安装:pip3 install scikit-learn
注意:安装scikit-learn需要Numpy,Scipy等库
2.2scikit-learn实现K近邻算法——分类问题
步骤:
- 构建特征数据与目标数据
- 构建k个近邻的分类器
- 使用fit进行训练
- 预测数据
语法:sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto5)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}, 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索.
1)auto理解为算法自己决定合适的搜索算法。
2)brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
3)kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
4)ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
"""简单原理实现"""
from sklearn.neighbors import KNeighborsClassifier
x = [[-1],[-2],[2],[3]] # 构建特征数据:x为训练集样本的特征工程,这里训练集有4个样本,特征为一维
y = [0,0,1,1] # 构建目标数据:y为训练集样本的目标,有4个样本,所以有4个目标值,目标分类为0或者1
estimator = KNeighborsClassifier(n_neighbors=2) # 构建k个近邻的分类器: k邻近值设置为2
estimator.fit(x,y) # 使用fit进行训练
estimator.predict([[5]]) # 预测集为5 ,结果(目标):array([1])
"""电影分类api实现"""
from sklearn.neighbors import KNeighborsClassifier
# 1.读取数据
mv_df = pd.read_excel("电影数据.xlsx",sheet_name=0)
# 2.构建训练集的特征数据
x = mv_df.loc[:5,"打斗次数":"接吻次数"].values
# 3.构建训练集的目标数据
y = mv_df.loc[:5,"电影类型"].values
# 4.实例化api k值为4
knn_cls = KNeighborsClassifier(n_neighbors=4)
# 5.进行训练
knn_cls.fit(x,y)
# 6.预测数据 美人鱼 结果:array(['爱情'], dtype=object)
knn_cls.predict([[5,29]])
2.3scikit-learn深入(流程)介绍- 以鸢尾花数据为例
2.3.1数据集获取
sklearn.datasets 加载获取流行数据集
• datasets.load_***() 获取小规模数据集,数据包含在datasets里
• datasets.fetch_***(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
from sklearn.datasets import load_iris,fetch_20newsgroups
iris = load_iris()
iris
news = fetch_20newsgroups()
news
"""
返回集
load和fetch返回的数据类型(字典格式)
• data:特征数据数组
• target:标签数组
• DESCR:数据描述
• feature_names:特征名
• target_names:标签名
"""
from sklearn.datasets import load_iris
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
2.3.2特征直观绘图
import seaborn as sns
# 构建dataframe数据
iris_data = pd.DataFrame(data=iris.data,columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'])
# iris_data.head()
# 添加target目标列
iris_data["target"] = iris.target
iris_data
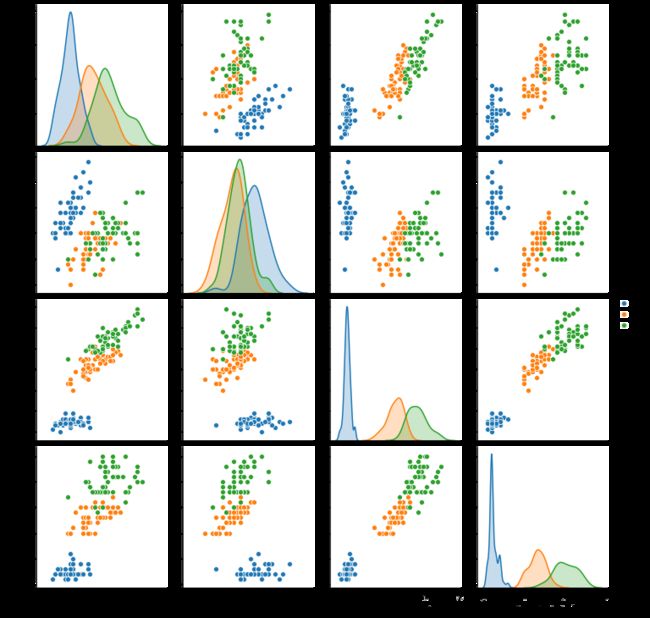
# 两两特征之间的关系对分类的影响
sns.pairplot(iris_data,hue="target")
2.3.3数据分割
(1)数据分割规则
• 训练数据:用于训练,构建模型
• 测试数据:在模型检验时使用,用于评估模型是否有效。
(2)划分比例:
• 训练集:70% 80% 75%
• 测试集:30% 20% 25%
(3)数据分割api
sklearn.model_selection.train_test_split(arrays, *options)
sklearn.model_selection.train_test_split(x,y,test_size=,random_size)
参数解释:
• x 数据集的特征值
• y 数据集的标签值
• test_size 测试集的大小,一般为float
• random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
• 返回值: 训练特征值,测试特征值,训练目标值,测试目标值
from sklearn.model_selection import train_test_split
# iris.data:特征值;iris.target:目标值 test_size:测试集的大小
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2)
print("训练集的特征值:",x_train)
print("测试集的特征值:",x_test)
print("训练集的目标值:",y_train)
print("测试集的目标值:",y_test)
print("训练集的目标值形状:",y_train.shape) # 120/150
print("测试集的目标值形状:",y_test.shape) # 30/150
# 随机数种子,不同种子造成不同的随机采样结果。相同的种子采样结果一致
x_train1,x_test1,y_train1,y_test1 = train_test_split(iris.data,iris.target,test_size=0.2,random_state=2)
x_train2,x_test2,y_train2,y_test2 = train_test_split(iris.data,iris.target,test_size=0.2,random_state=23)
x_train3,x_test3,y_train3,y_test3 = train_test_split(iris.data,iris.target,test_size=0.2,random_state=23)
print(y_test1)
print(y_test2)
print(y_test3)
"""
[0 0 2 0 0 2 0 2 2 0 0 0 0 0 1 1 0 1 2 1 1 1 2 1 1 0 0 2 0 2]
[2 2 1 0 2 1 0 2 0 1 1 0 2 0 0 2 1 1 2 0 2 0 0 0 2 0 0 2 1 1]
[2 2 1 0 2 1 0 2 0 1 1 0 2 0 0 2 1 1 2 0 2 0 0 0 2 0 0 2 1 1]
"""
2.3.4 处理特征化工程
处理特征化工程就是处理特征里存在的异常值,消除可能存在的偏误。常用方法有归一化和标准化(之前在数据分析那一块也有讲过)。所以简单提一下就好啦
- 归一化特征工程(将原始数据映射到[0,1]之间)
公式:
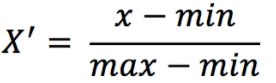
归一化api:sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
• MinMaxScalar.fit_transform(X)
• X:numpy array格式的数据[n_samples,n_features]
评价:归一化只是减轻了波动性,完整消除异常值影响。如如有一个值错误,它是最大值,那么就会影响整体的数值,并且归一化是无法解决这个异常值。所以归一化只适合传统精确小数据场景
- 标准化特征工程(将原始数据转为正态分布:均值为0,标准差为1范围内)
公式:

标准化api:sklearn.preprocessing.StandardScaler( )
• 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
• StandardScaler.fit_transform(X)
• X:numpy array格式的数据[n_samples,n_features]
下面示例一哈:
数据来源
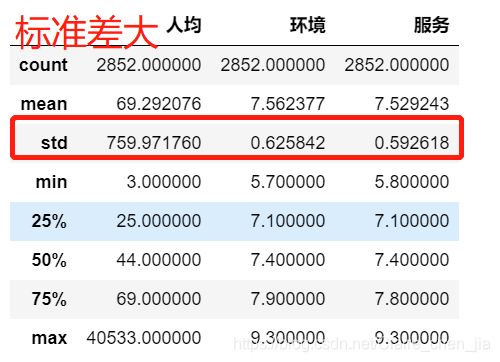
data = pd.read_csv("餐饮.csv",encoding="gbk",usecols=["人均","环境","服务"]).dropna()
data.info()
data.describe()
"""
导入归一化api模块和标准化api模块
归一化api: MinMaxScaler
标准化api:StandardScaler
"""
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import pandas as pd
"""
归一化:
1)实例化一个转换器
2)调用 fit_transform 注意:传入dataframe
"""
# 实例化一个转换器
transfer = MinMaxScaler(feature_range=(0,1))
# 调用 fit_transform 注意:传入dataframe
min_max_data = transfer.fit_transform(data)
min_max_data

"""
标准化:
1)实例化一个转换器
2)调用 fit_transform 注意:传入dataframe
"""
# 实例化一个转换器
s_tran = StandardScaler()
# 调用 转换 方法
standar = s_tran.fit_transform(data)
standar

2.3.5 交叉验证、网格搜索api
2.3.5.1交叉验证
在K值选择那里,我们说过可以采用交叉验证,选择适合的K值,并且提到交叉验证的思路就是,把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。
我们讲到KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。那么现在就来讲一下交叉验证是什么东东?
交叉验证(Cross Validation)也称为循环估计(Rotation Estimation),在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和。
那么在KNN它是如何应用的呢?简单来讲,假设交叉验证参数设定为10份,循环取其中的一份作为预测集,其他部分作为训练集。然后利用训练集训练出来的模型预测测试集。接着,计算测试集的RMSE,判断模型的稳定性。

简而言之,交叉验证目的是为了得到可靠稳定的模型。它通常与网格搜索相结合
2.3.5.2网格搜索
网格搜索(Grid Search)用简答的话来说就是你手动的给出一个模型中你想要改动的所用的参数,程序自动的帮你使用穷举法来将所用的参数都运行一遍。
2.3.5.3交叉验证、网格搜索api
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
• estimator:估计器对象
• param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]} (这里就是K值的选择)
• cv:指定几折交叉验证
# 建立模型
knn = KNeighborsClassifier(n_neighbors=7)
# 交叉验证网格搜索
params_grid = {"n_neighbors":[1,3,5,7,9]}
knn = GridSearchCV(knn,param_grid=params_grid,cv=3)
# 训练
knn.fit(x_train,y_train)