全连接神经网络
#下面的代码是完成常用数据集Fashion-MNIST时尚物品的识别,每一行代码尽可能的都给出了详细注解
# -!- coding: utf-8 -!- #防止中文乱码
import tensorflow as tf #导入tensorflow库
import matplotlib.pyplot as plf #matplotlib.pyplot是一个有命令风格的函数集合
from tensorflow import keras #从tensorflow库中导入keras,tf.keras是Keras API在TensorFlow里的实现,是一个高级API,用于构建和训练模型
fashion_mnist = keras.datasets.fashion_mnist #keras中数据集主要有7种(可从官方文档阅读) 地址:https://keras.io/zh/datasets/#fashion-mnist
(train_images,train_labels), (test_images,test_labels) = fashion_mnist.load_data() #train_images等等是unit8数组表示的灰度图像,load_data()是加载keras自带数据集的方法
#构造神经元模型
model = keras.Sequential([ #序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。
keras.layers.Flatten(input_shape=(28,28)), #输入层定义(延展),特征图是28*28像素的参考下面解析中的一(全连接层输入为什么是固定维度?)
keras.layers.Dense(128,activation=tf.nn.relu),#中间层128个神经元,keras,layers.Dense()是定义网络层的基本方法,activation是激活函数,tf.nn.relu是一个激活函数,即max(features,0),将大于0的保持不变,小于0的数置为0
keras.layers.Dense(10,activation=tf.nn.softmax) #输出层10个神经元,激活函数softmax的作用就是归一化,作用就是把一个序列变成概率,激活函数可以详细参考下面的解析二
])
model.summary() #查看神经元模型结构
train_images_scaled=train_images/255 #训练集数据的标准化
model.compile(optimizer=tf.optimizers.Adam(),loss=tf.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
'''
optimizer(优化器):优化器是编译Keras模型所需的两个参数之一
Adam是其中一个优化器 (详见https://keras.io/zh/optimizers/#adam)
loss是损失函数(或称目标函数、优化评分函数)是编译Keras模型所需的两个参数之一
详见Keras官方文档,这里不赘述 https://keras.io/zh/losses/#categorical_crossentropy
metrics是评价函数,用于评估当前训练模型的性能,
accuracy是我们比较熟悉的评价方法
该accuracy就是大家熟知的最朴素的accuracy。比如我们有6个样本,其真实标签y_true为[0, 1, 3, 3, 4, 2],但被一个模型预测为了[0, 1, 3, 4, 4, 4],即y_pred=[0, 1, 3, 4, 4, 4],那么该模型的accuracy=4/6=66.67%。
'''
#模型的训练
model.fit(train_images_scaled,train_labels,epochs=5)
#参考解析三fit的完整用法test_images_scaled=test_images/255 #测试集数据的标准化
model.evaluate(test_images_scaled,test_labels)
#loss,accuracy=model.evaluate(X_test,Y_test),在这里,loss是输出损失,accuracy是精确度,X_test是输入数据,Y_test是标签
import numpy as np #numpy是python语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
import matplotlib.pyplot as plt #这就是之前说的绘图库了
print(np.argmax(model.predict((test_images[1]/255).reshape(1,28,28,1))))
'''
numpy.argmax(array,axis)用于返回一个numpy数组中最大值的索引值,在这里其实就是选择出概率最大的那个类别
y_pred = model.predict(X_test,batch_size = 1),在这里,y_pred是输出预测结果,X_test是输入测试集,batch_size是数量,在这里要注意的是他把测试图像归一化之后又重构了,详见解析四为什么要重构。
'''
print(test_labels[1])
plt.imshow(test_images[1])
plt.show()总结一下我们完成keras中自带的Fashion-MNIST 时尚物品数据集的识别需要下面这4个过程。
加载数据集->构建模型->训练模型->模型验证
一.全连接层输入为什么是固定维度?
全连接层的计算其实相当于输入的特征图数据矩阵和全连接层权值进行一个内积,一定要注意的是在配置一个神经网络的时候,全连接层的参数维度是固定的(是先w设定的),所以两个矩阵要能够进行内积,那么输入的特征图的数据矩阵维数也一定要固定,否则无法内积(线性代数的知识)
全连接层需要我们把输入拉直成一个列向量,比如我们需要输入的一个图是3*3,那么就需要把这个图拉成4*1的列向量,如果这是一个彩色图,那么它的channels是3(彩色为3,灰色为1),也就是你的输入是(2*2)*3,那么其实就相当于有12个像素点,我们这时候拉成了12*1的列向量,根据线性代数的知识,这个权重矩阵形式必然是1*12,所以他在经过一个全连接层的输出就是1*1,这个时候就看我们需要多少个输出神经元了,如果是3个的话,那么输出就是3*(1*12*12*1)=3*(1*1)
画一个图来理解一下

这个图勉强看一下......
二.激活函数
激活函数可以通过设置单独的激活层实现,也可以在构造层对象时通过传递activation参数实现,在上面的代码例子中我们是通过传递activation参数实现的。
#设置单独的激活层
model.add(Dense(64))
model.add(Activation('tanh'))
#在构造层对象时通过传递activation参数实现
model.add(Dense(64, activation='tanh'))常见预定义激活函数
- softmax(softmax激活函数,注意返回的是softmax变换后的张量,张量在解析五中有提到)[常用]
- elu(指数线性单元)
- selu(可伸缩的指数线性单元)
- softsign(softsign激活函数)
- relu(整流线性单元)[常用]
- tanh(双曲正切激活函数)
- sigmoid(sigmoid激活函数)[常用]
- hard_sigmoid(hard sigmoid激活函数,注意计算速度比sigmoid激活函数更快)
- exponetial(自然数指数激活函数)
- linear(线性激活函数,即不做任何改变)
当然也会有一些TensorFlow不能表达的复杂激活函数,比如里面含有可学习参数的激活函数,可以通过高级激活函数实现。
三.模型训练函数fit的完整用法
fit的完整用法:
fit(x,y,batch_size=32,epochs=10,verbose=1,callbacks=None,validation_split=0.0,validation_data=None,shuffle=True,class_weight=None,sample_weight=None,initial_epoch=0)
x:输入数据
y:标签,numpy array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数,训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步
epochs:整数,几轮迭代时停止
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,这个list中的回调函数将会在训练过程的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来制定训练集的一定比例数据作为验证集。验证集将不会参与训练,并在每个epoch结束后测试模型的指标,如损失函数、精确度。需要注意的就是validation_split的划分在shuffle之前,因此如果你的数据本身是有序的需要先手工打乱再制定validation_split,否则可能会出现验证集样本不均匀,一定要注意先手工打乱。validation_data:形式为(x,y)的tuple,是指定的验证集。这个参数将会覆盖validation_split
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
这个参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。比如:异常检测的二项分类问题,异常数据仅占1%,正常数据占99%,此时就要设置不同类对损失函数的影响。如果没有给出具体的class_weight,则所有类都被假设为占有相同的权重1,模型会根据数据原来的状况去训练,如果希望改善样本不均衡状况,应输入形如{"标签的值1:权重1,标签的值2:权重2}的字典,则参数C将会自动被设为:标签的值的1的C:权重1*C,标签的值2的C:权重2*C,或者,可以使用"balanced"模式,这个模式使用y的值自动调整与输入数据中的类频率成反比的权重为n_samples/(n_classes*np.bincount(y))
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode='temporal'。 sample_weight主要解决的是样本质量不同的问题,比如前1000个样本的可信度,那么它的权重就要高,后1000个样本可能有错,不可信,那么权重就要降低。
initial_epoch:从该参数指定的epoch开始训练,在继续之前的训练时有用。
四.为什么要重构?
这一部分一定要注意,因为还是挺重要的
首先我们需要介绍一下reshape函数
numpy.reshape(a,newshape,order='C')
作用:给数组一个新的形状而不改变其数据
参数:
- a:array_like 要重新形成的数组。
- newshape:int或tuple的整数 新的形状应该与原始形状兼容。如果是整数,则结果将是该长度的1-D数组。一个形状维度可以是-1。在这种情况下,从数组的长度和其余维度推断该值。
- order:{'C','F','A'}可选,使用此索引顺序读取a的元素,并使用此索引顺序将元素放置到重新形成的数组中,'C'意味着使用C样索引顺序读取/写入元素,最后一个轴索引变化最快,回到第一个轴索引变化最慢。'F'意味着使用Fortran样索引顺序读取/写入元素,第一个索引变化最快,最后一个索引变化最慢,我们要注意的就是'C'和'F'选项不考虑底层数组的内存布局,而只是参考索引的顺序。'A'意味着在Fortran类索引顺序中读/写元素,如果a是Fortran在内存中连续的,否则为C样顺序。
返回:reshaped_array:ndarray。如果可能,这将是一个新的视图对象;否则,它将是一个副本。注意,不能保证返回数组的内存布局(C-或Fortan-连续)
注意:通过reshaple生成的新数组和原数组共用一个内存,也就是说,你改了新数组其实就相当于改了原数组。
原则:数组元素不能发生改变
用法:
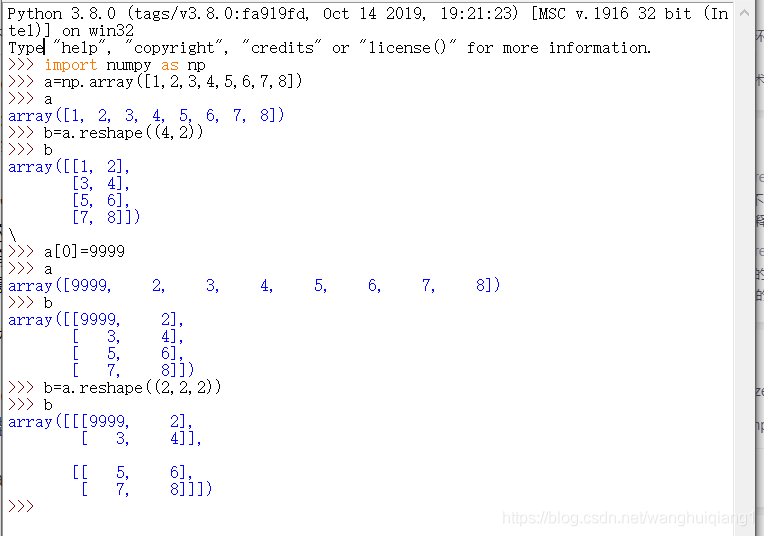
我们get到了reshpe的用法之后,上面的代码例子中的reshape可以这么理解
为什么要整形呢,因为我们的数据中每个样本是28*28列构成的向量,所以要输入的是1(预测一个图像)*784,但是输入到CNN中需要卷积,所以要求需要的每个样本都必须是矩阵,所以这时候我们就需要整形了。
在那里的整形是将数据集中的每个图像放入一个张量,Fashion-MNIST 时尚物品数据集是28*28像素的灰度图像,通道数为1,所以1是一个空维度(也就是通道数),用来匹配神经网络的输入形状。
如果改变一下条件的话,这里我们识别的图像数据集是RGB,你怎么存储呢,对于每个像素我们需要3个标量(每个标量对应一个通道)。所以他将是1*28*28*1,当图像为灰度时,需要多少个通道?只有一个,所以是1*28*28*1,当然你也可以看做是我们需要转换为大小为1、28、1、1的4维数组,用于0维到3维,整形重新排列给定数组,使其大小保持不变。
五.tensorflow中标量、向量、矩阵、张量
张量其实就是一个数据容器