day02-Knn、朴素贝叶斯、决策森林和随机森林
一、sklearn数据集
sklearn库中有自带的小数据集,也有从网下下载的某些数据集API
-
数据集划分
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
API: sklearn.model_selection.train_test_split
x_train, x_test, y_train, y_test =train_test_split(x,y,test_size=0.25)
注:训练集和测试集数据比例通常是0.75:0.25 -
sklearn数据集接口介绍
- 获取小规模数据集
from sklearn.datasets import load_*()

- 获取大规模数据集(在线下载)
from sklearn.datasets import fetch_*(data_home=None)
data_home为数据保存的地址
返回数据类型:load和fetch返回的数据类型均为datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维
numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名,回归数据集没有
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
print(li.data)
print(li.target)
x_train,x_test,y_train,y_test = train_test_split(li.data,li.target,test_size=0.25)
print(x_test)
二、转换器
- 定义: 转换器是指特征工程的API接口
- 转换器调用方法:
第一种:fit,transform
第二种:fit_transform - fit,transform,fit_transform的区别
fit: 不进行算法部分,只计算训练集的一些统计特性,例如均值,方差,最大值,最小值,类似于一个适配过程,为后续的API做准备
transform: 在fit的基础上,以fit计算出来的平均值、标准差来转换进行标准化,降维,归一化等操作
fit_transform:fit_transform是fit和transform的组合,既包括了适配又包含了转换
from sklearn.preprocessing import StandardScaler
In [2]: std = StandardScaler()
In [3]: a = [[1,2,3],[4,5,6]]
In [4]: std.fit_transform(a)
Out[4]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [5]: std.fit(a)
Out[5]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [6]: std.transform(a)
Out[6]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [7]: b = [[1,2,4],[8,10,14]]
In [8]: std.fit(b)
Out[8]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [9]: std.transform(a)
Out[9]:
array([[-1. , -1. , -1.2 ],
[-0.14285714, -0.25 , -0.6 ]])
三、估计器工作流程
估计器:是一类实现算法的API
- fit: 类似于训练过程,一般调用算法API时均先进行fit过程
- predict预测过程

- sklearn分类估计器
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
sklearn.tree 决策树与随机森林 - sklearn回归数估计器
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
四、k-近邻算法
- 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别(根据邻居来推断出自己的类别) - 特征
不同样本之间的特邻居征距离计算公式(欧式距离)
a样本:(a1,a2,a3), b样本:(b1,b2,b3)
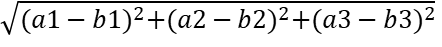
- K_近邻算法API
导包:
from sklearn.neighbors import KNeighborsClassifier
实例化:
knn = KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors: 选取的最邻近邻居数目,默认为5
algorithm: 算法运算中使用的数据结构算法,‘auto’将尝试根据传递给fit方法的值来决定最合适的数据结构算法。
算法实现
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test) 得出预测结果
score = knn.score(x_test, y_test) 计算准确率 - 算法优缺点
优点:简单,易于理解,易于实现,无需估计参数,无需训练
缺点:懒惰算法,对测试样本分类时的计算量大,内存开销大必须指定K值,K值选择不当则分类精度不能保证
# 使用knn算法预测用户签到地点
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knn():
# 读取数据
data = pd.read_csv("********")
# print(data.head(10))
# 处理数据
# 1、缩小数据,查询数据晒讯
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
print(time_value)
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# fit, predict,score
knn.fit(x_train, y_train)
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标签到位置为:", y_predict)
# 得出准确率
print("预测的准确率:", knn.score(x_test, y_test))
if __name__ == "__main__":
knn()
补充:
DataFrame.query(缩小准则) 缩小数据集的范围
pd.to_datetime(时间戳) 获取日期格式的时间
pd.DatetimeIndex(时间日期) 获取字典格式的时间
五、分类模型评估
-
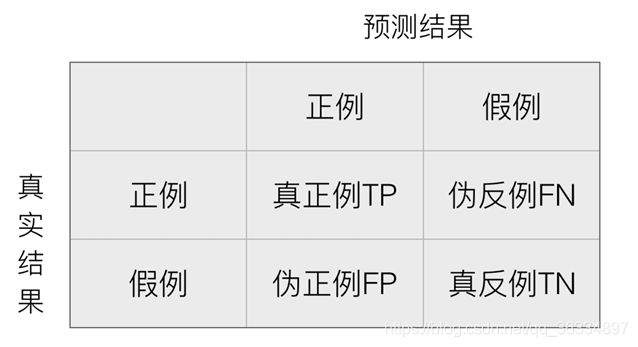
混淆矩阵:
-
准确率:estimator.score()
-
精确率:预测结果为正例样本中真实为正例的比例(查得准)-------> TP/(TP+FP)
-
召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)-----> TP/(TP+FN)
-
F1-score:

-
使用的API
导包: from sklearn.metrics import classification_report
实例化:cr = classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
target_names:目标类别名称—
return:每个类别精确率与召回率
六、 朴素贝叶斯算法
- 概率基础
条件概率:P(A1,A2|B) = P(A1|B)P(A2|B)
注:此条件概率的成立,是由于A1,A2相互独立的结果
贝叶斯公式:(│)=((│)()) / (()) - 文档分类问题
(│1,2,…)=((1,2,… │)()) / ((1,2,…))
简化为:(│1,2,…) = ((1,2,… │)())
根据联合概率公式: (│1,2,…) = (1|).(2|)…(n|).())
(1|): 给定类别下特征(被预测文档中出现的词)的概率
等于:该1词在C类别所有文档中出现的次数/类别C下的所有文档中所有特征词出现的次数和
():每个文档类别的概率(某类别总特征词数/所有类别总特征词数)
案列:文档分类

预测文档
科技:(影院,支付宝,云计算 │科技)∗P(科技)=8/100∗20/100∗63/100∗(100/221) =0.00456109
娱乐:(影院,支付宝,云计算│娱乐)∗P(娱乐)=56/121∗15/121∗0/121∗(121/221)=0
- 拉普拉斯平滑系数
作用:解决某个词频为0导致分类概率为0时的不合理问题
定义:(1│)=(+)/(+)
为指定的系数一般为1,m为训练文档中统计出的特征词个数 - 算法API
导包:from sklearn.naive_bayes import MultinomialNB
实例化:nb = MultinomialNB(alpha = 1.0)
默认平滑系数为1
适配过程: nb.fit(x_train,y_train)
估计过程:y_predict = nb.predict(x_test)
评估过程: nb.score(x_test,y_test) - 优缺点
优点:朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快
缺点:需要知道先验概率P(F1,F2,…|C),因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
def navi_bayes():
news = fetch_20newsgroups(subset='all')
print(next.head())
# 数据分隔
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 特征抽取
tf = TfidfVectorizer()
# 计算特征重要性(词频矩阵)
x_train = tf.fit_transform(x_train) # 返回sparse矩阵
x_test = tf.transform(x_test) # 不需要fit(测试集),不太合理,直接用fit(训练集)后的数据
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
if __name__ == '__main__':
navi_bayes()
七、模型选择与调优
- 交叉验证
作用:为了让被评估的模型更加准确可信
步骤:将拿到的数据,分为训练和验证集。以下图为例:将数据分
成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。通常选取10折交叉验证。

- 网格搜索
超参数:通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种参数叫超参数。
作用:超参数手动选取过程繁杂,选取需要实验的超参数取值。利用网格搜索和交叉验证。最后选出最优参数组合建立模型。
目的: 选取最优的超参数组合
使用的API
导包:from sklearn.model_selection import GridSearchCV
实例化:cv = GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
训练过程: cv.fit(x_train,y_train)
参数:
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
返回值:
best_score_:在交叉验证中测试的最好结果
best_estimator_:最好的参数模型
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
export_graphviz
import pandas as pd
def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# print(data.head(10))
# 处理数据
# 1、缩小数据,查询数据晒讯
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
print(time_value)
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# # fit, predict,score
# knn.fit(x_train, y_train)
#
# # 得出预测结果
# y_predict = knn.predict(x_test)
#
# print("预测的目标签到位置为:", y_predict)
#
# # 得出准确率
# print("预测的准确率:", knn.score(x_test, y_test))
# 构造一些参数的值进行搜索
param = {"n_neighbors": [3, 5, 10]}
# 进行网格搜索
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# 预测准确率
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)
return None
if __name__ == '__main__':
knncls()
八、决策树
- 信息论基础
信息熵:H = -(p1logp1 + p2logp2 + … + pnogn)
p1,p2…pn为每个特征所属的类别
作用:减少不确定性
信息增益:决策树的划分依据

- 使用的API
导包:from sklearn.tree import DecisionTreeClassifier
实例化: dec = DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
参数:
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
fit过程: dec.fit(x_train,y_train)
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
def dectree():
# 准备数据
data = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
x = data[["age","sex"]]
y = data["survived"]
# 缺失值处理(age中有缺失值)
x['age'].fillna(x['age'].mean(),inplace=True)
# 分隔数据
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
# 字典特征提取(sex,survived是字符串)
dv = DictVectorizer()
x_train = dv.fit_transform(x_train.to_dict(orient="records")) # 现将x_train转换为字典
x_test = dv.transform(x_test.to_dict(orient="records"))
# 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train,y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
- 优缺点及改进
优点:
简单的理解和解释,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化,
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。
改进:
减枝cart算法
随机森林
九、随机森林
- 集成学习
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。 - 随机森林定义
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。 - 学习算法
1.用N来表示训练样本的个数,M表示特征数目。
2.输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
3.从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。 - 随机抽样和有放回抽样的原因
随机抽样:
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
有放回抽样:
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。 - 使用的API
导包:from sklearn.ensemble import RandomForestClassifier
实例化: rf = RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)
参数:
n_estimators:integer,optional(default = 10) 选取的总决策树数量
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样 - 优点
在当前所有算法中,具有极好的准确率
能够有效地运行在大数据集上
能够处理具有高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性
对于缺省值问题也能够获得很好得结果
注:
通常选取的决策树数量和深度
[120, 200, 300, 500, 800, 1200], “max_depth”: [5, 8, 15, 25, 30]
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
def dectree():
# 准备数据
data = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
x = data[["pclass","age","sex"]]
y = data["survived"]
# 缺失值处理(age中有缺失值)
x['age'].fillna(x['age'].mean(),inplace=True)
# 分隔数据
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
# 字典特征提取(sex,survived是字符串)
dv = DictVectorizer(sparse=False)
x_train = dv.fit_transform(x_train.to_dict(orient="records")) # 现将x_train转换为字典
# print(dv.get_feature_names())
x_test = dv.transform(x_test.to_dict(orient="records"))
# 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train,y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
# 使用随机森林
params={"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
rf = RandomForestClassifier()
cv = GridSearchCV(rf,param_grid=params,cv=2)
# 网格搜索与交叉验证
cv.fit(x_train, y_train)
print("准确率:", cv.score(x_test, y_test))
print("查看选择的参数模型:",cv.best_params_)
if __name__ == '__main__':
dectree()