【深度学习模型】CNN的进击之路——讲讲ResNet, Inception, ResNeXt和Densenet等常见网络
文章目录
- 前言
- 1. AlexNet
- 2. VGG
- 3. GoogLeNet V1
- 4. GoogLeNet V2
- 5. GoogLeNet V3
- 6. ResNet
- 7. GoogLeNet V4
- 8. DenseNet
- 9. MobileNet
- 10. ResNeXt
- 11. Xception
- 12. ShuffleNet
- 13. 总结
前言
本文是一篇大杂烩,按照发布时间总结了CNN的一些常见网络。
1. AlexNet
AlexNet来源于ImageNet Classification with Deep Convolutional Neural Networks。在ImageNet LSVRC-2010上以远超第二的准确率夺得了冠军,拉开了深度学习热潮的大幕。
模型结构:
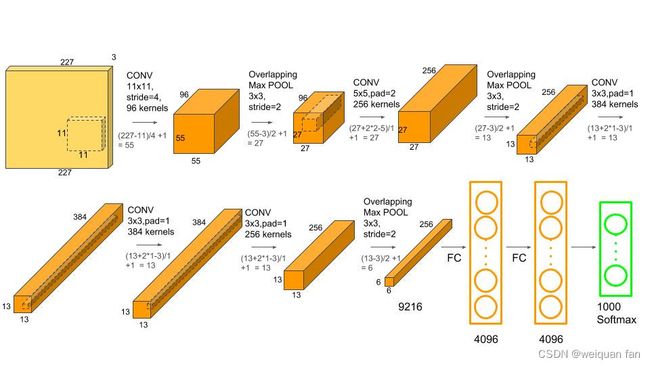
模型特点:
- 提出了非线性激活函数ReLU (之前普遍使用Sigmoid或者tanh)
- 提出Dropout(每次迭代训练时随机删除一些神经元)
- 重叠池化(池化的时候,每次移动的步长小于池化的窗口长度)
- 数据扩充(水平翻转图像,从原始图像中随机裁剪、平移变换,颜色、光照变换)
- LRN归一化层(利用临近的数据做归一化)
- 多GPU实现(受当时GPU限制,在每个GPU中放置一半神经元,将网络分布在两个GPU上进行并行计)
2. VGG
VGG来源于Oxford的Visual Geometry Group的组提出的Very Deep Convolutional Networks for Large-Scale Image Recognition,在ILSVRC 2014获得亚军。
模型结构:
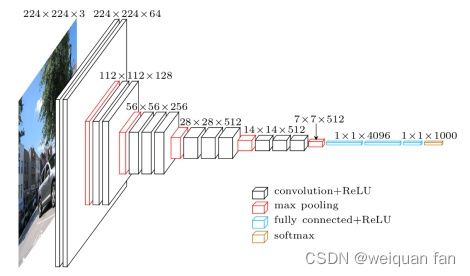

其中D、E列就是著名的VGG-16、VGG-19。
模型特点:
使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核。因此模型结构很统一简洁(卷积核尺寸3x3和最大池化尺寸2x2),并不断加深网络。
3. GoogLeNet V1
GoogLeNet V1来源于Going deeper with convolutions,在ILSVRC 2014获得冠军。
该网络的核心在于提出了Inception Module。该模块有4个分支,初始版本如下图左,包含三个不同尺度的卷积核层和一个最大池化层,并在输出通道维度上合并。由于5×5的计算量大,就进一步先通过1×1卷积降低维度再通过大卷积核。这里的最大池化也是重叠池化的,经padding后不会缩小特征图尺寸。
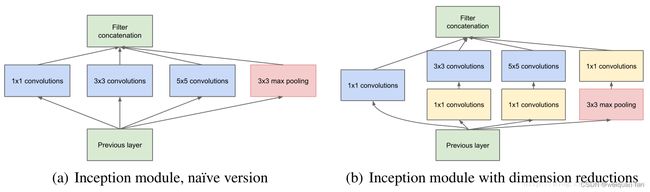
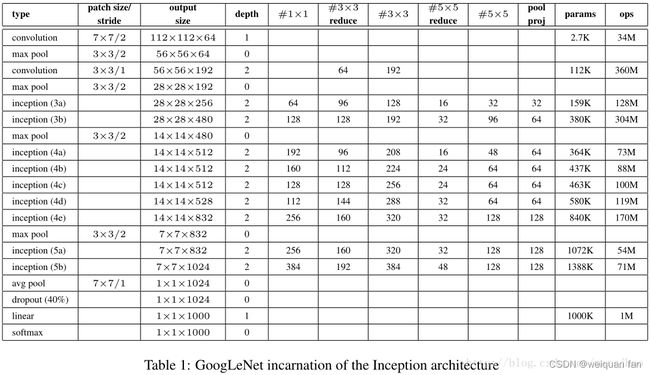
模型特点:
- 多尺度卷积的思想让网络变宽
- 提出1×1卷积
4. GoogLeNet V2
GoogLeNet V2来源于Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。该网络基于V1版本,吸收了VGG的分解操作,使用了2个3x3卷积核来代替5x5卷积核。
模型特点:
- 提出了著名的BN层。
- 另外,为了适配BN层,增大学习速率并加快学习衰减速度以适用BN规范化后的数据;去除Dropout并减轻L2正则(因BN已起到正则化的作用);去除LRN;更彻底地对训练样本进行shuffle;减少数据增强过程中对数据的光学畸变(因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助)。
5. GoogLeNet V3
GoogLeNet V3来源于Rethinking the Inception Architecture for Computer Vision。该网络基于V2版本,进一步改进了Inception,将3x3分解成1x3和3x1。同理,nxn可以分解成1xn和nx1。
6. ResNet
ResNet来源于大神何凯明的Deep Residual Learning for Image Recognition,在ILSVRC和COCO 2015上都夺得了冠军,有着里程碑的意义。
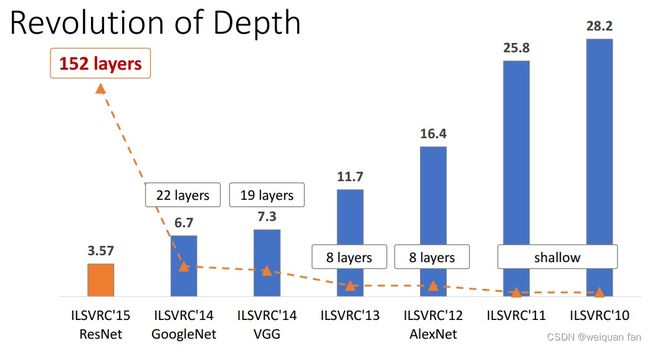
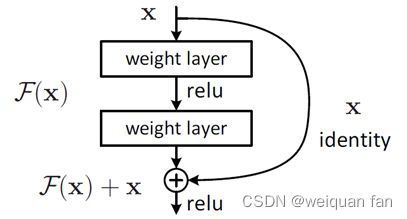
深度模型当深度到了几十层之后,由于梯度消失或者爆炸的原因,就容易发生退化问题:网络深度增加时,网络准确度出现饱和,甚至出现下降。现在假设我们有一个浅层网络,我们想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。这引发了残差学习,即我们的目标是学习到残差F(x)=H(x)-x,则该层学习到的最终特征H(x)=F(x)+x。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构下图所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
模型结构:
ResNet网络参考VGG19网络,引入残差单元。如下图,第三列即是ResNet-34。


模型特点:
- 提出残差模块
- 模型开始变得很深,可以达到152层
- 卷积层由Conv+BN+ReLU变成BN+ReLU+Conv
7. GoogLeNet V4
GoogLeNet V4来源于Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning。该论文一方面沿袭v3版本,使用更多的Inception module得到GoogLeNet V4。另一方面吸收了ResNet的残差单元,提出了两种Inception-ResNet。
模型结构:
下图为其中一种,Inception-ResNet-v1,具有如下特点:
- Inception module都是简化版,没有使用那么多的分支,因为identity部分(直接相连的线)本身包含丰富的特征信息;
- Inception module每个分支都没有使用pooling;
- 每个Inception module最后都使用了一个1x1的卷积(linear activation),作用是保证identity部分和Inception部分输出特征维度相同,这样才能保证两部分特征能够相加。
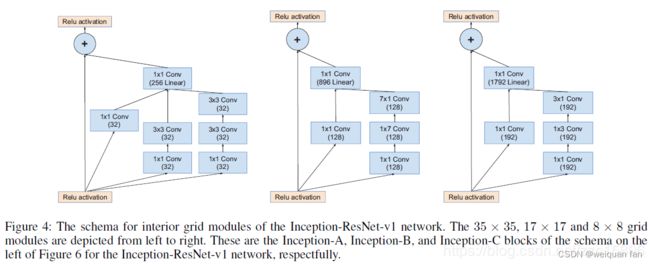
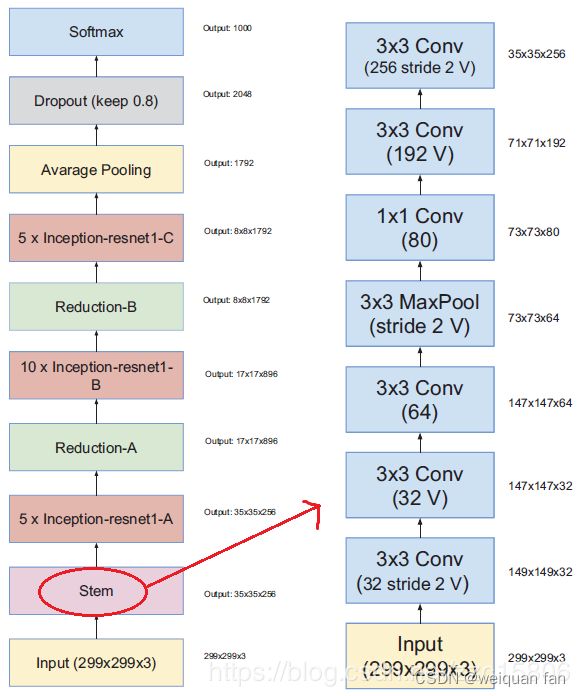
模型特点: - 使得宽模型变得更深
8. DenseNet
DenseNet来源于Densely Connected Convolutional Networks,斩获了CVPR 2017的最佳论文奖。
模型结构:
DenseNet有点类似于ResNet,但本质上又有很大的不同。结构上,把以前所有层的特征图都沿着通道轴拼接起来(而不是相加)。这可以理解为充分利用产生过的特征。
如下为ResNet:
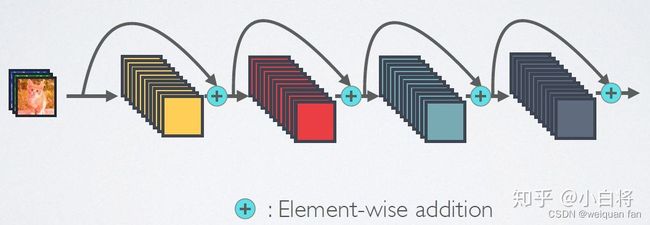
如下为DenseNet:
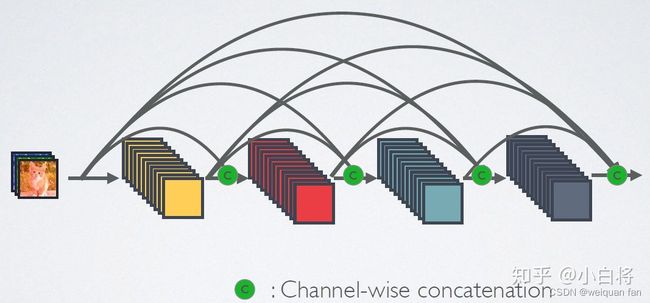
模型特点:
- 建立了不同层的连接关系,充分利用特征图
9. MobileNet
MobileNet来源于Google提出的MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,是一种小巧而高效的CNN模型。
模型结构:
MobileNet的核心在于提出了深度可分离卷积,它把传统卷积分解成了深度卷积(depthwise convolution)和逐点卷积(pointwise convolution),从而大量减少参数量。

对于输入特征图(DF,DF,M),输出特征图(DG,DG,N),传统卷积核的尺寸为(K,K,M,N),如下图(a)。
而对于深度可分离卷积,深度卷积的尺寸为(K,K,1,M),它将这M个卷积核各自应用于输入特征图的各个通道(这与传统卷积不同,这里相乘后不需要沿着通道轴相加),输出特征为(DG,DG,M),如(b)所示。逐点卷积的尺寸为(1,1,M,N),这个就是普通的1×1卷积了,输出特征为(DG,DG,N),如©所示。
可以看到,参数量从(K×K×M×N)变成(K×K×1×M + 1×1×M×N),减小了 M(KKN - KK -N)。
模型特点:
- 轻型模型,可用于移动端
10. ResNeXt
ResNeXt来源于Aggregated Residual Transformations for Deep Neural Networks。它是基于ResNet,吸收了GoogLeNet的Inception,所以和谷歌的Inception-ResNet很像。
模型结构:
如下图,左图是是ResNet,右图是新的ResNeXt。

该结构可以做如下等效,第三种就是等效的分组结构。
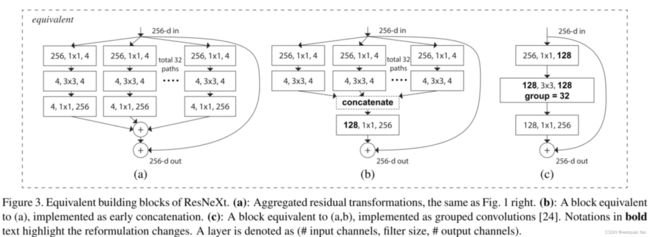
模型特点:
- ResNeXt的分支的拓扑结构是相同的,而Inception V4需要人工设计
- 提出了一种介于普通卷积核深度可分离卷积的这种策略:分组卷积
11. Xception
Xception来源于Xception: Deep Learning with Depthwise Separable Convolutions。它是Inception-V3的另一种改进,吸收了深度可分离卷积,造就了一种参数量相对少一些的网络结构。
模型结构:
Inception-V3可做如下简化,可以看到,如下图和深度可分离卷积是很像的,只是下图是先进行1×1的卷积,再进行channel-wise的spatial convolution,最后concat,而后者是先进行一个channel-wise的spatial convolution,然后是1×1的卷积。所以作者干脆把它换成深度可分离卷积。

最终整体结构如下,其中SeparalbeConv即是深度可分离卷积。
模型特点:
- 虽然使用了深度可分离卷积,但网络也加宽了,总体参数量和Inception-V3差不多,性能提升了。
- 提出时间和MobileNet相近,它们从不同的角度揭示了深度可分离卷积的强大作用,MobileNet的思路是通过将 3×3 卷积拆分的形式来减少参数数量,而Xception是通过对Inception的充分解耦来完成的。
12. ShuffleNet
Xception来源于ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices。这也是一款效率极高的轻型CNN模型,通过逐点群卷积(pointwise group convolution)和通道混洗(channel shuffle)大大降低计算量。
模型结构:
如下图左是普通的分组卷积,但是经过多层分组卷积后某个输出channel仅仅来自输入channel的一小部分,学出来的特征也很局限,因此作者提出了通道混洗channel shuffle,过程如下图中,在进行GConv2之前,对其输入feature map做一个分配,也就是每个group分成几个subgroup,然后将不同group的subgroup作为GConv2的一个group的输入,使得GConv2的每一个group都能卷积输入的所有group的feature map,结果图下图右。

pointwise group convolution,其实就是带group的卷积核为1×1的卷积。下图左是一个深度可分离卷积,而中间的图则是一个使用了pointwise group convolution的ShuffleNet unit,它将1×1卷积变成分组卷积,并在第一组分组卷积后加上通道混洗而成。右边的图则是带有降采样的ShuffleNet unit,它一方面在辅分支加入步长为2的3×3平均池化,一方面将最后的相加变成了通道级联。

模型特征:
- 用了1×1的通道卷积
- 提出了通道混洗
13. 总结
其实总的来说,创新性的应该包含了inception,残差学习,深度可分离卷积,分组卷积几种。inception有GoogLeNet V1-V4、Xception、ResNeXt。残差学习有ResNet、ResNeXt、DenseNet、GoogLeNet V4。深度可分离卷积有MobileNet、ShuffleNet、Xception。分组卷积有ResNeXt、ShuffleNet。