【学习周报9.26 ~ 10.1】Hierarchical Modular Network for Video Captioning(CVPR2022)
学习内容:
- 论文:Hierarchical Modular Network for Video Captioning(CVPR2022)
- 论文:End-to-End Object Detection with Transformers(ECCV2020)
- WordNet
- tanh函数
- Inception-ResNet v2
学习时间:
- 9.26 ~ 10.1
学习笔记:
在论文[Hierarchical Modular Network for Video Captioning(CVPR2022)]中,作者使用了WordNet获得“同义词标签”,在获取图像的context features时使用Inception-ResNet v2,获取motion features时使用C3D,激活函数使用了tanh,下面针对这些比较陌生的知识做简单的了解介绍。
WordNet
1.什么是WordNet
WordNet是一个在20世纪80年代由Princeton大学的著名认知心理学家George Miller团队构建的一个大型的英文词汇数据库。名词、动词、形容词和副词以 同义词集合(synsets) 的形式存储在这个数据库中。每一个synset代表了一个同义词集合,各个synsets之间通过语义关系和词性关系等边连接。
它作为语言学本体库,同时又是一部语义词典,在自然语言处理研究方面应用非常广泛。
2.WordNet的结构
WordNet中单词之间的主要关系是同义词关系,比如shut和close是同义词,car和automobile是同义词。这些同义词(表示相同概念并且在许多情况下可以互换的单词)被分组为无序的同义词集合(synsets)。wordnet中一共有11.7万个这样的同义词集合。
每一个synset都通过conceptual relation(见第三部分和第四部分所述)与其他的synsets相连接。另外,每一个synset中都包含简短的定义和一些使用样例,说明该synset表示的概念和用法。

3.词汇关系
3.1 上位词和下位词关系
synsets之间最常见的关系是上位词和下位词关系(hypernym vs hyponymy)。
- 上位词关系表示一个词的词义比另一个词的词义更加泛化,e.g. fruit是apple的上位词。
- 下位词关系表示一个词的词义比另一个词的词义更加具体,e.g. apple是fruit的下位词。
这种关系是具有传递性的。比如苹果是一种水果,水果是一种食物,那么苹果就是一种食物。
3.2 整体-部分关系
一个词是另一个词的一部分,这就是整体部分关系。比如靠背是椅子的一部分、桌脚是桌子的一部分等等。
- 部分关系可以从上位词继承,比如桌子是有桌脚的,那么餐桌也会有桌脚。
- 部分关系是不能向上传递的,比如椅子有靠背,并不代表所有家具都有靠背。
3.3 动词关系
动词的synsets集合也有类似上述的层次结构。在这种层级结构中,越靠近叶节点的动词表示动作越来越具体,比如communicate->talk->whisper(音量越来越具体),move->jog->run(速度越来越具体),like->love->idolize(情感越来越具体)。
另外,某些动作与完成这些动作时所必经的一些动作之间也有单向边连接。比如buy->pay,succeed->try,show->see。
3.4 形容词关系
形容词synsets之间的关系是根据反义词关系来组织的。比如dry和wet,old和young。这些反义词关系表示了synsets之间的强语义约束性。而每一个反义词关系两边的形容词synset又与很多语义相似的形容词相连,比如dry和parched、arid、dessicated等相连,wet和soggy、waterlogged等相连。
3.5 副词关系
WordNet中仅有少量的副词synsets,比如hardly、mostly、really等。
4、跨词性关系
WordNet的大多数关系都只将来自同一词性(Part Of Speech)的词联系起来。因此,wordnet实际上由四个子图组成,分别是名词、动词、形容词和副词。跨词性的synsets关系很少,大部分都是词法关系,比如observe (动词)、 observant (形容词) 、observation (名词)。还有一些关系表示名词是动词代表动作的某个语义角色,比如sleeping car是sleep的LOCATION,painter是paint的AGENT等等。
5.示例
官网链接:WordNet
在导航栏选择:Use Wordnet Online
tanh函数
也称为双切正切函数,取值范围为[-1,1]。
公式
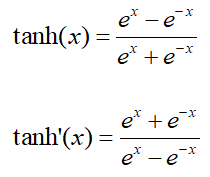
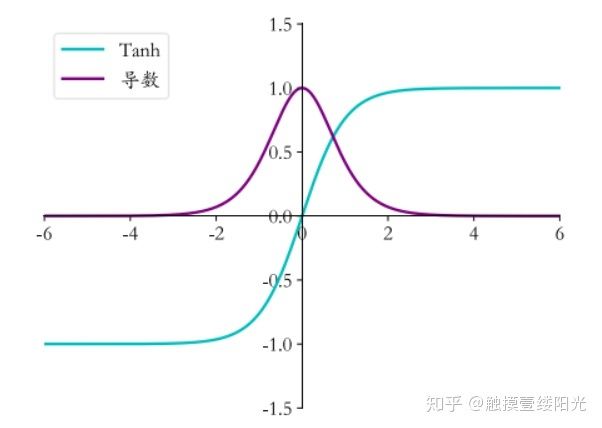
曲线
为什么要使用tanh
- 首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好
- 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
Inception-ResNet v2
1.Inception网络
在Inception V1网络诞生之前,网络大都是这样子的:

也就是卷积层和池化层的顺序连接。这样的话,要想提高精度,增加网络深度和宽度是一个有效途径,但也面临着参数量过多、过拟合等问题。
为了能够在同一层提取不同的图像特征,GoogleNet提出了卷积核的并行合并(Bottleneck Layer) :

按照这样的结构来增加网络的深度,虽然可以提升性能,但是还面临计算量大(参数多)的问题。
于是GooLeNet借鉴Network-in-Network的思想,使用1x1的卷积核实现降维操作(也间接增加了网络的深度),以此来减小网络的参数量,如图所示。

最后实现的inception v1网络就是将上图结构的顺序连接,其中不同inception模块之间使用2x2的最大池化进行下采样。之后inception网络经过优化陆续诞生了v2、v3、v4版本,详情请参考链接:卷积神经网络结构简述(二)Inception系列网络
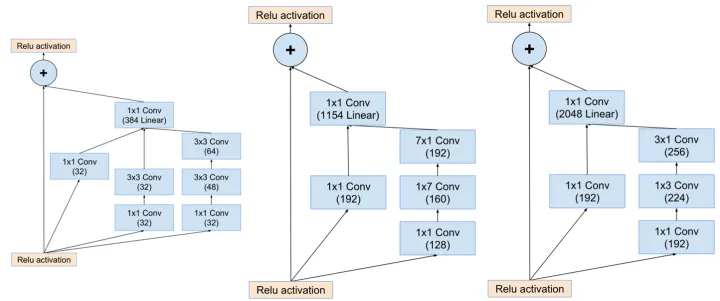
2.Inception-ResNet-v2
ResNet(残差网络) 的结构既可以加速训练,还可以提升网络性能;Inception模块可以在同一层上获得稀疏或非稀疏的特征。Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络,该网络的核心在于inception-resnet模块: