【AI工程论文解读】04-通过Ease.ML/CI实现机器学习模型的持续集成(上)

作者:王磊
更多精彩分享,欢迎访问和关注:https://www.zhihu.com/people/wldandan
持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。许多团队发现这个过程可以大大减少集成的问题,让团队能够更快的开发内聚的软件。
在上一篇《【AI工程论文解读】03-DevOps for AI-人工智能应用开发面临的挑战》文中,我们介绍了DevOps和ML工作流结合的解决方案和实践。本篇论文《Continuous Integration Of Machine Learning Models With Ease.ML/CI: Towards A Rigorous Yet Practical Treatment》,将分享一个用于机器学习的持续集成系统ease.ml/ci。
在现代软件工程实践中,持续集成是系统地管理软件系统开发生命周期不可或缺的部分。机器学习模型的开发生命周期同样包括设计、实现、调优、测试和部署。然而,大多数现有的持续集成引擎并不能友好的支持机器学习模型的开发。
在本文中,作者们介绍了用于机器学习的持续集成系统ease.ml/ci,一种用于该领域的特定声明性脚本语言,允许用户指定具有可靠性约束的测试条件,可以将实际生产系统中普遍使用的测试条件所需的标记数量降低两个数量级。
概述
在现代软件工程中,持续集成(CI)是系统地管理开发工作生命周期的最佳实践的重要组成部分。使用CI引擎时,要求开发人员每天至少一次将其代码集成(即提交)到共享存储库中。每次提交都会触发代码的自动构建,然后运行预定义的测试套件。开发人员每次提交后会接收到一个通过/失败信息,保证每次提交都满足产品部署所需的属性,或者下游软件假定的必要属性。
开发机器学习模型与开发传统软件流程大体一致,因为它也是一个涉及设计、实现、调优、测试和部署的完整生命周期。随着机器学习模型更多用于以任务型为主的应用程序中,并且与传统软件栈更加紧密地集成,因此,通过系统的、严格的工程规则来管理ML开发生命周期变得越来越重要。
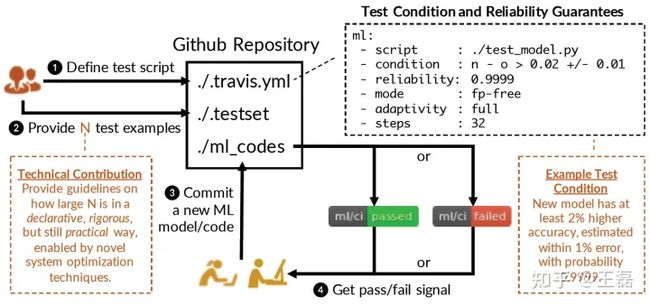
图1 ease.ml/ci工作流

作者们从系统和机器学习的角度做出了贡献。
- 系统贡献:作者们提出了一种新的系统架构,以支持ML系统。
- 机器学习贡献:在机器学习方面,作者们开发了简单的优化技术,以优化可以在特定领域语言中表达的测试条件。作者们的技术涵盖了不同的交互模式(完全自适应、非自适应和混合场景),以及许多工业和学术合作伙伴认为有用的流行测试条件。对于测试条件的子集,能够在系统所需的标记数量上节省多达两个数量级。
在本文的后续部分,分别介绍了ease.ml/ci的设计、基本实现、更高级的优化、实验(验证技术的正确性和有效性)和其他相关工作等。
系统设计
本节介绍了ease.ml/ci的设计。首先介绍了交互模型和工作流程,如图1所示。然后,介绍了支持用户交互的脚本语言。并讨论了单个元素的语法和语义,以及它们的实现和可能的扩展。最终得到了两个系统实用程序,一个“样本量估计器”和一个“新测试集警报器”,其技术细节将会在后续文中介绍。
交互模型
ease.ml/ci是一个用于机器学习的持续集成系统。它的工作流包含四步:
(1)用户在测试配置脚本中描述与ML模型质量相关的测试条件;
(2)用户提供N个测试用例,其中N由系统根据给定的配置脚本自动计算得出;
(3)每当开发人员提交/检入更新的ML模型/程序时,系统会触发构建;
(4)系统测试是否满足测试条件,并向开发人员返回“通过/失败”信息。如果当前测试集由于重复评估而失去其“统计能力”时,系统会决定何时向用户请求新的测试集。旧的测试集可以作为用于开发新模型的验证集发布给开发人员。
为此,特意定义了两个团队:集成团队,负责提供测试集并设置可靠性需求;开发团队,负责提交新模型。在实践中,这两个团队可以是相同的,但是在本文中,将会区分这两个团队,尤其是在完全适应的情况下,会将集成团队描述为用户,将开发团队描述为开发人员。
ease.ml/ci脚本
ease.ml/ci为用户提供了一种声明性的方法,可以根据一组测试用例指定新机器学习模型的需求。然后,ease.ml/ci将这些规范编译成一个实用的工作流,使得测试用例的评估具有严格的理论保障。本文给出了ease.ml/ci脚本语言的设计,其通过Travis CI使用可扩展.travis.yml格式进行实现。
逻辑数据模型

关于语法及其语义的详见附录A。
自适应与非自适应集成
ease.ml/ci与传统持续集成系统的一个显著区别是,当新模型是否通过持续集成测试的结果发布给开发人员时,测试数据集的统计能力将下降。如果开发人员愿意,可以调整下一个模型,以增加其通过测试的概率。由于需要更大的测试集,确保完全自适应情况下的通过概率将会成本更高。ease.ml/ci允许用户通过参数(full、none、firstChange)指定测试是否采用自适应:
- 如果参数设置为full,ease.ml/ci会立即向开发人员发布新模型是否通过测试。
- 如果参数设置为none,ease.ml/ci会接受所有提交,但会将模型是否真正通过测试的信息发送到用户指定的第三方电子邮件地址,开发人员可能无法访问该邮件。
- 如果参数设置为firstChange,则在测试第一次通过(或失败)之前,ease.ml/ci允许完全自适应,但在测试之后会停止,并需要新的测试集。
示例脚本
ease.ml/ci脚本通过在Travis CI中添加ml部分,采用可扩展的.travis.yml文件设计来实现的。例如:
ml:
- script : ./test_model.py
- condition : n - o > 0.02 +/- 0.01
- reliability: 0.9999
- mode : fp-free
- adaptivity : full
- steps : 32此脚本指定了一个连续测试过程,如上所示,该过程的有效测试概率大于 0.9999 ,且仅在新模型的精度比旧模型高两点时,才会接受新的提交。该估计是以“false-positive free”的方式进行,误差预计在一个精度点内。关于“mode”,在附录A.2中给出了fp-free和fn-free两种模式的详细定义和简单示例。脚本中的适应性采用“full”模式,即系统会立即向开发人员反馈通过/失败信息。在用户向系统提供新的测试集之前,给定的测试集可以被使用多达32次。
类似地,如果用户希望指定非自适应集成过程,她可以提供以下脚本:
ml:
- script : ./test_model.py
- condition : d < 0.1 +/- 0.01
- reliability: 0.9999
- mode : fp-free
- adaptivity : none -> [email protected]
- steps : 32该脚本会接受每个提交,但在每次提交后,会将测试结果发送到电子邮件地址[email protected]。假设开发人员没有此电子邮件帐户的访问权限,会造成无法优化其下一个模型。
讨论和扩展
当前的语法,即ease.ml/ci能够捕获用户在开发过程中发现的许多有用的用例,包括推理新模型和旧模型之间的精度差异,以及推理测试数据集中新模型和旧模型之间预测变化量。原则上,ease.ml/ci可以支持更丰富的语法,如下列出了当前语法的一些限制,未来可继续研究。
- 准确性之外:当前系统不支持机器学习的其它重要质量指标,例如F1-score和AUC score等。通过用McDiarmid 's不等式替换Bennett 's不等式,以及F1-score和AUC score的敏感性,可以扩展当前系统以适应这些分数。在这种新的背景下,通过更多的优化,如使用分层样本。
- 比率统计:ease.ml/ci的当前语法故意省略了除法(“/”),这对于将来的版本能够进行质量的相对比较(例如,准确度、F1-score等)非常有用。
- 顺序统计:一些用户认为顺序统计也很有用,例如,确保新模型在历史模型中位于前5位。
另外,当前系统还受限于无法检测概念漂移(domain drift or concept ship)。理论上,这一过程类似于CI,区别于固定测试集、测试多个模型,检测概念漂移仅测试单个模型,并监测其在多个测试集上的泛化。
当前版本的ease.ml/ci不支持上述功能。然而,其中许多功能可以通过开发类似的统计技术来支持。
系统程序
在传统的持续集成中,系统通常假定用户拥有自己构建测试套件的知识和能力。实际上,通过观察发现,即使大型科技公司经验丰富的软件工程师也可能不知道如何针对给定的可靠性需求开发适当的测试集,尤其对于ease.ml/ci来说,要求会更高。ease.ml/ci一个突出贡献其是一个技术集合,为用户管理测试集提供了实用但严格的指导:测试集需要多大?系统何时需要生成新的测试集?系统什么时候可以发布测试集并将其“降级”为开发集?虽然其中大多数问题都可以由专家根据经验和直觉回答,但ease.ml/ci的目标是提供系统、原则性的指导。为了实现这一目标,ease.ml/ci提供了两个在Travis CI等系统中没有提供的实用程序。
样本容量估计器:该程序以ease.ml/ci脚本作为输入,输出用户需要在测试集中提供的示例数量。
新测试集告警:该程序以ease.ml/ci脚本和机器学习模型的提交历史记录作为输入,并在当前测试集被多次使用而无法用于测试下一个提交的模型时,向用户生成告警(例如,通过发送电子邮件)。用户收到告警后,需要向系统提供新的测试集,也可以将旧的测试集发布给开发人员。
这两个应用程序有一个不太符合实际生产,即系统在每次提交后都会提醒用户请求新的测试集,并使用Hoeffding边界预估测试集大小,但这也会导致需要大量的标记工作。
什么是“实用”?实用性当然取决于用户。尽管如此,从与不同用户的合作经验观察到,为每32个模型评估提供30000 ~ 60000个标记对许多用户来说似乎是合理的。30000 ~ 60000是2到4名工程师在一天(8小时)内以2秒/每个标记的速度进行标记的工作量,32个模型评估意味着(平均)一个月内每天提交一次。在此假设下,用户每个月只需要花一天时间用合理数量的标记器提供测试标记。如果用户无法提供此数量的标记,则在大多数常见条件下,通过将容错率提高一个或两个百分点,可以实现“廉价模式”,即每天标记数量轻松减少10倍。
因此,为了使ease.ml/ci成为实用的工具,这些实用程序需要以更实用的方式实现。ease.ml/ci的技术贡献后续将会介绍,它可以将系统从用户请求的样本数减少两个数量级。
基本实现
单模型样本量估计器
单个变量的估计器


非自适应场景
在非自适应场景中,系统评估H模型后,不会将结果发布给开发人员,结果可以发布给用户(集成团队)。
样本量估计

新测试集告警
在非自适应场景中,用户提供新测试集的告警很容易实现。系统维护一个计数器,以显示测试集已被使用的次数。当该计数器达到预定义值(即steps)时,系统向用户请求新的测试集。同时,旧的测试集可以发布给开发人员。
完全自适应场景
在完全自适应场景下,系统将测试结果(一个bit表示通过/失败)发布给开发人员。由于会将bit信息从测试集泄露给开发人员,因此不能像非自适应场景中那样使用联合绑定。

样本量估计

新测试集告警
与非自适应场景类似,请求新测试集的告警很容易实现,当系统达到预定义值(即steps)时,系统会请求新测试集。同时,旧的测试集可以发布给开发人员。
混合场景
通过约束发布给开发人员的信息,可以获得所需样本数量的更好边界。考虑以下场景:
- 如果提交失败,则向开发人员返回失败;
- 如果提交通过,则(1)返回通过给开发人员;(2)触发新的测试集告警,向用户请求新的测试集。
与完全自适应场景相比,在该场景中,在开发人员提交通过测试的模型之后,用户立即提供一个新的测试集。
样本量估计
假设H为系统支持的最大steps。因为在模型通过测试后,系统将立即请求一个新的测试集,所以它并不是真正的自适应:只要开发人员继续使用相同的测试集,就可以假设最后一个模型总是失败。假设用户是一个确定性函数,它根据过去的历史记录和过去的反馈(一个Fail流)返回一个新模型,则只有H个可能状态需要使用union bound。这提供了与非自适应场景相同的界限:n(F,ϵ,δH)。
新测试集告警
与前两个场景不同的是,每当用户提供的模型通过测试或达到预定义值H时,系统就会向用户发出告警。
讨论
混合场景(将信息泄露给开发人员)具有与非自适应情况相同的样本量估计,可能与预期相反。考虑到测试集支持的最大值H,由于可能在循环测试中使用新的测试集,混合场景不能总是完成所有H次数。换句话说,与自适应场景相反,混合场景不是通过增加更多的样本,而是通过减少测试集可以支持的steps来考虑信息泄漏。
当测试难以通过或失败时,混合场景非常有用。例如,想象以下情况:
F:−n−o>0.1+ / − 0.01
也就是说,系统只接受将精确度提高10个精确度点的提交。在这种情况下,开发人员可能需要进行多次开发迭代来获得一个满足条件的模型。
条件评估

用例与实用性分析
ease.ml/ci实现简单,支持许多实用的场景。总结如下五个用例,并分析了用户所需的样本数。
(F1:下限最差情况质量)
F1 :- n > [c] +/- [epsilon]
adaptivity :- none
mode :- fn-free此条件用于质量控制,以避免开发人员提交的低质量或者明显错误的模型。在非自适应场景中可以看到许多这种情况的用例,其中大多数需要无false-negative。
(F2:增量式质量改进)
F2 :- n - o > [c] +/- [epsilon]
adaptivity :- full
mode :- fp-free
([c] is small)此条件用于确保机器学习应用程序随着时间的变化持续的改进。当机器学习应用程序面向最终用户时,质量下降是不可接受的。在这种情况下,整个过程完全自适应和无误报将很重要。
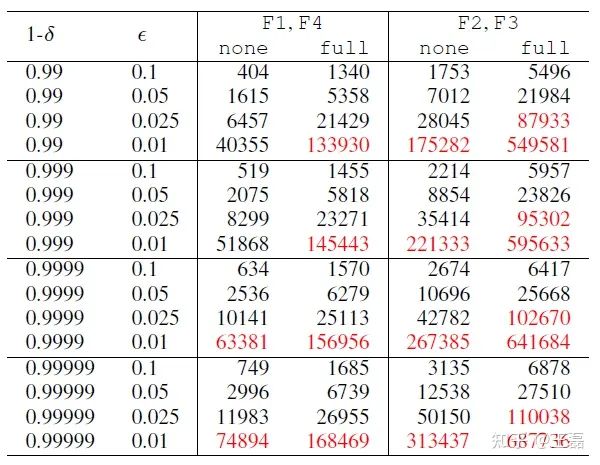
图2不同条件所需的样品数, H=32 红色字体表示“不切实际”的样本数量
(F3:质量里程碑)
F3 :- n - o > [c] +/- [epsilon]
adaptivity :- firstChange
mode :- fp-free
([c] is large)此条件用于确保存储库仅包含重要的质量里程碑(例如,发生10个精度点跳跃后的日志模型)。虽然条件在语法上与F2相同,但整个过程是混合自适应的,无false-positive。
(F4:无重大变更)
F4 :- d < [c] +/- [epsilon]
Adaptivity :- full | none
Mode :- fn-free
([c] is large)此条件用于类似于F1的安全问题。当机器学习应用程序面向最终用户或作为较大应用程序的一部分时,需要确保在后续版本不会发生显著变化。该过程需要是无false-negative。
(F5:构成条件)
![]()
最流行的测试条件之一是F4和F2两个条件的组合:集成团队希望将F4和F2一起使用,这样面向最终用户的应用程序就不会经历巨大的质量变化。
实用性分析
我们的实现支持的哪些条件时实用的?哪些是不切实际的?
何时实用?
在大多数情况下,支持的条件大多是实用的。图2中显示了H = 32时所需的样本数。我们发现,对于F1和F4,所有自适应策略在2.5个精度点内是实用的;而对于F2和F3,非自适应和混合自适应策略在2.5个精度点内是实用的,完全自适应策略只有在5个精度点内才是实用的。从这个例子中我们可以看到,即使是一个简单的实现,对严格保证机器学习的CI执行代价也并不总是昂贵的。
何时是不切实际的?
从图2中可以看到对ϵ的强依赖性。由于Hoeffding不等式中的 O(1/ϵ2) 项,该结果符合预期。因此,在1个精度点之上,没有一种自适应策略是实用的,这对于机器学习的许多关键任务应用程序来说是很重要的。完全自适应策略比非自适应策略需要更多的样本,因此会在更高的容错性下变得不切实际。
参考资料
- Cedric Renggli, Bojan Karlaš, Bolin Ding, Feng Liu,Wentao Wu, Ce Zhang, Continuous Integration of Machine Learning Models with ease.ml/ci: Towards a Rigorous Yet Practical Treatment SysML Conference (SysML 2019)