编码 GBK 的不可映射字符 (0x80),sublime设置中文,sublime没有GBK编码选项的问题详解
文章目录
- 1.问题描述
- 2.问题分析
- 3.问题解决
-
- 3.1 sublime Text 3引入
-
- 3.1.1 介绍
- 3.1.2 特点
- 3.1.3 下载与安装
-
- 3.1.3.1 :house: 下载官网: http://www.sublimetext.com/3
- 3.1.3.2 找到下载的安装包位置,双击,建议修改一下安装路径,不要放在C盘。
- 3.1.3.3 选择是否添加到资源管理器上下文菜单
- 3.1.3.4 核实信息,准备安装
- 3.2 sublime设置为中文
-
- 3.2.1 Preferences -> Package Control
- 3.2.2 输入 install package
- 3.2.3 输入 Chinese ,选择 ChineseLocalizations
- 3.2.4 安装成功
- 3.3 :triangular_flag_on_post: 安装GBK选项插件 - ConvertToUTF8
-
- 3.3.1 下载ConvertToUTF8包
- 3.3.2 将解压后的`ConvertToUTF8文件夹`迁移到sublime的`Packages`目录下
- 3.3.3 比较一下ConvertToUTF8插件安装前后sublime的变化
- 3.3.4 一个小 bug 的解决
- 3.4 :triangular_flag_on_post: 创建文件,设置编码格式,编写完成后 另存为
-
- 3.4.1 创建新文件
- 3.4.2 如果代码中含有中文,设置文件编码为GBK
- 3.4.3 编写代码
- 3.4.3 文件 -> 另存为
- 3.5 验证 javac 可行性
- 3.6 一个小 bug 的补充
- 4.补充:对于为什么cmd,或者说windows采用GBK而非UTF8的理解
1.问题描述
在执行 javac 命令时无法编译成功,提示 错误: 编码 GBK 的不可映射字符 (0x80)

2.问题分析
先简单的说:就是你的代码中带了中文,即使时注释里有中文也算含有。现在,我们的目的就是为了 解决能够带有中文成功编译 的问题。
这是因为我们的文件编码格式是 UTF8,而当我们使用 cmd命令行窗口 时,cmd 的编码格式为 GBK。
由于编码的不同,导致 cmd 会以 GBK编码格式 去解析我们的文件,但是刚才说了,我们文件的编码格式是 UTF8,因此解析中文不成功,才报错。
但解析英文是成功的,因为英文最早来源于 ASCII 编码,而GBK和UTF8这两种编码都是完全兼容ASCII 编码的。
为了验证我说的cmd编码格式为GBK,我们来看一看
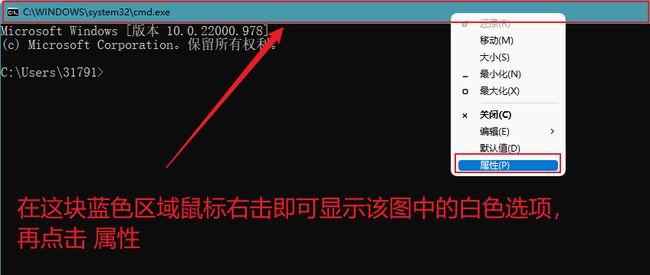

3.问题解决
如果你已经有了sublime但没有设置中文,从 3.2节 看起;
如果你有了sublime并且设置了中文,从 3.3节 看起。
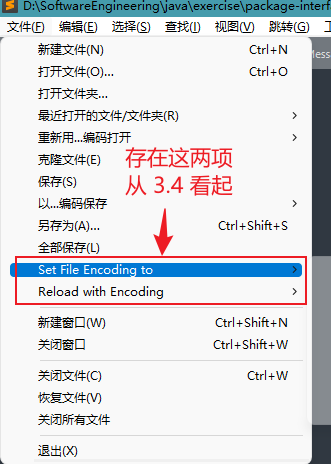
如果你的文件选项(点击
左上角文件即可弹出)中有如下显示的红色框中的两个选项并设置了中文,就跳过 3.3节 ,从 3.4节 看起。
3.1 sublime Text 3引入
你还在使用记事本编译 java 吗?其实是非常不推荐的。
这里我们推荐一款轻量级的Java编辑工具:sublime Text 3
3.1.1 介绍
一款具有代码高亮、语法提示、自动完成且反应快速的编辑器软件,不仅具有华丽的界面,还支持插件扩展机制,用她来写代码,绝对是一种享受。相比于难于上手的Vim,浮肿沉重的Eclipse,VS,即便体积轻巧迅速启动的Editplus、Notepad++,在SublimeText面前大略显失色,无疑这款性感无比的编辑器是Coding和Writing最佳的选择,没有之一。
3.1.2 特点
一款跨平台代码编辑器,在Linux、OS X和Windows下均可使用。Sublime Text 是可扩展的,并包含大量实用插件,我们可以通过安装自己领域的插件来成倍提高工作效率。Sublime Text 分别是命令行环境和图形界面环境下的最佳选择,同时使用两者会大大提高工作效率。Sublime Text 为收费软件,建议有能力的人付费使用,以支持开发者。不过不购买也可以一直使用。
3.1.3 下载与安装
3.1.3.1 下载官网: http://www.sublimetext.com/3

3.1.3.2 找到下载的安装包位置,双击,建议修改一下安装路径,不要放在C盘。
3.1.3.3 选择是否添加到资源管理器上下文菜单

3.1.3.4 核实信息,准备安装
3.2 sublime设置为中文
3.2.1 Preferences -> Package Control

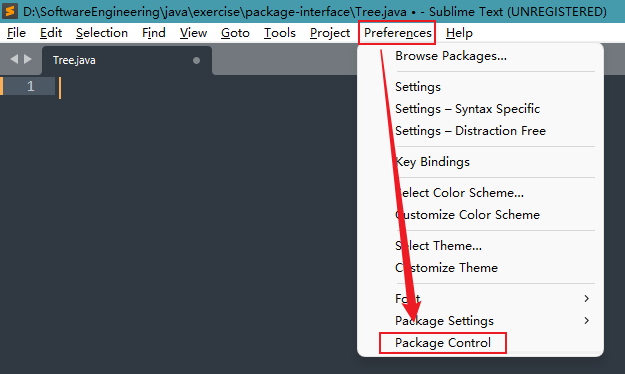
3.2.2 输入 install package

回车后可能需要等待一会因为需要加载包,才会出现下面步骤中的面板,耐心等一会哦
3.2.3 输入 Chinese ,选择 ChineseLocalizations

3.2.4 安装成功
显示这样的界面,可以看到已经变成中文了

3.3 安装GBK选项插件 - ConvertToUTF8
默认情况下,我们的 Sublime Text 3 是没有 GBK编码格式设置了,为了是我们的文件设置为 GBK,应当安装 GBK选项插件。
3.3.1 下载ConvertToUTF8包
下载地址:https://github.com/seanliang/ConvertToUTF8/releases/tag/1.2.13

3.3.2 将解压后的ConvertToUTF8文件夹迁移到sublime的Packages目录下
进入 Packages 目录:


拷贝到Package目录下后选要重启sublime才能看到效果。

3.3.3 比较一下ConvertToUTF8插件安装前后sublime的变化
-
安装前:

-
安装后:

3.3.4 一个小 bug 的解决
你可以发现,我们出现了两次(如果你没有出现,可能需要等一下就会出现,如果你没出现就直接跳过 3.4 节),这是为什么呢?

其实不解决也没问题,但我又强迫症哈。我们再打开 Packages 目录看下:

因此要解决这个其实很简单了,我们直接删除 ConvertToUTF8-1.2.13 ,留下自动生成的 ConvertToUTF8 即可,删除后的效果:

我们再来看看sublime的文件选项,就没有显示两次啦:

3.4 创建文件,设置编码格式,编写完成后 另存为
3.4.1 创建新文件

3.4.2 如果代码中含有中文,设置文件编码为GBK
如果代码中不带中文,则不需要进行这一步,直接创建完新文件编写代码即可。

3.4.3 编写代码
//带了中文的代码
public class Tree
{
public static void main(String[] args){
Living tree=new Living ();
tree.say();
}
}
class Living
{
public void say(){
System.out.println("我是一棵树");
}
}
3.4.3 文件 -> 另存为


3.5 验证 javac 可行性
在我们刚才 保存Tree.java文件 的目录下打开cmd控制台,执行 javac Tree.java。生成了两个 .class 文件则说明执行成功。

3.6 一个小 bug 的补充
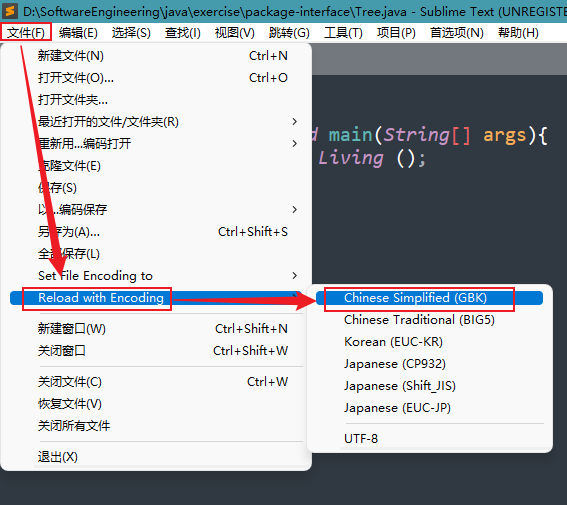
如果你下次打开 Tree.java 时发现里面的中文变成了乱码,只需要执行 文件选项 中的 Reload with Encoding 即可。
为什么会出现这种情况呢?因为你在打开文件的时候,计算机可能是以 UTF8 的格式给你解码文件的,而我们的Tree.java文件是以 GBK 方式编码。因此计算机在以 UTF8格式 解码时无法解析文件中的 GBK编码格式的中文,导致UTF8格式解析成了乱码。
所以解决这个也很简单,执行
Reload with Encoding 的 GBK选项 即以GBK方式重新解码。
4.补充:对于为什么cmd,或者说windows采用GBK而非UTF8的理解
-
一方面是由于历史原因,Windows支持GBK的时候UTF-8还没有普及,而微软是一家及其看重存量客户和兼容性的公司,形成了路径依赖不能轻易改变。
UTF-8只是在存储欧洲语言文字方面有优势。由于兼容ASCII,UTF-8存储拉丁字母、数字、半角标点等字符使用1个字节,存储其他非拉丁字母的欧洲文字通常使用2个字节,但存储东亚文字,如汉字、日本假名、韩国谚文等,则使用3个字节,少数不常见的字符则用4个字节。而UTF-16对大多数常见语言文字统一使用2个字节,少数字符使用4个字节。
因此,UTF-8在东亚地区并非最佳存储和传输方案,它的真正优势在于实现Unicode的同时兼容ASCII编码。
-
另一方面,
GBK编码的特点是 英文占1个字节,中文占两个字节。而UTF8编码的特点是 中英文统一占三个字节。而我们知道在计算机存储方面几乎绝大部分都是英文,因此存储上GBK的优势就很明显,相较于 UTF8 能够大大的节省空间。