阅读笔记:python 编程从入门到实践
操作列表
range()轻松生成一系列数。
for value in range(1,5):
print(value)#打印1-4输出:
1
2
3
4
调用函数range()时,只指定一个参数,就从0开始。还可以指定步长。
range(2,11,2),步长为2,则输出:[2,4,6,8,10]
两个星号(**)表示乘方运算,
squares=[]
for value in range(1,11):
square=value**2
squares.append(square)#不可以squares=squares.append(square)
print(squares)
print('最终')
print(squares)输出:
[1]
[1, 4]
[1, 4, 9]
[1, 4, 9, 16]
[1, 4, 9, 16, 25]
[1, 4, 9, 16, 25, 36]
[1, 4, 9, 16, 25, 36, 49]
[1, 4, 9, 16, 25, 36, 49, 64]
[1, 4, 9, 16, 25, 36, 49, 64, 81]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
最终
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]>>>digits=[1,2,3,4,5]
>>>min(digits)
1
>>>max(digits)
5
>>>sum(digits)
15列表解析
squares=[value**2 for value in range(1,11)]
print(squares)
#代替以下代码:
squares=[]
for value in range(1,11):
square=value**2
squares.append(square)
print(squares)输出
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
切片
a=['1','2','3','4','5']
print(a[1:4])
print(a[:4])
print(a[0:4:2])
print(a[-3:])
print(a[:])输出:
['2', '3', '4']
['1', '2', '3', '4']
['1', '3']
['3', '4', '5']
['1', '2', '3', '4', '5']元组
定义:python中不可变的列表,与列表用[ ]表示不同,元组用( )表示。
严格来讲,元组是由逗号标记的,因此只含有一个元素的元组,要在这个元素后面加上逗号
a=(3,)不能修改元组,但是可以给存储元组的变量赋值,即重新定义整个元组。
a=(22,12)
print(a)
a=(0,2)
print(a)输出:
(22, 12)
(0, 2)if语句
在python中检查是否相等时,区分大小写。如果只想检查变量的值,可将变量的值转换为小写,再比较。
布尔表达式通常用于记录条件,结果要么为True,要么为False
if-else语句,其中else指定条件未通过时要执行的操作。
if-elif-else结构,检查超过两个情形。elif代码块可使用任意数量,在这个结构中,else代码块可没有。
注意:如果只想执行一个代码块,就使用if-elif-else;执行多个代码块,就要用很多if
字典
alien={'a':‘1’,'b':‘2’}
print(alien['a'])
print(alien['b'])输出:
1
2在python中,字典是一系列的键值对,每个键与一个值相关联。
要获取与键相关联的值,可依次指定字典名和放在方括号内的建。
添加键值对:
alien={'a':'1','b':'2'}
alien['c']='er'
print(alien)
#修改字典中的值
alien['a']=23
print(alien)
alien['b']=alien['b']+'445'
print(alien)
#删除键值对
del alien['a']
print(alien)输出:
{'a': '1', 'b': '2', 'c': 'er'}
{'a': 23, 'b': '2', 'c': 'er'}
{'a': 23, 'b': '2445', 'c': 'er'}
{'b': '2445', 'c': 'er'}对于字典而言,使用方法get()在指定的键不存在时返回一个默认值,从而避免这样的错误。
items()返回一个键值对列表。
a={'a':'aaaa','b':'bbbbb','c':'cccccc'}
print(a.items())
for k,v in a.items():
print(f'\nk:{k}')
print(f'v:{v}')输出:
dict_items([('a', 'aaaa'), ('b', 'bbbbb'), ('c', 'cccccc')])
k:a
v:aaaa
k:b
v:bbbbb
k:c
v:cccccckeys()不要字典中的值,只要字典中的建
#遍历字典中所有的键
a={'a':'aaaa','b':'bbbbb','c':'cccccc'}
print(a.items())
for k in a.keys():
print(f'\nk:{k}')输出:
dict_items([('a', 'aaaa'), ('b', 'bbbbb'), ('c', 'cccccc')])
k:a
k:b
k:cvalues()返回一个值列表。
#遍历字典中所有的值
a={'a':'aaaa','b':'bbbbb','c':'cccccc'}
print(a.items())
for v in a.values():
print(f'\nv:{v}')输出:
dict_items([('a', 'aaaa'), ('b', 'bbbbb'), ('c', 'cccccc')])
v:aaaa
v:bbbbb
v:cccccc集合和字典都是用一对花括号定义。
可在列表中存储字典,也可在字典中存储列表,也可在字典中存储字典。
用户输入和while循环
input()让程序暂停运行,等待用户输入一些文本。输入为字符串
字符串不能与数值比较。
int()将字符串转换成数值。
求模运算符%是将两个数相除并返回余数。
for:对集合中的每个元素,都执行一次代码块。
while:不断运行,直到指定的条件不满足为止。
a = 1
while a <= 4:
print(a)
a += 1输出:
1
2
3
4break:立即跳出while循环,不在运行循环中余下的代码,也不管条件测试的结果如何。
continue:根据条件测试结果决定是否继续执行循环,返回循环开头。
print('break')
a=0
while a<8:
a+=1
if a%2==0:
break
print(a)
print('continue')
a=0
while a<8:
a+=1
if a%2==0:
continue
print(a)
break
1
continue
1
3
5
7删除为特定值的所有列表元素
a=['afs','ada','adsa','eaeer']
while 'afs' in a:
a.remove('afs')
print(a)输出:
['ada', 'adsa', 'eaeer']函数
1.定义函数
def a():
print('hello')
a()hello
2.向函数传递参数
def a(num):
b=num+1
print(b)
a(2)3形参:函数完成工作时需要的信息,如上例中num
实参:调用函数时传递给函数的信息,如上例中2
向函数传递实参的方式:
- 使用位置实参,要求实参顺序与形参顺序相同。 ※顺序很重要
- 使用关键字实参,其中每个实参都由变量名和值组成
- 使用列表和字典
def a(num1,num2=4):
b=num1+num2
print(b,num1,num2)
print('位置实参')
a(2,5)
print('关键字实参')
a(num2=2,num1=5)
print('默认值')
a(3)位置实参
7 2 5
关键字实参
7 5 2
默认值
7 3 4返回值
def get_name(a,b):
full_name=f'{a} {b}'
return full_name.title()
ds=get_name('abc','ert')
print(ds)Abc Ert让实参变成可选,则可将形参默认值设置为空字符串,并将其移到形参列表末尾。
def get_name(a,c,b=''):
full_name=f'{a} {b} {c}'
return full_name.title()
ds=get_name('abc','ert')
print(ds)Abc Ert在函数定义中,新增一个可选形参age,并将其默认值设置为特殊值None,在测试条件中,None相当于False
def build_person(first_name,last_name,age=None):
person={'first':first_name,'last':last_name}
if age:
person['age']=age
else:
print('缺失年龄信息')
return person
a=build_person('ads','dasa',age=45)
print(a)
print('======')
b=build_person('seer','sdar')
print(b){'first': 'ads', 'last': 'dasa', 'age': 45}
======
缺失年龄信息
{'first': 'seer', 'last': 'sdar'}结合使用函数和while循环
def get_name(first_name,last_name):
full_name=f'{first_name} {last_name}'
return full_name.title()
while True:
print('\nPlease tell me your name:')
print('(enter’quit‘at any time to quit)')
f_name=input('first neme:')
if f_name =='quit':
break
l_name=input('last name:')
if l_name=='quit':
break
name=get_name(f_name,l_name)
print(f'\nhello,{name}!')Please tell me your name:
(enter’quit‘at any time to quit)
first neme:abd
last name:ert
hello,Abd Ert!
Please tell me your name:
(enter’quit‘at any time to quit)
first neme:quit※while语句的时候,注意循环内容,不要一直循环,无法退出。
传递列表
def get_names(names):
for name in names:
print(f'hello,{name.title()}')
use_name=['adad','sds','das']
get_names(use_name)hello,Adad
hello,Sds
hello,Das在函数中修改列表
def print_models(a,b):
while a:
c=a.pop()
print(f'printing model:{c}')
b.append(c)
def show_completed(b):
print('\nthe following models have been printed:')
for d in b:
print(d)
a=['dsdsf','ssd','sdaaer']
b=[]
print_models(a,b)
show_completed(b)printing model:sdaaer
printing model:ssd
printing model:dsdsf
the following models have been printed:
sdaaer
ssd
dsdsf可用切片法,将列表的副本传递给函数
[:]预先不知道函数需要接受多少个实参,可只用一个形参,前面加*,不管调用语句提供多少实参,这个形参会将它们统统收入囊中。
def a(*ed):
print(ed)
a('sdf','fda','sdf')('sdf', 'fda', 'sdf')如果要让函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后。
通用形参名*args,也收集任意数量的位置参数。
**kwargs,收集任意数量的关键字实参。
导入整个模块:
模块是扩展名为.py文件。
import 文件名
调用:句点表示法(文件名.函数名()调用文件中的函数。)
from 文件名 import *
导入每个函数,可通过名称来调用每个函数,无须使用句点表示法导入特定函数:
from 文件名 import 导入模块中的特定函数 as 别名
import 文件名 as 别名
类
#创建类
class Dog:#在python中,首字母大写的名称指类
#初始化属性name和age
def __init__(self,name,age):#__init__()包含三个形参,self,name,age。self是必不可少的,且必须在最前面。
self.name=name#以self为前缀的变量可供类中所有方法使用
self.age=age
#模拟小狗收到命令时蹲下
def sit(self):
print(f'{self.name} is now sitting')
#模拟小狗收到命令时打滚
def roll_over(self):
print(f'{self.name} rolled over!')
my_dog=Dog('adaf',6)
#访问属性
print(f"my dog's name is {my_dog.name.title()}")
print(f'my dog is {my_dog.age} years old')
#调用方法
my_dog.sit()
# 创建多个分类
you_dog=Dog('嘿嘿',8)
print(f"you dog's name is {you_dog.name}")
you_dog.roll_over()my dog's name is Adaf
my dog is 6 years old
adaf is now sitting
you dog's name is 嘿嘿
嘿嘿 rolled over!
#使用类和实例
class Car:
def __init__(self,make,model,year):
#初始化描述汽车属性
self.make=make
self.model=model
self.year=year
self.odometer_reading=0
def get_descriptive_name(self):
#返回整洁的描述性信息
long_name=f'{self.year} {self.make} {self.model}'
return long_name.title()
def read_odometer(self):
#打印一条指出汽车里程的消息
print(f'This car has {self.odometer_reading} miles on it.')
def update_odometer(self,mileage):
#将里程表读书设置为指定的值,禁止将里程表读数往回调
if mileage>=self.odometer_reading:
self.odometer_reading=mileage
else:
print("you can't roll back an odometer!")
def increment_odometer(self,miles):
#将里程表读书增加指定的量
self.odometer_reading+=miles
my_new_car=Car('audi','a4',2019)
print(my_new_car.get_descriptive_name())
#直接修改属性的值
my_new_car.odometer_reading=23
my_new_car.read_odometer()
#通过方法修改属性的值。
my_new_car.update_odometer(45)
my_new_car.read_odometer()
#通过方法对属性的值进行递增
my_new_car.increment_odometer(100)
my_new_car.read_odometer()2019 Audi A4
This car has 23 miles on it.
This car has 45 miles on it.
This car has 145 miles on it.继承
要编写的类是另一个现成类的特殊版本,可使用继承。一个类继承另一个类时,将自动获得另一个类的所有属性和方法。原有的类称为父类,新类成为子类。
创建子类时,父类必须包含在当前文件,且位于子类前面。
定义子类时,必须在圆括号内指定父类的名称。用super()
class Car:
def __init__(self,make,model,year):
#初始化描述汽车属性
self.make=make
self.model=model
self.year=year
def read_odometer(self):
#打印一条指出汽车里程的消息
print(f'This car has {self.odometer_reading} miles on it.')
class Elect(Car):#电动车
def __init__(self,make,model,year):
#初始化父类属性
super().__init__(make,model,year)
#初始化子类特有属性
self.battery_size=75
#给子类定义属性和方法
def describ_battery(self):
print(f"this car has a {self.battery_size}-kwh battery")
#重写父类
def read_odometer(self):
print('无')
my_tesl=Elect('asd','saf',2019)
print(my_tesl.get_descriptive_name())
my_tesl.describ_battery()
my_tesl.read_odometer()2019 Asd Saf
this car has a 75-kwh battery
This car has 0 miles on it.导入分类与导入函数,相同。
python标准库
randint()将两个整数作为参数,随机返回一个位于两个整数之间(含)的整数
from random import randint
print(randint(1,3))
3choice()将一个列表或元组作为参数,并随机返回其中一个元素:
from random import choice
a=['as','da','re']
print(choice(a))da文件与异常
打开并读取文件。
with open('文件绝对路径,用/,而不是\') as file:
contents = file_object.read()
print(contents)逐行读取
file='adsd.txt'
with open(file) as file_object:
for line in file_object:
print(line)readline()从文件中读取每一行,并将其存储在一个列表中。
读取文件时,python的所有本文都解读为字符串,如果读取的是数,并要将其作为数值使用,就必须使用函数int()将其转换为整数,或者使用函数float()将其转换为浮点数。
写入文件时,只能写入字符串,如果是数值数据,需要用str()将其转换为字符串。
写入空文件
abc='erdf.txt'
with open(abc,'w')as file_object:
file_object,write('添加')
打开文件时,’r‘是读取模式,’w‘是写入模式,’a‘是附加模式,’r+‘是读写模式’a‘附加是给文件添加内容,而不是覆盖原有的内容。
分析文本
filename='alice.txt'
try:
with open(filename,encoding='utf-8')as f:
contents=f.read()
expect FileNotFoundError:
print(f'sorry,the file{filename} does not work')
else:
#计算该文件有多少单词
words=contents.split()
num_words=len(words)
print(f'the file{filename} has about {num_words} words')存储数据
import json
#使用json.dump()存储数据
numbers=[2,3,4,6,7]
filename='number.json'
with open(filename,'w') as f:
json.dump(numbers,f )
#使用json.load()将列表中读取到内存
filename='number.json'
with open(filename) as f:
numbers=json.load(f)
print(numbers)下载数据
提取并读取数据
import csv
filename=r'D:\360极速浏览器下载\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader=csv.reader(f)
header_row=next(reader)
maxts=[]
for row in reader:
maxt=int(row[1])
maxts.append(maxt)
print(header_row[1])
print(maxts)输出:
Max TemperatureF
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57, 69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]import csv
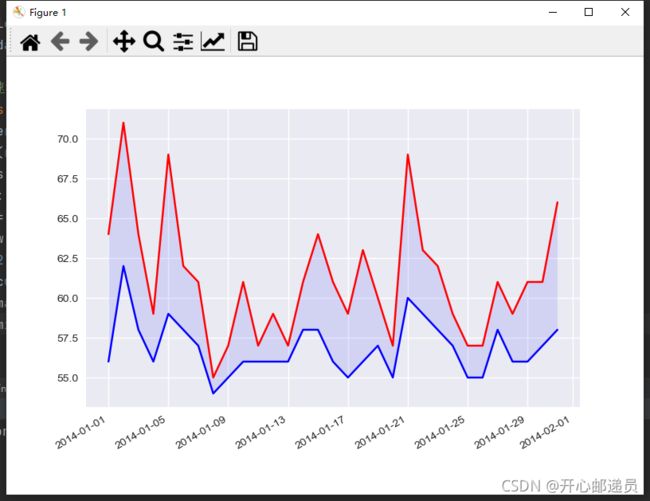
import matplotlib.pyplot as plt
from datetime import datetime
filename = r'D:\360极速浏览器下载\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, maxts,mints = [], [],[]
for row in reader:
current_date = datetime.strptime(row[0], '%Y-%M-%d')
maxt = int(row[1])
mint=int(row[2])
dates.append(current_date)
maxts.append(maxt)
mints.append(mint)
# 根据最高温度绘制图形
plt.style.use('seaborn')
fig, ax = plt.subplots() # 将包含日期信息的数据转换为datetime对象
ax.plot(dates, maxts, c='red') # 绘制点ax.scatter
ax.plot(dates,mints,c='blue')
ax.fill_between(dates,maxts,mints,facecolor='blue',alpha=0.1)#alpha是指透明度
fig.autofmt_xdate() # 绘制倾斜的日期标签
plt.show()运行