ConditionalDetr论文解读+核心源码解读
文章目录
- 前言
- 1、论文介绍
-
- 1.1. 研究问题
- 1.2. 可视化空间注意力热图
- 1.3.产生的原因
- 1.4. Conditional Cross Attn
- 1.5. 结构图
- 2、代码讲解
-
- 2.1. 核心代码
- 总结
前言
本文主要介绍下ConditionalDetr论文的基本思想以及代码的实现,首先贴上大佬的知乎解读链接,另外,本人只是在其基础上简单介绍下本人看法,远没有作者解读的透彻。(仰望大佬)
1、知乎解读
2、代码地址
3、论文地址
另外,感兴趣可以看下本人写的关于detr其他文章:
1、nn.Transformer使用
2、mmdet解读Detr
3、DeformableDetr
1、论文介绍
1.1. 研究问题
本文主要解决Detr收敛速度慢的原因,故作者首先分析导致其收敛慢的可能原因是啥:encoder只涉及图像特征向量提取;decoder中的self-attn只涉及query之间的交互去重;而最有可能发生在cross attn。原始Detr论文中query=content query + object query,而原始论文发现在第二层layer去掉object query基本不掉点,故收敛慢是content query引起的。
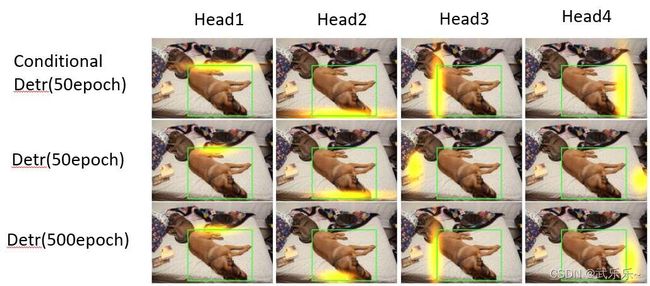
1.2. 可视化空间注意力热图
作者可视化了Detr中decoder交叉注意力的空间注意力热图:(content query+object query) * pk。发现在50epoch时,detr不能很好的预测物体的边界,这就是导致收敛慢原因。
这里我自己写了一个可视化各个head的空间注意力热图代码,感兴趣可以看看:Detr空间注意力可视化。
1.3.产生的原因
首先分析原始Detr的交叉注意力计算方式,注意使用的是加法,即cq同时和ck和pk交互容易使得网络产生困惑,故考虑将c和p解耦即可。

1.4. Conditional Cross Attn
作者采用的策略很简单,解耦即可:

1.5. 结构图
首先将object query:[N,256]映射成2d的参考点s:[N,2],之后通过下式子来将s映射成和pk一致的sin编码得到Ps。

在有了Ps之后,作者考虑到cq中蕴含了物体的边界信息,于是将cq经过FFN得到T,和Ps做了点积,得到Pq。
![]()
然后和经过self-attn的cq拼接送入cross-attn即可。

在最终预测阶段,借助参考点s和预测出偏移量即可。

2、代码讲解
由于作者代码仅仅改动了Detr的交叉注意力部分,因此,我只介绍改动部分。其余部分可参考:mmdet解读Detr
2.1. 核心代码
#-------------------#
# 对应结构图中FFN
#-------------------#
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
#---------------------------------#
# 将参考点s变成256维度的sincos的编码
#---------------------------------#
def gen_sineembed_for_position(pos_tensor):
# n_query, bs, _ = pos_tensor.size()
# sineembed_tensor = torch.zeros(n_query, bs, 256)
scale = 2 * math.pi
dim_t = torch.arange(128, dtype=torch.float32, device=pos_tensor.device)
dim_t = 10000 ** (2 * (dim_t // 2) / 128)
x_embed = pos_tensor[:, :, 0] * scale
y_embed = pos_tensor[:, :, 1] * scale
pos_x = x_embed[:, :, None] / dim_t
pos_y = y_embed[:, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()), dim=3).flatten(2)
pos_y = torch.stack((pos_y[:, :, 0::2].sin(), pos_y[:, :, 1::2].cos()), dim=3).flatten(2)
pos = torch.cat((pos_y, pos_x), dim=2)
return pos
#-------------------#
# pq的生成过程
#-------------------#
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False, d_model=256):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
self.query_scale = MLP(d_model, d_model, d_model, 2)
self.ref_point_head = MLP(d_model, d_model, 2, 2)
for layer_id in range(num_layers - 1):
self.layers[layer_id + 1].ca_qpos_proj = None
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
# 得到映射参考点s:# [num_queries, batch_size, 2]
reference_points_before_sigmoid = self.ref_point_head(query_pos)
# 经过sigmoid
reference_points = reference_points_before_sigmoid.sigmoid().transpose(0, 1)
# 开始遍历6次decoder layer
for layer_id, layer in enumerate(self.layers):
# 记录参考点s,也即后续box预测时用到
obj_center = reference_points[..., :2].transpose(0, 1)
# For the first decoder layer, we do not apply transformation over p_s
if layer_id == 0:
pos_transformation = 1
else:
# 论文中T,将cq经过FFN变换映射
pos_transformation = self.query_scale(output)
#将参考点经过sin编码得到ps
query_sine_embed = gen_sineembed_for_position(obj_center)
#对应元素相乘得到pq,二者维度[300,2,256]
query_sine_embed = query_sine_embed * pos_transformation
# 遍历decoder layer
# 拆成多头,每个头均是 content + pos_embed --> (32d+32d)
q = q.view(num_queries, bs, self.nhead, n_model//self.nhead)
query_sine_embed = self.ca_qpos_sine_proj(query_sine_embed)
query_sine_embed = query_sine_embed.view(num_queries, bs, self.nhead, n_model//self.nhead)
# 将cq和pq进行拼接
q = torch.cat([q, query_sine_embed], dim=3).view(num_queries, bs, n_model * 2)
k = k.view(hw, bs, self.nhead, n_model//self.nhead)
k_pos = k_pos.view(hw, bs, self.nhead, n_model//self.nhead)
# 将ck和pk进行拼接
k = torch.cat([k, k_pos], dim=3).view(hw, bs, n_model * 2)
# 送入nn.MultiHeadAttn()模块完成交叉注意力计算
tgt2 = self.cross_attn(query=q,
key=k,
value=v, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
总结
本文结构简介思想简单有效,仅仅用了一个解耦策略,训练速度提速10倍。后续会讲解DAB-Detr和DN-Detr,敬请期待。若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。