2022-2-14至2022-2-19周报
文章目录
- 摘要
- 深度学习
- 工程项目
- 带毕设
- 文献阅读
-
- 1 基于机器学习的海岸带水环境管理海水水质预测
摘要
- 深度学习包含两个部分,第一部分为对MLP的从零搭建、以及使用高级API两种实现方法,能够理解每一行代码、以及训练和调参。第二部分为实现房价预测模型。
- 工程项目包含两个部分,第一部分为调试与配置大数据虚拟机,所有功能包括Hadoop框架、HBase、ElasticSearch等均测试成功。第二部分为ASP.NET项目调试。
深度学习
多层感知机MLP是简单的深度神经网络模型,输入层不涉及任何计算,因此只需实现隐藏层和输出层的计算。
设 w ( 1 ) w^{(1)} w(1)是隐藏层权重, b 1 b1 b1是隐藏层偏移; w ( 2 ) w^{(2)} w(2)是输出层权重, b 2 b2 b2是输出层偏移。 X X X是输入特征。
H = σ ( X W ( 1 ) + b 1 ) H=\sigma(XW^{(1)}+b1) H=σ(XW(1)+b1)
O = H W ( 2 ) + b 2 O=HW^{(2)}+b2 O=HW(2)+b2
输入数据集为具有784个输入特征和10个类的简单分类数据集,Fashion-MNIST中的每个图像由 28×28=784 个灰度像素值组成。
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
实现一个有单隐藏层的多层感知机,该隐藏层包含256个隐藏单元:
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True))
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Paremeter(torch.randn(num_hiddens, num_outputs, requires_grad=True))
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
实现ReLU激活函数:
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
注:torch.*_like(X) 生成与张量X数据类型与形状都一样的张量
实现多层感知机模型:
def net(X):
X = X.reshape((-1, num_inputs)) #先将X拉成二维矩阵,-1代表batchsize的大小
H = relu(X @ W1 + b1) # @代表矩阵乘法
return (H @ W2 + b2)
loss = nn.CrossEntropyLoss()
多层感知机的训练过程与softmax回归的训练过程完全相同:
注:updater是更新模型参数的常用函数,它接受批量大小作为参数。它可以是封装的d2l.sgd函数,也可以是框架的内置优化函数。
assert断言函数,声明布尔值必须为真的判定,用来测试表达式,其返回值为假,就会触发异常。
class Accumulator:
"""在‘n’个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3) # 长度为3的迭代器
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad() # 梯度设置为0
l.backward() # 计算梯度
updater.step() # 参数自更新
metric.add(float(l) * len(y), accuracy(y_hat, y), y.size().numel())
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练准确率
return metric[0] / metric[2], metric[1] / metric[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
超参数:
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
训练20个周期,结果如下图
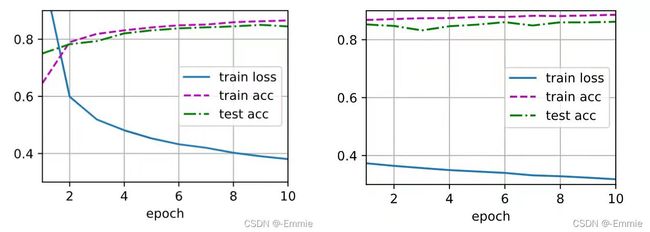
简洁实现:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameter(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
np.random.normal(loc= ,scale= ,size= )
loc定义正态分布的均值,默认为0
scale定义正态分布的方差,默认为1
size 如果仅有一个整数,设size=x,则函数从正态分布中随机产生x个值,构成一维数组输出;如果有两个整数,设size = (x, y),则函数从正态分布中随机产生xy个值,构成x行y列的二维数组输出。
房价预测:
下载缓存数据集:
import hashlib
import os
import tarfile
import zipfile
import requests
#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
将数据集缓存在本地目录:
def download(name, cache_dir=os.path.join('..', 'data')): #@save
"""下载一个DATA_HUB中的文件,返回本地文件名。"""
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}."
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # Hit cache
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
实现两个额外的实用函数,一个是下载并解压缩zip或tar文件,另一个是将本书中使用的所有数据集从DATA_HUB下载到缓存目录中:
def download_extract(name, folder=None): #@save
"""下载并解压zip/tar文件。"""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩。'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): #@save
"""下载DATA_HUB中的所有文件。"""
for name in DATA_HUB:
download(name)
访问和读取数据集:
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
加载包含训练数据和测试数据的两个CSV文件:
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
数据预处理:
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有数据都意味着消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# `Dummy_na=True` 将“na”(缺失值)视为有效的特征值,并为其创建指示符特征。
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
训练:
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
工程项目
- 此ASP.NET项目代码包括:后端由C#编写的扩展名为.aspx的ASP.NET页面、前端页面、EIP.sln类似于main函数的整个项目入口、.dll动态链接库实现共享函数库文件、BLL业务逻辑层文件、DAO数据访问层文件等。
- ASP.NET项目在web.config中配置依赖,其中包括数据库连接语句
<connectionStrings>
<add name="" connectionString="" providerName=""/>
connectionStrings>
<appSettings>
<add key="" value=""/>
appSettings>
- 处理水晶报表的报错
带毕设
1.保持沟通,学弟遇到诸如找不到kernel等的问题及时沟通解决。
2.将项目交给学弟,并指导其配置环境。
文献阅读
1 基于机器学习的海岸带水环境管理海水水质预测
- 期刊:Journal of Environmental Management(中科院SCI2区,h-index=146)
- 作者及单位:Tianan Deng, Kwok-Wing Chau, Huan-Feng Duan,香港理工大学土木与环境工程系
一、创新点:创新模型
将GA与PSO集成进学习算法中,设定吐露港藻华一周预测为建模目标。把遗传算法和粒子群优化算法用于全局搜素,再用梯度下降快速收敛。这是网络性能的问题。
二、实验过程
数据处理:
1.插值:对30年的每两周和每月的原始水质数据,选择最弱冲刷监测站A作为取样点,以便分离水动力效应hydrodynamic effects,采用线性插值linear interpolation来获得日值。
2.划分:选取前9000个样本(1988-2012年)作为训练集,其余2293个未训练数据(2012-2018年)作为测试集,得到的插值日样本总数为11293个。时序数据的处理需注意,验证集不能随机采样选取,应将数据分段,验证数据的时间在训练数据的时间往后。
3.采用5折交叉验证,将验证集从训练集中随机分成5个大小相等的子集,然后在测试阶段之前进行模型验证。
4.确定8个输入变量
5.长期的遥感证实,藻华的复现存在一到两周的循环周期,这表明藻动态在两周左右的时间间隔内具有显著的自相关性。为此,引入7-13天的滞后时间进行前置时间预测,以识别显著输入变量,即选择滞后时间为7的8个环境变量(t -13, t-12,…,t-7)作为模型的56个输入变量(t为预测时间)。
6.标准化:八个变量的量级不同
训练模型采取一层隐藏层的BP神经网络,输入层含56个节点,输出层有一个节点,产生的输出是叶绿素a的浓度。