大数据之spark_spark的案例分析
计算订单分类成交金额
需求
在给定的订单数据,根据订单的分类ID进行聚合,然后按照订单分类名称,统计出某一天商品各个分类的成交金额
数据样例
{"cid": 1, "money": 600.0, "longitude":116.397128,"latitude":39.916527,"oid":"o123", }
"oid":"o112", "cid": 3, "money": 200.0, "longitude":118.396128,"latitude":35.916527}
{"oid":"o124", "cid": 2, "money": 200.0, "longitude":117.397128,"latitude":38.916527}
{"oid":"o125", "cid": 3, "money": 100.0, "longitude":118.397128,"latitude":35.916527}
{"oid":"o127", "cid": 1, "money": 100.0, "longitude":116.395128,"latitude":39.916527}
{"oid":"o128", "cid": 2, "money": 200.0, "longitude":117.396128,"latitude":38.916527}
{"oid":"o129", "cid": 3, "money": 300.0, "longitude":115.398128,"latitude":35.916527}
{"oid":"o130", "cid": 2, "money": 100.0, "longitude":116.397128,"latitude":39.916527}
{"oid":"o131", "cid": 1, "money": 100.0, "longitude":117.394128,"latitude":38.916527}
{"oid":"o132", "cid": 3, "money": 200.0, "longitude":118.396128,"latitude":35.916527}
字段说明
oid:订单id,String类型
cid: 商品分类id,Int类型
money: 订单金额,Double类型
longitude: 经度,Double类型
latitude: 纬度,Double类型
分类信息
1,家具
2,手机
3,服装
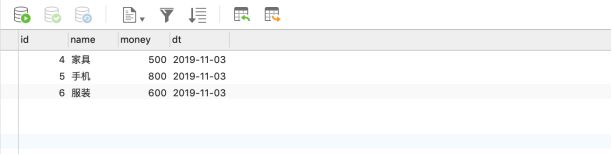
计算结果保存MySQL中
导入Maven依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.57version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
代码实现
//case class 会自动生成get和set方法还会自动实现序列化接口
//如果是普通的class类,要手动实现序列化接口Serializable并书写get,set方法,或在定义属性时添加注解@BeanProperty自动生成get,set方法
case class CaseOrderBean(var oid:String, cid:String,var money:Double,var longitude:String,var latitude:String)
import java.sql.{Connection, Date, DriverManager, PreparedStatement, SQLException}
import com.alibaba.fastjson.{JSON, JSONException}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object OrderCount {
def main(args: Array[String]): Unit = {
val isLocal = args(0).toBoolean
//创建SparkConf,然后创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getSimpleName)
if (isLocal) {
conf.setMaster("local[*]")
}
val sc = new SparkContext(conf)
//创建RDD
val lines: RDD[String] = sc.textFile(args(1))
//解析JSON
val beanRDD: RDD[CaseOrderBean] = lines.map(line => {
var bean: CaseOrderBean = null
try {
bean = JSON.parseObject(line, classOf[CaseOrderBean])
} catch {
case e: JSONException => {
//单独处理有问题的数据,可以记录日志后存储起来
}
}
bean
})
//过滤有问题的数据,因为遇到有问题的数据时,CaseOrderBean返回的null,所以需要筛选出不为null的数据
val filtered: RDD[CaseOrderBean] = beanRDD.filter(_ != null)
//将数据转成元组,分组聚合
val cidAndMoney = filtered.map(bean => {
val cid = bean.cid
val money = bean.money
(cid, money)
})
//分组聚合的RDD
val reduced: RDD[(Int, Double)] = cidAndMoney.reduceByKey(_ + _)
//在创建一个RDD
val categoryLines: RDD[String] = sc.textFile(args(2))
//分类RDD
val cidAndCName: RDD[(Int, String)] = categoryLines.map(line => {
val fields = line.split(",")
val cid = fields(0).toInt
val cname = fields(1)
(cid, cname)
})
val joined: RDD[(Int, (Double, String))] = reduced.join(cidAndCName)
//将join后的数据在进行处理
val result: RDD[(String, Double)] = joined.map(t => (t._2._2, t._2._1))
//正确的姿势
//将数据写入到MySQL
result.foreachPartition(it: Iterator[(String, Double)]) => {
//创建MySQL连接
var conn: Connection = null
var statement: PreparedStatement = null
try {
conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8",
"root",
"123456")
statement = conn.prepareStatement("INSERT INTO t_result values (null, ?, ?, ?)")
//将迭代器中的数据写入到MySQL
it.foreach(t => {
statement.setString(1, t._1)
statement.setDouble(2, t._2)
statement.setDate(3, new Date(System.currentTimeMillis()))
//执行executeUpdate,单条写入
//statement.executeUpdate()
//批量写入
statement.addBatch()
})
statement.executeBatch()
()
} catch {
case e: SQLException => {
//单独处理有问题的数据
}
} finally {
//释放MySQL的资源
if (statement != null) {
statement.close()
}
if (conn != null) {
conn.close()
}
}
sc.stop()
}
}