机器学习笔记4-0:PyTorch教程
*注:本博客参考李宏毅老师2020年机器学习课程. 视频链接
目录
- 1 Tensor
-
- 1.1 Tensor创建
-
- 1.1.1 从数据创建
- 1.1.2 创建特殊值的Tensor
- 1.1.3 创建指定步长的Tensor
- 1.2 Tensor组合与变换
-
- 1.2.1 两个Tensor拼接
- 1.2.2 Tensor变形
- 1.2.3 Tensor维度操作
- 1.3 Tensor运算
-
- 1.3.1 四则运算
- 1.3.2 矩阵乘法与向量内积
- 1.3.3 求导
- 2 网络模型
-
- 2.1 线性模型
- 2.2 激活函数
- 2.3 模型堆叠
- 2.4 损失函数
- 2.5 优化器
- 3 数据组织
-
- 3.1 Dataset
- 3.2 PyTorch预定义数据集
-
- 3.2.1 MNIST数据集加载示例
- 3.2.2 数据可视化
- 3.2.3 Transforms
- 3.3 自定义Dataset
- 3.4 DataLoader
- Reference
1 Tensor
Tensor是PyTorch中最基础的一种数据结构,与Numpy中的ndarray相似,用来存储数据,并封装了许多对于数据和向量的操作。
1.1 Tensor创建
1.1.1 从数据创建
创建Tensor的基本方式是从数据创建:
torch.tensor(data, #数据内容,可以是list,tuple或ndarray类型
dtype=None, #Tensor中数据的类型,Numpy中也有一样的参数
device=None, #该Tensor所在的cuda/cpu设备,设置为cuda即可使用GPU加速
requires_grad=False) #是否需要对该Tensor求梯度
t1 = torch.tensor([1, 2, 3]) # 从list创建
t2 = torch.tensor(np.ones((1, 2))) # 从ndarray创建
print(t1)
print(t2)
tensor([1, 2, 3])
tensor([[1., 1.]], dtype=torch.float64)
此外,还有一种方式是使用torch.as_tensor,也可以从list,tuple,ndarray等数据结构创建,但是使用该方法创建的Tensor与ndarray内存共享,这意味着其中一个改变时,另一个也将改变,而torch.tensor则是创建一个新的变量,不会共享内存。
a = np.array([1, 2, 3])
t1 = torch.as_tensor(a)
t2 = torch.tensor(a)
print(t1, t2)
a *= 3 # 改变ndarray的值
print(t1, t2)
tensor([1, 2, 3], dtype=torch.int32) tensor([1, 2, 3], dtype=torch.int32)
tensor([3, 6, 9], dtype=torch.int32) tensor([1, 2, 3], dtype=torch.int32)
使用torch.from_numpy也可以从ndarray创建Tensor,且共享内存,但是该方法的参数只能是ndarray。对三种方法总结如下:
| 方法名 | 参数 | 共享内存 |
|---|---|---|
| torch.tensor | list,tuple,或ndarray | 否 |
| torch.as_tensor | list,tuple,或ndarray | 是 |
| torch.from_numpy | ndarray | 是 |
1.1.2 创建特殊值的Tensor
在Numpy中可以使用zeros、ones等方法创建全为0或1的ndarray,PyTorch中也有类似的操作,见下表:
| 方法名 | 参数 | 功能解释 |
|---|---|---|
| torch.ones | size | 创建指定size的全为1的Tensor |
| torch.zeros | size | 创建指定size的全为0的Tensor |
| torch.full | size,value | 创建被value填充的指定size的Tensor |
| torch.eye | n,m=None | 创建n行m列的对角线为1,其余全为0的Tensor,m默认等于n |
| torch.empty | size,out=None | 创建size大小的全为0的Tensor,若指定out,则以out对应索引填充 |
上述使用到size参数的方法均可以在方法名之后添加*_like*,既可以将size参数换成一个Tensor,创建与该Tensor的size相同的Tensor。
1.1.3 创建指定步长的Tensor
有时我们需要在两个值之间等距离地取点,从而创建一个列表。在PyTorch中,可以使用如下两种方式实现:
t1 = torch.linspace(0, 100, 20) # 在[0,100]中等间距地取20个点
t2 = torch.arange(0, 100, 20) # 在[0,100]中每隔20取一个点
print(t1)
print(t2)
tensor([ 0.0000, 5.2632, 10.5263, 15.7895, 21.0526, 26.3158, 31.5789,
36.8421, 42.1053, 47.3684, 52.6316, 57.8947, 63.1579, 68.4211,
73.6842, 78.9474, 84.2105, 89.4737, 94.7368, 100.0000])
tensor([ 0, 20, 40, 60, 80])
1.2 Tensor组合与变换
1.2.1 两个Tensor拼接
使用torch.cat拼接两个Tensor,默认从第0个维度拼接,使用参数dim可以指定维度。但是必须保证在dim之后的维度的size一致。例如size分别为(2,3,2)和(1,3,2)的两个Tensor不能不能在第0维度拼接,但是第1和第2都可以。
t1 = torch.ones((1, 2))
t2 = torch.zeros((1, 2))
print(t1, t2)
print(torch.cat((t1, t2))) # 在第0个维度上拼接两个Tensor
print(torch.cat((t1, t2), dim=1)) # 在第1个维度上拼接两个Tensor
tensor([[1., 1.]]) tensor([[0., 0.]])
tensor([[1., 1.],
[0., 0.]])
tensor([[1., 1., 0., 0.]])
1.2.2 Tensor变形
将一个size为(1,2,3)的Tensor变形为size(3,2)的Tensor,可以使用如下两种方式,两种方式均不会改变Tensor本来的size,而是将变形后的Tensor以克隆的方式返回。
t = torch.ones((1, 2, 3))
print(t.reshape(3, 2).size())
print(t.view(3, 2).size())
torch.Size([3, 2])
torch.Size([3, 2])
1.2.3 Tensor维度操作
对维度的操作包括增减维度,交换维度等,以下给出了一些例子:
注意:在PyTorch中,部分方法在方法名结尾添加一个下划线,这些带下划线的方法会改变操作的Tensor本身,而对应不带下划线的方法则是返回一个改变后的Tensor的复制,原Tensor不变。
t = torch.ones((1, 2, 3, 1))
print(t.squeeze().size()) # 去除Tensor中所有长为1的维度
print(t.unsqueeze(dim=1).size()) # 在指定的dim上添加一个维度
print(t.transpose(0, 1).size()) # 交换第0和第1个维度
print(t.T.size()) # 转置,相当于把所有维度颠倒
print("-"*15)
for t_ in t.unbind(dim=1):
print(t_.size()) # 按指定dim拆分Tensor,相当于去掉这一个维度,若对应dim的长度为n,则会返回一个长为n的tuple
torch.Size([2, 3])
torch.Size([1, 1, 2, 3, 1])
torch.Size([2, 1, 3, 1])
torch.Size([1, 3, 2, 1])
---------------
torch.Size([1, 3, 1])
torch.Size([1, 3, 1])
1.3 Tensor运算
1.3.1 四则运算
Tensor之间直接使用四则运算符即可进行四则运算:
a = torch.tensor([12, 4, 6])
b = torch.tensor([4, 2, 3])
print("a+b={}".format(a+b))
print("a-b={}".format(a-b))
print("a*b={}".format(a*b))
print("a/b={}".format(a/b))
a+b=tensor([16, 6, 9])
a-b=tensor([8, 2, 3])
a*b=tensor([48, 8, 18])
a/b=tensor([3., 2., 2.])
1.3.2 矩阵乘法与向量内积
按照线性代数矩阵乘法的要求,如果两个矩阵可积,则可以使用.dot函数或者@运算符进行矩阵乘法运算;特别的,如果进行运算的两个矩阵均为一维,且具有相同的长度,则进行向量内积:
print("a.shape:{}".format(a.shape))
print("b.shape:{}".format(b.shape))
print(a@b) # 向量内积
c = torch.tensor([[1, 2, 3], [3, 4, 5]])
d = torch.tensor([[1, 2], [3, 4], [5, 6]])
print("c.shape:{}".format(c.shape))
print("d.shape:{}".format(d.shape))
print(c@d) # 矩阵乘法
a.shape:torch.Size([3])
b.shape:torch.Size([3])
tensor(74)
c.shape:torch.Size([2, 3])
d.shape:torch.Size([3, 2])
tensor([[22, 28],
[40, 52]])
1.3.3 求导
如果要计算一个式子对于某一个变量的导数,需要以下三个步骤:
- 声明需要求导的Tensor,设置其requires_grad属性为True;
- 执行所需的运算,对运算所得的Tensor调用backward()方法;
- 对需要求导的Tensor调用grad方法。
注意:PyTorch只能对dtype为浮点类型的Tensor求导,所以如果是手动输入数据,需要添加一个小数点。
x = torch.tensor(5., requires_grad=True)
y = 3*x+4*x**2
y.backward()
print(x.grad)
tensor(43.)
backward()方法会对Tensor的所有标记为requires_grad的Tensor x求导,但是如果x并不是一个一维的变量,则需要传入一个参数,指示x的size,一般可以使用.clone().detach()方法获得一个与x相同size的Tensor,传入函数。
x = torch.tensor([[2., 5.], [4., 6.]], requires_grad=True)
y = 3*x+4*x**2
y.backward(x.clone().detach())
print(x.grad)
tensor([[ 38., 215.],
[140., 306.]])
对于已经标记为require_grad的Tensor,有时我们并不想对它求导数,例如使用已经训练好的模型只进行前向传播时,或者对于某些参数不想要它们在更新时改变(例如一些预训练模型),这时我们也可以禁用这些参数的自动求导。禁用自动求导也会令前向传播的计算更加迅速。
如果是对某个参数禁用求导,调用其detach()方法即可:
x = torch.tensor(5., requires_grad=True)
print(x.requires_grad)
x = x.detach()
print(x.requires_grad)
True
False
如果要对多个参数禁用求导,或者仅仅在某一段代码中禁用求导,可以将这些代码作为with torch.no_grad()的子块:
x1 = torch.tensor(5., requires_grad=True)
x2 = torch.tensor(5., requires_grad=True)
z = x1*x2
print(z.requires_grad)
with torch.no_grad():
z = x1*x2
print(z.requires_grad)
True
False
2 网络模型
在前面的章节中,我们手动实现了线性回归和逻辑回归,目的是更深入的理解这些模型,但是在实际科研场景下,PyTorch能够为我们提供更为简洁、方便的实现方式,很多网络模型在PyTorch的torch.nn模块中已经实现了。
2.1 线性模型
首先来看线性模型,torch.nn.Linear(),该模型的输入是一个Tensor,该方法需要指定两个参数,in_feature和out_feature,这两个参数决定了模型的输入维度和输出维度的长度,相当于一个单层的神经网络。当输入包含多个维度时,线性模型将最后一个维度视为模型的输入,因此模型输入的最后一维的长度必须与模型参数的in_feature相同。
当调用torch.nn.Linear()的同时,这个线性模型的权重和偏置就已经初始化为随机值了,因此可以访问其值。
model = torch.nn.Linear(3, 4) # 模型输出维度长为4
x = torch.ones((2, 3)) # size为(2,3)的输入
y = model(x)
print(y.shape) # 输出
print(model.weight.shape) # 模型权重
print(model.bias.shape) # 模型偏置
torch.Size([2, 4])
torch.Size([4, 3])
torch.Size([4])
2.2 激活函数
在前面的章节中,我们介绍了sigmoid、ReLU等激活函数,这些函数在torch.nn模块中也已经定义完成,直接调用即可。
activation_fn = torch.nn.Sigmoid()
z = torch.ones([2, 3])
y = activation_fn(z)
print(y)
tensor([[0.7311, 0.7311, 0.7311],
[0.7311, 0.7311, 0.7311]])
2.3 模型堆叠
假设我们需要设计一个比较复杂的模型,该模型包含很多层线性模型,同时每一个线性模型之后都要使用到激活函数,还可能需要套经过三角函数、求和、求平均等等一系列操作。一种可行的做法是将每一个步骤都调用torch.nn中的对应模块,再将每一个模块的输入和下一个模块的输出连接起来。但其实PyTorch为我们提供了更为简洁的方式,即使用torch.nn.Sequential方法,该方法的参数可以包含任意个torch.nn中的模块,调用该方法之后PyTorch会自动将前一个模块的输出作为下一个模块的输入。
model = torch.nn.Sequential(
torch.nn.Linear(3, 4),
torch.nn.Sigmoid(),
torch.nn.Linear(4, 8),
torch.nn.Sigmoid(),
torch.nn.Linear(8, 2),
torch.nn.Softmax(1))
x = torch.ones((2, 3))
y = model(x)
print(y.shape)
print(y)
torch.Size([2, 2])
tensor([[0.3866, 0.6134],
[0.3866, 0.6134]], grad_fn=)
使用torch.nn.Sequential构建的模型的参数库使用.parameters()方法得到。
for p in model.parameters():
print(p.shape)
torch.Size([4, 3])
torch.Size([4])
torch.Size([8, 4])
torch.Size([8])
torch.Size([2, 8])
torch.Size([2])
2.4 损失函数
在torch.nn模块中,还定义了许多典型的损失函数可供选择,如均方差torch.nn.MSELoss,交叉熵torch.nn.CrossEntropyLoss等等。损失函数的函数名均以Loss结尾在实际编程中,一般只需要输入"torch.nn.Loss",编辑器就会自动列出所有函数名包含Loss的函数。
2.5 优化器
有了上述知识之后,其实我们已经可以动手实现一个神经网络,并通过梯度下降算法来更新模型的参数。但是实际上,这个步骤在PyTorch中也可以更简单,下面我们来看这样一个例子:
# 定义数据集
x = torch.ones(2)
true_w = torch.tensor([[2., 3]])
y = true_w@x
# 定义模型,取消bias
model = torch.nn.Linear(2, 1, bias=False)
# 定义损失函数
mse_loss = torch.nn.MSELoss()
# 定义优化器,使用随机梯度下降算法
optim = torch.optim.SGD(model.parameters(), lr=1e-2)
# 查看初始的模型参数:
print("--before trainning:")
print(model.weight[0].detach().numpy())
# 将输入送入模型,计算损失函数值
for i in range(100):
y1 = model(x) # 计算输出
loss = mse_loss(y, y1) # 计算损失函数
loss.backward() # 反向传播
optim.step() # 该步骤将会利用反向传播得到的偏导更新参数
optim.zero_grad() # 清空梯度,否则每次迭代都会导致上一行计算的梯度堆叠
print("--after trainning:")
print(model.weight[0].detach().numpy())
--before trainning:
[-0.2506011 0.4836213]
--after trainning:
[2.092678 2.8269017]
在上述代码中,我们首先定义了数据集,尽管该数据集只包含一个数据点。接着我们定义了一个简单的线性模型,该模型的参数会被自动标记为require_grad。下一行将损失函数定义为均方差。紧接着我们定义了一个SGD优化器,该优化器即使用了SGD算法,在计算梯度之后,只需调用优化器的step()方法,就能根据梯度对模型的各个参数进行求导。但是需要注意,声明优化器对象时,需要将网络的参数传递给优化器对象,这样它才能知道需要更新哪些参数,此外,还可以通过lr参数指定学习速率。之后再循环中的步骤就是一轮迭代所需要做的事情:计算输出,计算loss,反向传播,更新参数。值得注意的是,由于model的参数被标记为需要求导,因此PyTorch将会自动记录所有与其参数有关的运算,在反向传播的时候依照链式求导法则计算偏导值,因此如果不消除上一次迭代对模型参数的操作,将会导致求梯度的链越来越深,因此我们在每一次迭代中都调用了优化器的.zero_grad()方法,该方法能够清空之前对模型参数的操作。
下面我们以一种更为现实的例子来说明堆叠模型所产生的线性结构的有效性。
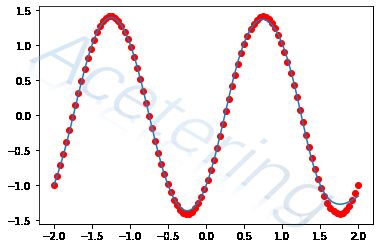
- 数据集方面,我们使用-2到2的100个元素构成的等差数列,y= s i n ( x π ) − c o s ( x π ) sin(x\pi)-cos(x\pi) sin(xπ)−cos(xπ);
- 构建模型的过程中,我们使用到了一种新的激活函数——双曲正切函数,torch.nn.Tanh;
- 损失函数依然使用均方差;
- 优化器选择SGD优化器,学习速率被设置为0.05,除此之外,momentum参数表示冲量,即更新参数的过程中,上一次参数更新的变化值对这一次参数更新的影响程度,这里设为0.5;
- 使用了冲量之后,模型更容易忽略局部最优值,找到全局最优值;
- 使用了冲量之后,模型收敛的速度会更快;
- 在每一轮迭代中,我们仅使用数据集中的随机40个元素来训练,以此减少模型的过拟合问题;
在上述配置下训练5000个epoch,打印loss的变化,并在图中画出模型所拟合的曲线和参考值。
import matplotlib.pyplot as plt
X = torch.linspace(-2, 2, 100).reshape(100, 1)
Y = torch.sin(np.pi*X)-torch.cos(np.pi*X)
model = torch.nn.Sequential(
torch.nn.Linear(1, 8),
torch.nn.Tanh(),
torch.nn.Linear(8, 4),
torch.nn.Tanh(),
torch.nn.Linear(4, 1)
)
loss_fn = torch.nn.MSELoss()
optim = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.5)
for i in range(5000):
idx = np.random.choice(100, 40)
Y1 = model(X[idx])
loss = loss_fn(Y1, Y[idx])
optim.zero_grad()
loss.backward()
optim.step()
if i % 500 == 0:
print("iter:{} loss:{:.4f}".format(
i, loss))
plt.scatter(X, Y, c="red")
plt.plot(X, model(X).detach().numpy())
plt.show()
iter:0 loss:1.0031
iter:500 loss:0.5139
iter:1000 loss:0.0052
iter:1500 loss:0.0021
iter:2000 loss:0.0026
iter:2500 loss:0.0020
iter:3000 loss:0.0031
iter:3500 loss:0.0017
iter:4000 loss:0.0010
iter:4500 loss:0.0019
3 数据组织
在训练一个深度学习模型之前,我们需要准备好用于模型训练和测试的数据集,为此,我们需要写一段用于读取、加载、处理数据的代码,这些代码可能与模型训练的代码高度耦合而导致难以迁移,对不同的数据集可能也有不同的处理方式,从而导致代码混乱而难以维护。PyTorch库为我们提供了Dataset和DataLoader两个类,用来“优雅”地存储和装载数据,这两个类均位于torch.utils.data模块下。下面对PyTorch中数据组织地方法进行介绍。
3.1 Dataset
Dataset是一个抽象类,用来存储原始数据,所有Dataset的子类都包含两个方法:__get_item__()和__len__(),这意味着它就像列表一样,可以通过方括号加索引来访问其内部数据,也可以通过len()方法获得其长度。一般我们使用到的都是Dataset,都是PyTorch预定义好的数据集,或者我们继承Dataset类所实现的子类。
Dataset类的重要作用就是作为参数,传递给DataLoader类,该类将在后面介绍。
3.2 PyTorch预定义数据集
在PyTorch中,一些常用的数据集都已经被单独封装成了Dataset的子类,我们只需调用对应的模块就可以获取到这些数据,不同类别的数据集位于不同的模块下:
- torchvison.datasets包含图片数据集,如手写数字识别数据集MNIST、用于目标检测与识别的COCO数据集等;
- torchaudio.datasets包含语音数据集,如LibriTTS、LJSPEECH等;
- torchtext.datasets包含文本数据集,如DBpedia、WikiText-2、UDPOS等。
具体的数据集获取方法和介绍请参考PyTorch官方教程-DATASETS & DATALOADERS。
3.2.1 MNIST数据集加载示例
下面我们以MNIST数据集为例,说明获取数据集的方法:
from torchvision import datasets, transforms
mnist_data = datasets.MNIST(root='./datas/', # 数据集存储路径
train=True, # 是否是训练集
transform=transforms.ToTensor(), # 转换数据部分的方式
download=False) # 是否下载数据集
在上面加载数据集的过程中,我们使用到了四个参数:
- root:该参数指示数据集存放的位置,加载数据集时首先会检查该路径下是否有数据,如果有,则直接读取;
- train:该参数指示本次加载的是数据集的训练集还是测试集,若为True,则表示训练集,加载时将会只读取训练集的数据;
- transform:该参数指示数据集中的数据部分的转换方式,还有一个target_transform参数,决定数据集中标签的转换方式;
- download:该参数指示是否下载数据集,若为True,则当root参数所示路径下不存在数据,则会自动从PyTorch指定的网址下载该数据集。
读取到的数据集可以使用mnist_data[idx]直接访问内部数据,将会返回一个(data,label)的元组,data包含一个数字图片的灰度图数据,在mnist数据集中单张图片尺寸是是28*28像素,对应的,data是一个size为(1,28,28)的矩阵。而label一般是一个数值,在MNIST数据集中,label的值恰好是图片的数字,但是其实图片标签所属的类别在mnist_data.classes中已经定义好了,可以通过mnist_data.classes[label]获取label对应的类别。
下面展示了mnist_data的一些数据:
print("length of mnist_data: {}".format(mnist_data.__len__()))
print("classes of mnist_data: {}".format(mnist_data.classes))
data, label = mnist_data[0]
print("shape of data: {}".format(data.shape))
print("value of label: {}".format(label))
print("class of label: {}".format(mnist_data.classes[label]))
length of mnist_data: 60000
classes of mnist_data: ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four', '5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
shape of data: torch.Size([1, 28, 28])
value of label: 5
class of label: 5 - five
3.2.2 数据可视化
数据可视化是一个重要的技巧,下面使用matplotlib对部分数据可视化:
import matplotlib.pyplot as plt
figure = plt.figure(figsize=(8, 8))
for i in range(1, 10):
# 获取一个指定size的随机整型Tensor,第一个参数表示随机的最大值
# 当Tensor仅包含一个值时,使用item()可以将这个Tensor转化为一个数字
idx = torch.randint(len(mnist_data), size=(1,)).item()
figure.add_subplot(3, 3, i) # 向图中添加子图
data, label = mnist_data[idx] # 获取单个数据和标签
plt.title(mnist_data.classes[label]) # 绘制子图标题
plt.axis("off") # 清除子图坐标轴
img = data.squeeze() # 去掉data的第一个维度
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

3.2.3 Transforms
由于不同的机器学习算法对于输入和输出有不同的格式要求,在加载数据的时候往往需要进行数据格式上的转换。实际上在之前加载MNIST数据集的时候,已经对数据部分进行了一次转换——我们使用了transform=transforms.ToTensor()这一参数,将原本PIL图片格式的数据转换为了Tensor。ToTensor()这一方法将PIL图片或者以ndarry表示的图片(H*W*C)转换为Tensor(C*H*W),并且原来每个值域 [ 0 , 255 ] [0,255] [0,255]像素点将会被压缩到 [ 0 , 1 ] [0,1] [0,1]。PyTorch中还有内置了许多其他的转换方法,详情参见torchvision.transforms。
除了使用内置的转换方法,我们也可以使用lambda表达式自定义转换方式。以MNIST数据集为例,在训练该数据集时,我们往往需要做如下转换:
- 将原本size为(1,28,28)的reshape成一个长为784的向量;
- 将标签应用one-hot编码,以完成多类别的分类任务。
于是在加载数据集时,我们可以这样写:
from torchvision.transforms import Lambda, Compose
print("data shape before : {}".format(mnist_data[0][0].shape))
print("label before : {}".format(mnist_data[0][1]))
mnist_data = datasets.MNIST(root='./datas/', # 数据集存储路径
train=True, # 是否是训练集
transform=Compose([transforms.ToTensor(),
Lambda(lambda x: x.view(784))]), # 转换数据部分的方式
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float)
.scatter_(dim=0, index=torch.tensor(y), value=1)),
download=False) # 是否下载数据集
print("data shape after : {}".format(mnist_data[0][0].shape))
print("label after : {}".format(mnist_data[0][1]))
data shape before : torch.Size([1, 28, 28])
label before : 5
data shape after : torch.Size([784])
label after : tensor([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.])
在上面一段代码中,我们使用到了两个类,Lambda类允许传入一个lambda表达式作为参数,构造一个Transform对象;Compose类允许传入一个由多个Transform对象构成的列表,构造一个依次执行列表中的转换的Transform对象。
注意:将size为(1,28,28)的图片转换为长为784的向量,也可以使用torch.nn.Flatten(),两者效果一样。
3.3 自定义Dataset
当我们需要使用PyTorch中没有的数据集,就需要我们自己实验一个Dataset的子类,必须实现的方法有以下三个:
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, transform=None, target_transform=None):
self.data = torch.ones(100, 2)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data, label = self.data[idx]
if self.transform:
data = self.transform(data)
if self.target_transform:
label = self.target_transform(label)
return data, label
d = CustomDataset()
print(d[0])
(tensor(1.), tensor(1.))
3.4 DataLoader
Dataset是一个存储数据和标签的容器,我们可以通过下标访问其内部的数据和标签。但是在实际的深度学习模型的训练过程中,我们并不是顺序读取每个训练样本,而是使用mini-batch,一次读取几个样本,并且每次读取到的样本都是随机的,这样看可以减少过拟合现象的影响,此外,如果能够利用Python的并行计算能力加速训练过程,那就更好了。
这就是DataLoader存在的意义——它帮助我们解决了上述所有问题。在初始化一个DataLoader的实例时,我们需要为它传递一个Dataset对象作为数据源,它还有两个可选的参数batch_size和shuffle:
- batch_size 决定每次取出多少个样本;
- shuffle 每个epoch结束之后是否打乱训练数据的顺序,以实现随机读取。
DataLoader中的数据可以通过next(iter(loader))来访问,iter()函数返回一个迭代器对象,每使用一次next()取出一组数据,直到DataLoader中的所有数据都被取出。
from torch.utils.data import DataLoader
loader = DataLoader(mnist_data, batch_size=16, shuffle=True)
data,label=next(iter(loader))
print("shape of data: {}".format(data.shape))
print("shape of label: {}".format(label.shape))
shape of data: torch.Size([16, 784])
shape of label: torch.Size([16, 10])
如果要遍历DataLoader中所有的数据,使用enumerate(loader),该方法返回两个值,第一个是一个计数器,第二个是DataLoader对象中的数据,以(data,label)的形式给出。
loader = DataLoader(mnist_data, batch_size=16, shuffle=True)
batch_counter = 0
for batch, (x, y) in enumerate(loader):
batch_counter += 1
print(batch_counter)
print(loader.batch_size*batch_counter, len(mnist_data))
3750
60000 60000
Reference
- PyTorch学习笔记1:PyTorch基础知识 - 张浩驰的文章 - 知乎
- 李宏毅2020机器学习深度学习(完整版)国语-P16 Pytorch Tutorial
- PyTorch 官方教程