【MySQL 读写分离】Sharding JDBC + Spring boot 实现数据库读写分离的登录 Demo
上篇文章我们搭建了 MySQL 数据库主从复制集群 MySQL 搭建主从复制集群~~~
本篇文章我们利用搭建好的主从复制集群,使用 SpringBoot 结合 Sharding-JDBC 搭建一个小的 登录 Demo,测试实现数据库的读写分离
项目源码地址: https://gitee.com/liuwanqing520/login-sharding
一、Sharding-JDBC 是什么?
Apache ShardingSphere 是一款分布式的数据库生态系统(关系型数据库中间件),可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。而ShardingSphere-JDBC 就是它的一个重要产品。
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。其具有如下特点:
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
Sharding-JDBC 的工作方式如下:
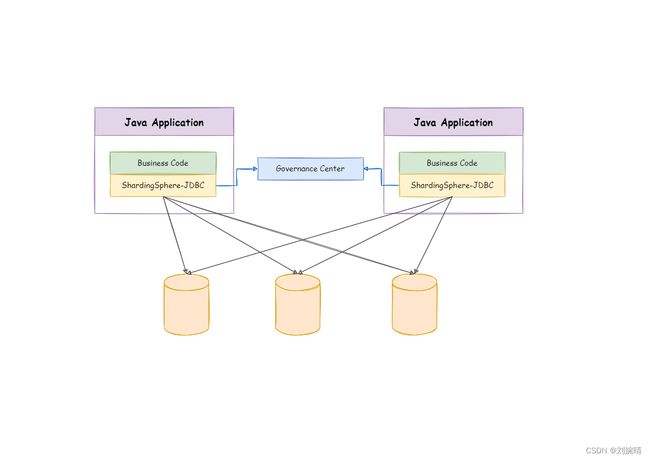
二、SpringBoot 整合 Sharding-JDBC
1. 导入 Sharding-JDBC 依赖
在 pom.xml 文件中,加入如下依赖
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-core-commonartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.14version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.2.0version>
dependency>
2. 配置主从数据源地址
在 application.yml 配置文件中加入如下数据源配置
# DataSource Config
spring:
shardingsphere:
# 配置数据源
datasource:
# 给每个数据源取别名,任意取
names: master, slave
# 配置主数据源数据库连接信息(只写)
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.244.130:3306/survey?characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 5201314love
# 配置从数据源数据库连接信息(只读)
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.244.131:3306/survey?characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 5201314love
masterslave:
# 配置 slave 节点的负载均衡策略 :轮询机制 (我这里只有一个从数据库,有没有这句没啥用)
load-balance-algorithm-type: round_robin
name: dataSource
# 配置主库 ,负责数据的写入
master-data-source-name: master
# 配置从库
slave-data-source-names: slave
# 显示SQL,方便我们查看 SQL 语句在那个数据源中执行
props:
sql:
show: true
3. 编写 User 类
后面我会放完整项目链接,这里大家就当看个热闹
@Data
public class User implements Serializable {
private Long id;
private String username;
private String avatar;
private String email;
private String password;
private Integer status;
// 用户的权限 —— 0 系统管理员 1 租户 2 普通用户
private Integer permission;
}
4. 封装 Result 返回类
@Data
public class Result implements Serializable { //序列化
private int code; //200是正常 400表示异常
private String msg;
private Object data; //返回数据
//成功
public static Result succ( Object data){
return succ(200,"操作成功",data);
}
//成功
public static Result succ(int code,String msg,Object data){
Result r = new Result();
r.setCode(code);
r.setMsg(msg);
r.setData(data);
return r;
}
//失败
public static Result fail(String msg){
return fail(400,msg,null);
}
//失败
public static Result fail(String msg,Object data){
return fail(400,msg,data);
}
//失败
public static Result fail(int code,String msg,Object data){
Result r = new Result();
r.setCode(code);
r.setMsg(msg);
r.setData(data);
return r;
}
}
5. 编写 UserController 实现登录注册逻辑
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
// 登录方法
@RequestMapping("/login")
public Result login(@RequestBody Map<String, String> map) {
String name = map.get("username");
log.info(name);
String password = map.get("password");
// 是否存在改用户名的用户
User user = userService.getOne(new QueryWrapper<User>().eq("username", name));
if (user == null) {
return Result.fail("用户名不存在");
}
if(!user.getPassword().equals(password )){
return Result.fail("密码错误");
}
return Result.succ(user);
}
// 注册方法
@PostMapping("/save")
public Result save(@Validated @RequestBody User user){
// 判断是否用户名已经存在
User userTemp = userService.getOne(new QueryWrapper<User>().eq("username", user.getUsername()));
if (userTemp != null) {
return Result.fail("用户名已经存在");
}
if(user.getUsername() == null || user.getPassword() == null || user.getUsername().length()==0 || user.getPassword().length() == 0){
return Result.fail("用户名和密码不能为空");
}
return userService.save(user) ? Result.succ(user) : Result.succ("新增失败");
}
}
6. 启动项目,访问接口,进行测试
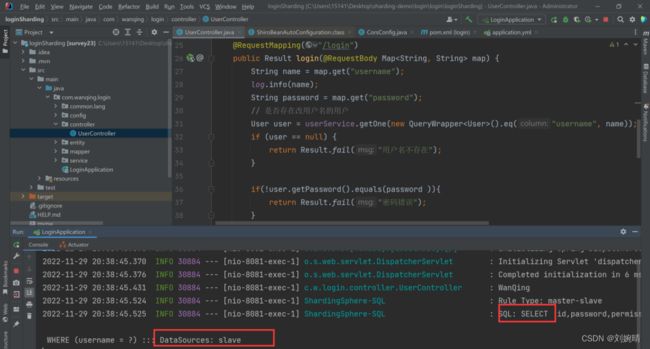
- 访问登录的 URL,可以看到该操作在 Slave 库中进行,因为我们设置读操作在从库中进行。
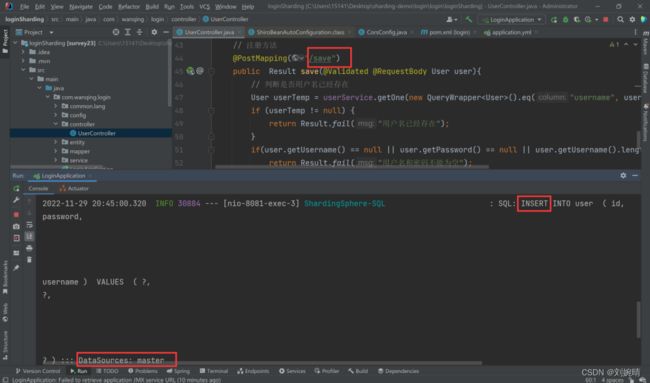
- 访问注册的 URL,可以看到该操作在 Master 库中进行,因为我们设置写操作在主库中进行。
三、总结与项目源码地址
通过上述步骤我们也可以发现,结合 SpringBoot 实现数据库的读写分离,在业务逻辑代码上并无什么改动,主要是导入好依赖,配置好各数据库访问操作在那个库上执行。下面是完整项目地址 ,供大家下载参考学习使用,在使用过程中如有问题,欢迎评论区和我交流 ~~
源码地址:https://gitee.com/liuwanqing520/login-sharding
注: 这里包括完整前后端的代码,其实如果只是想测试读写分离,只有后端就够了,为了完善一点,我把前端也加上了