记录下完整的MySQL8.0主从复制+读写分离(ShardingJDBC)搭建过程
一、为什么使用主从复制、读写分离
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
二、主从复制(也称 A/B 复制))的原理
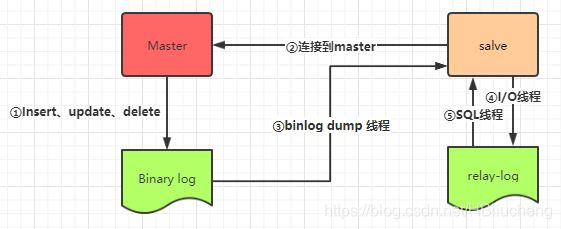
①Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件,这些记录叫做二进制日志事件(binary log events);
②salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。
③当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。
④Slave 通过 I/O 线程读取 Master 中的 binary log events 并写入到它的中继日志(relay log);
⑤SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。
三、如何实现主从复制
1,主从配置需要注意的点
- 主从服务器操作系统版本和位数一致;
- Master 和 Slave 数据库的版本要一致;
- Master 和 Slave 数据库中的数据要一致;
- Master 开启二进制日志, Master 和 Slave 的 server_id 在局域网内必须唯一;
我这里用三台虚拟机(Linux)演示,IP分别是50(Master),51(Slave),52(Slave)。
预期的效果是一主二从,如下图所示:

linux上mysql不会安装的请先安装下https://blog.csdn.net/HBliucheng/article/details/113601299
2,Master配置
目录结构如下

启动mysql并使用命令行进入mysql:
#启动mysql
./mysql.server start
#进入mysql
./mysql -uroot -p
接着输入root用户的密码(密码忘记的话就网上查一下重置密码吧~),然后在主节点创建一个用户repl,用于从节点链接主节点时使用。
注意:
mysql8.0后创建用户和授权分开写
在5.7可能是合在一起写的,写法如下
GRANT REPLICATION SLAVE ON . to ‘username’@‘xxx.xxx.xxx.xxx’ identified by ‘password’;
#192.168.119.51是slave从机的IP 我创建的用户时 repl的密码
#是123456
CREATE USER 'repl'@'192.168.119.51' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.119.51';
#192.168.119.52是slave从机的IP 我创建的用户时 repl的密码
#是123456
CREATE USER 'repl'@'192.168.119.52' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.119.52';
//刷新系统权限表的配置
FLUSH PRIVILEGES
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置:
# 开启binlog
log-bin=mysql-bin
server-id=50
# 需要同步的数据库,如果不配置则同步全部数据库
#binlog-do-db=test1
# binlog日志保留的天数,清除超过10天的日志
# 防止日志文件过大,导致磁盘空间不足
expire-logs-days=10
配置完成后,重启mysql:
cd /usr/local/mysql/
./support-files/mysql.server restart

可以通过命令行show master status;查看当前binlog日志的信息(后面有用):

切记!切记!
到此主服务器千万别动,如有改动重启服务登录后再次执行show master status查看主服务的信息,并根据新的信息配置从服务器信息
3,Slave配置
Slave配置相对简单一点。从机肯定也是一台MySQL服务器,所以和Master一样,以192.168.119.51为例,找到/etc/my.cnf配置文件,增加以下配置:
# 不要和其他mysql服务id重复即可
server-id=51
接着使用命令行启动并登录到mysql服务器:
#启动mysql
./support-files/mysql.server start
#登录mysql
./bin/mysql -uroot -p
然后输入密码登录进去。
进入到mysql后,再输入以下命令:
CHANGE MASTER TO
#主机IP
MASTER_HOST='192.168.119.50',
#之前创建的用户账号
MASTER_USER='repl',
#之前创建的用户密码
MASTER_PASSWORD='123456',
#master主机的binlog日志名称
MASTER_LOG_FILE='mysql-bin.000001',
#binlog日志偏移量
MASTER_LOG_POS=156,
#端口
master_port=3306;
还没完,设置完之后需要启动:
# 启动slave服务
start slave;
启动完之后怎么校验是否启动成功呢?使用以下命令:
show slave status\G;
可以看到如下信息(摘取部分关键信息):

可能出现的问题如下:
1,server_id相同问题
查看状态时,可能会出现I/O任务启动失败的情况,即如下错误:

这是因为在MySQL主从结构中,从机上的server_id和主机上的server_id不能相同,我们可以看一下主机上的server_id和从机上的server_id是否相同。
show variables like 'server_id';


为了保持一致这里我们把主机机的server_id改成50,从机的server_id改成51
#此处的数值和my.cnf里设置的一样就行
set global server_id=50;
set global server_id=51;
注意 此时重启时发现这个鬼server_id又变成1了,每次重启又要设置server_id?
修改配置文件,server-id必须放在[mysqld下面],不能放在 [mysqld_safe]后面
vim /etc/my.cnf


2,如果出现server_uuid问题即server_uuid相同时
![]()
show variables like 'server_uuid';
此时只需要删除data目录下的
auto.cnf,重启使MySQL重新生成一个新的server_uuid,否则复制将会异常
不要闲我啰嗦!切记!切记!
主服务器配置信息一旦有变动,再次执行show master status查看主服务的信息,并根据新的信息配置从服务器信息
另一台slave从机配置一样,不再赘述。
4,查看主从复制效果
(1)主数据库创建一张表
CREATE TABLE `user_info` (
`id` int NOT NULL AUTO_INCREMENT,
`user_name` varchar(20) NOT NULL COMMENT '用户名称',
`pass_world` varchar(50) NOT NULL COMMENT '用户密码',
`age` int DEFAULT NULL COMMENT '用户年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
然后插入一条数据
insert into userInfo values (1,"卡夫斯基","123456",15);
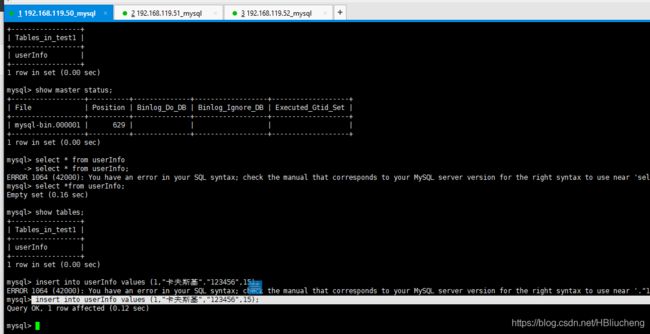
(2)从机192.168.119.51上查看是否新建了表和插入数据

五、读写分离
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
实现的方式有很多,以前我公司是采用AOP的方式,通过方法名判断,方法名中有get、select、query开头的则连接slave,其他的则连接master数据库。
但是通过AOP的方式实现起来代码有点繁琐,有没有什么现成的框架呢,答案是有的。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy两部分组成。
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
读写分离就可以使用ShardingSphere-JDBC实现。
官网 https://shardingsphere.apache.org/
中文官网: https://shardingsphere.apache.org/index_zh.html
中文官网文档https://shardingsphere.apache.org/document/current/cn/overview/

下面演示一下SpringBoot+Mybatis+Mybatis-plus+druid+ShardingSphere-JDBC代码实现。
SpringBoot:2.4.2
druid:1.2.4
mybatis-plus-boot-starter:3.2.0
mybatis-spring-boot-starter:2.1.4
sharding-jdbc-spring-boot-starter:4.1.1
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com</groupId>
<artifactId>mysql_master_slave</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>mysql_master_slave</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-jdbc</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- shardingJDBC-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<!-- druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
application.yml
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
server:
port: 8081
servlet:
context-path: /
spring:
shardingsphere:
datasource:
names: master,slave0,slave1
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.119.50:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: root
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.119.51:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: root
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.119.52:3306/test1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: root
masterslave:
load-balance-algorithm-type: round_robin
name: ms
master-data-source-name: master
slave-data-source-names: slave0,slave1
props:
sql:
show: true
mybatis:
mapper-locations: classpath:mapper/*Mapper.xml
type-aliases-package: com.example.entity
load-balance-algorithm-type是路由策略,round_robin表示轮询策略。
开始测试
启动看到如下信息则说明配置成功

先看查询
控制台信息如下


缺点
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- **从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。**
可能有人会问,有没有事务问题呢?
实际上这个框架已经想到了,我们看回之前的那个截图,有一句话是这样的:

到此读写分离已完成