R分数复现 R-precision评估指标定量 文本生成图像R分数定量实验全流程复现(R-precision)定量评价实验踩坑避坑流程
目录
- 一、R-precision分数简介
- 二、 R-precision-CUB定量实验步骤
- 2.1、下载R-precision代码
- 2.2、分析
- 2.3、配置好文件
- 2.4、更改路径参数
- 2.5、生成RP_data
- 2.6、评估R分数
- 最后
一、R-precision分数简介
R-precision,也叫R分数,其通过对提取的图像和文本特征之间的检索结果进行排序,来衡量文本描述和生成的图像之间的视觉语义相似性。除了生成图像的真实文本描述外,还从数据集中随机抽取其他文本。然后,计算图像特征和每个文本描述的text embedding之间的余弦相似性,并按相似性递减的顺序对文本描述进行排序。如果生成图像的真实文本描述排在前r个内,则相关。
简单举个例子:假设r为3,有一百个文本,其中包括一个真实对应的文本和99个随机取出来的文本,将他们转为text embedding,然后分别与生成的图像计算余弦相似度,然后排序,如果真实文本生成的embedding排在前3位,则认为该图像与文本有相关性。
R-precision表示的是排序后真实文本出现在前r个的概率,越大说明图像与真实文本描述越相关,R-precision越大越好。
二、 R-precision-CUB定量实验步骤
这里我们以DF-GAN在CUB上面的模型定量为例:
2.1、下载R-precision代码
Github:https://github.com/maincarry/R-Precision
CSDN下载:R分数复现 R-precision评估指标定量实验代码
2.2、分析
下载后发现代码工程包括build_RPdata.py、config.py、encoder.py、eval_Rprecision.py、all_texts.txt。
all_text.txt:包括birds的所有描述文本
build_RPdata.py:功能是根据生成的图像建立图像-文本的数据对
config.py:一些参数的设置,用不着,可以不管
encoder.py:图像编码器和文本编码器
eval_Rprecision.py:功能是根据图像-文本的数据对评估图像文本的对齐性

2.3、配置好文件
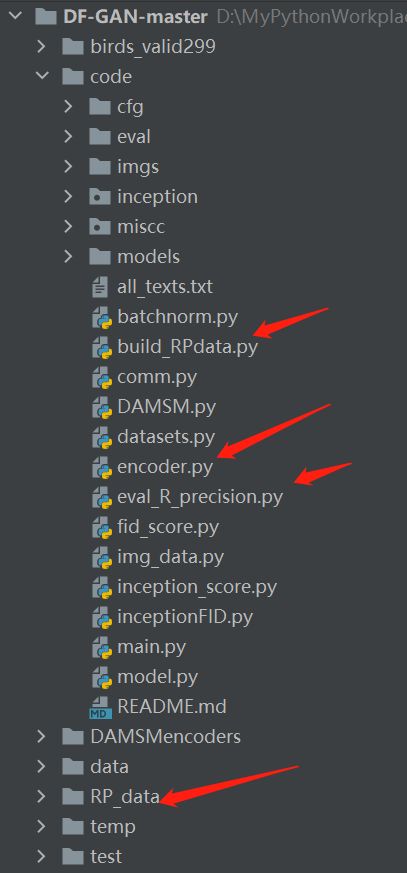
以DF-GAN为例:
将文件放到以上箭头指定的位置(此处只是为了方便这样放,也可以自己单独做文件夹放,只要后面的文件路径你能配好随意放都行)
2.4、更改路径参数
打开build_RPdata.py,找到160~180行,如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Generate RP test data from evaluation output.')
parser.add_argument('-p', dest='path', type=str, help='Path to image directory')
parser.add_argument('-c', dest="cap", default='all_texts.txt',
help='Optional: specify all texts file. Default to all texts in dataset.')
parser.add_argument('-d', dest='out', type=str, help='Output directory', default='./')
parser.add_argument('-t', dest='text', type=str, help='Directory to text data',
default='D:\\MyPythonWorkplace\\DF-GAN-master\\data\\bird\\text\\text')
# default='D:\\AttnGAN-master\\data\\birds\\text')
parser.add_argument('-r, --random', dest='rand', action='store_true',
help='If set, sample is selected randomly instead of sequentially.')
args = parser.parse_args()
# args.p = 'D:\\AttnGAN-master\\models\\netG_epoch_250\\valid\\single\\'
args.p = '..\\test\\valid\\single_580epoch'
# args.out = 'D:\\AttnGAN-master\\R_Precision_attnGAN-master\\RP_data\\'
args.out = '..\\RP_data'
其中需要更改的参数有三个
parser.add_argument('-t', dest='text', type=str, help='Directory to text data',default='D:\\MyPythonWorkplace\\DF-GAN-master\\data\\bird\\text\\text'),这一句是指明数据集文本所在的位置,修改为你放置的地方,如果你按照2.3放置好了文件的话,你可以改成default='..\\data\\bird\\text\\text'args.p = '..\\test\\valid\\single_580epoch',这一句是指明生成的图像的所在位置: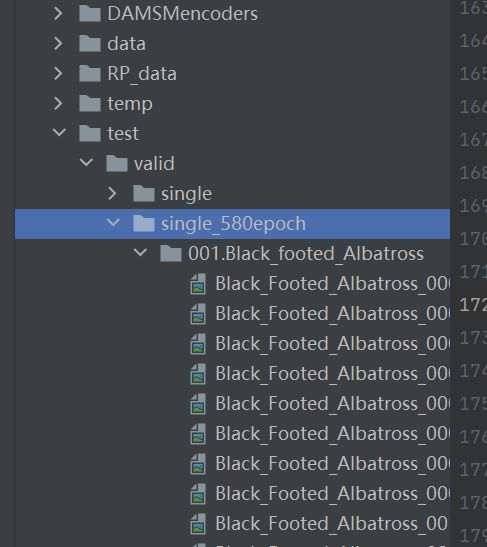
args.out = '..\\RP_data',这一句指明你要输出的图像-文本数据对所在的位置。
打开eval_R_precision.py,找到第306行左右:
args = parse_args()
BATCH_SIZE = 64
args.fake_dir = '..\\RP_data'
args.cap_path = '..\\data\\bird\\captions.pickle'
args.manualSeed = 1900
其中需要更改的参数有两个
- args.fake_dir指明的是RP_data即图像-文本数据对存放的文件路径。
- args.cap_path指明的是数据集captions.pickle包的所在路径。
2.5、生成RP_data
运行build_RPdata.py,生成数据对文件保存到RP_data文件夹中。
如果出现读取文件错误可以更改86行:txt_file = os.path.join(args.text, os.path.basename(dir), "{}.txt".format(fname.split(" ")[0][:-1])),看是不是路径提取时出的错误。
2.6、评估R分数
运行eval_R_precision.py开始评估,等待结束即可,3000份图像-文本数据对的话评估时间大概在7分钟左右。
最后
特别鸣谢赵zewei同学的指导和帮助。
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
个人主页:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言
另外,我们已经建立了微信T2I学习交流群,如果你也是T2I方面的爱好者或研究者可以私信我加入。
如果这篇文章帮助到你很多,希望能不吝打赏我一杯可乐!多加冰哦!