数据分析实战项目--天猫交易数据可视化分析
导语:“学习的价值不在于记住多少,而在于应用多少”,这是笔者两天前浏览博客时看见的一句话,深有感触。相信有不少uu们正处于头绪繁多,却又不知从何下手的状态。想起之前在数据分析中踽踽独行的自己,决定写下这篇文章,希望对你有所启发。本篇文章将结合具体实操案例,一步步和大家一起运用pandas处理一份看似零碎的数据,并用matplotlib和pyecharts做数据可视化,分析其中缘由。
(一)项目背景
天猫订单综合分析
本数据集共收集了发生在一个月内的28010条数据,包含以下:
7个字段说明
- 订单编号:订单编号
- 总金额:订单总金额
- 买家实际支付金额:总金额 - 退款金额(在已付款的情况下)。金额为0(在未付款的情况下)
- 收货地址:各个省份
- 订单创建时间:下单时间
- 订单付款时间:付款时间
- 退款金额:付款后申请退款的金额。如无付过款,退款金额为0
分析目的
- 订单每个环节的转化转化率
- 订单成交的时间(按天)趋势(按实际成交)
- 订单数在地图上的分布
(二)数据预处理
1. 数据预览
用pandas导入存储数据的csv文件,先来观察一下数据长什么样。使用info查看数据相关信息。
import pandas as pd
def data_cleaning():
tmall = pd.read_csv(r'C:\Users\Amand\Desktop\tmall_order_report.csv',encoding = 'utf-8')
#print(tmall.info()) #查看列数据类型
#print(tmall.head(1))
#print(tmall.tail(1))
2. 数据清洗
print(tmall.columns)
tamll = tmall.rename(columns={'收货地址 ': '收货地址', '订单付款时间 ': '订单付款时间'}, inplace=True) #列名去除空格
print(tmall.columns)
tmall['订单创建时间'] = pd.to_datetime(tmall['订单创建时间']) #格式化订单创建时间和付款时间
tmall['订单付款时间'] = pd.to_datetime(tmall['订单付款时间'])
print(tmall.duplicated().sum()) #查找重复值的总数,0,无需处理
print(tmall['订单编号'].is_unique) #判断订单编号是否唯一
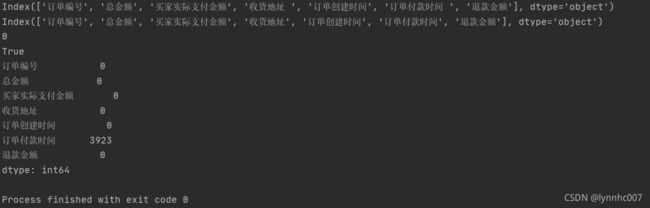
print(tmall.isnull().sum()) #查找缺失,‘订单付款时间’有3923个缺失值,属于正常现象,说明这些单位付过款,无需处理
return tmall #返回处理过后的tmall数据,后续传参“收货地址”和“订单付款时间”这两列名后有空格,需将其去除;数据预览中,注意到“订单创建时间”和“订单付款时间”不是日期格式,在这里将他定义为日期类型格式;查找重复值为0;查找异常值,订单编号都是唯一;缺失值“订单付款时间”有3923个,属于正常缺失,下单但未付款,具有其数据意义,下图是运行结果:
(三)可视化分析
数据探索完了,现在我们进入正题!先导入相关可视化分析包,这里我们用到的是matplotlib和pyecharts,注意:不同版本的包相关方法的导入方式和使用方法(内部参数)是不一样的,动手之前先看看自己的包哪个版本的吧!本次导入的是matplotlib3.4.3和pyecharts1.9.0。
1.日GMV和实际销售额
首先计算出每日GMV,GMV是电商平台的一个说法,即拍下的订单金额,包含付款金额和未付款金额。注意:我们的数据中付款时间是有时间的,不止包含日期,只需取日期单位便可。用pandas的groupby方法,将数据按照“订单创建时间”分组,然后按照“总金额”和“卖家实际支付金额”进行每日GMV和每日实际销售额进行合计。
import matplotlib.pyplot as plt
import pyecharts.options as opts
from pyecharts.charts import Map, Funnel, Page
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
def visible_analyse(tmall): #可视化分析
#1. 每日GMV与实际销售额对比图
#每日GMV
GMV = tmall.groupby(by=tmall['订单创建时间'].dt.date)['总金额'].sum() #dt.date没有时区的时间戳,即只按日期
#每日实际付款金额
real_income = tmall.groupby(by=tmall['订单创建时间'].dt.date)['买家实际支付金额'].sum()
plt.figure(figsize=(20, 8), dpi=80) #设置图大小和像素
x1 = GMV.index.to_list()
y_GMV = GMV.values
y_real_income = real_income.values
plt.plot(x1, y_GMV, 'r',
x1, y_real_income, 'b') #画图
plt.legend(['GMV', '实际销售额']) #标签,这里在画图中尝试使用label但无法显示
plt.title('每日GMV与实际销售额对比图') #表名
plt.xlabel('日期')
plt.ylabel('GMV/实际销售额')
plt.xticks(x1, rotation=40) #设置x坐标数值和倾斜度
plt.grid(axis='both') #网格
for i, j in zip(x1, y_GMV): #给图标数值
plt.text(i, j+5000, '%s'%int(j),)
for m, n in zip(x1, y_real_income):
plt.text(m, n-5000, '%d'%int(n))
plt.show()使用plt.plot()方法,将两条折线绘制在同一图中,方便我们对比查看。运行结果如下图:

2.订单成交的时间(按天)趋势(按实际成交)
#每日下单数量
total_amount = tmall.groupby(by=tmall['订单创建时间'].dt.date)['订单编号'].count()
#每日实付订单数量
df = tmall[tmall['订单付款时间'].notnull()]
total_paid_amount = df.groupby(by=df['订单创建时间'].dt.date)['订单编号'].count()
plt.figure(figsize=(20, 8), dpi=80)
x2 = total_amount.index.to_list()
y1_total_amount = total_amount.values
y2_total_paid_amount = total_paid_amount.values
plt.plot(x2, y1_total_amount, 'r',
x2, y2_total_paid_amount, 'b')
plt.legend(['下单数量', '实付下单数量'])
plt.title('每日下单数量与实际支付订单数对比图')
plt.xlabel('日期')
plt.ylabel('订单数')
plt.xticks(x2, rotation=40)
plt.grid(axis='both')
for i, j in zip(x2, y1_total_amount):
plt.text(i, j+170, '%d'%int(j))
for m, n in zip(x2, y2_total_paid_amount):
plt.text(m, n-70, '%d'%int(n))
plt.show()万变不离其宗,实现方法和GMV-实际销售额一样,下面是运行图:

分析:综合上面两图我们可以看见,2月4号出现局部峰值,5-8号持续下降,10-15号数据平稳,但依旧低迷,15号之后,销售额和订单数出现爆发式上升,以后虽有起伏,但总体维持在销售额万级以上,订单数千级以上的较高水平。原因可能是2月中序之前,大部分企业还未复工,快递并没完全复运,2月中旬过后,企业逐渐复工,才出现爆发式增长。
3. 整体转化率
从字段梳理中可得知用户的行径为:订单创建——订单付款——订单成交——订单全额成交,而转化率的计算方法是:(1)绝对转化率 = 每一环节订单数 / 初始环节订单数(2)相对转化率 = 每一环节订单数 / 上一环节订单数。两种算法有各自合适应用的场景,本次我们采用绝对转化率的计算方法。
由于表的订单编号没有重复值,即表的长度便为总体订单数;付过款的订单数为付款时间不为空的订单数量;成交的订单为付款款的订单中实际支付金额不为0的订单,即没有全部退款;全额到款订单为付过款订单中退款金额为0的订单,由此我们可以一一算出各个环节的订单数。定义一个字典,键为各个环节名称数,值为订单数,将上述环节一一加入字典中,然后将字典转化成数组,键为索引,值为数组元素,并计算转化率,而后生成元组列表,画图。
dict_bills = {}
#下单数
key1 = "下单数"
dict_bills[key1] = len(tmall) #订单无重复值,表的行数即为下单数
#付过款订单数
key2= "付过款的订单数"
df_paid = tmall[tmall["订单付款时间"].notnull()]
dict_bills[key2] = len(df_paid)
#到款订单数
key3 = "到款订单数"
df_moneyarr = df_paid[df_paid["买家实际支付金额"] != 0]
dict_bills[key3] = len(df_moneyarr)
#全额到款订单数
key4 = "全额到款订单数"
df_allarr = df_paid[df_paid["退款金额"] == 0]
dict_bills[key4] = len(df_allarr)
series_bills = pd.Series(dict_bills, name="订单数").to_frame() #将字典转化为series数组列
total_trans_rate = series_bills["订单数"]/series_bills.loc["下单数", "订单数"]*100 #计算转化率,生成series数组列
total_trans_rate_tuple = []
for i in total_trans_rate.items():
total_trans_rate_tuple.append(i) #生成元组列表
funnel = ( #画图
Funnel()
.add(
series_name="总体订单转化率漏斗图",
data_pair=total_trans_rate_tuple,
is_selected=True,
label_opts=opts.LabelOpts(position='inside')
)
.set_series_opts(tooltip_opts=opts.TooltipOpts(formatter='{a}
{b}:{c}%'))
.set_global_opts(title_opts=opts.TitleOpts(title="总体订单转化率漏斗图")
)
)
funnel.render('漏斗图.html')运行结果如图所示:html文件网址是:图片链接:漏斗图
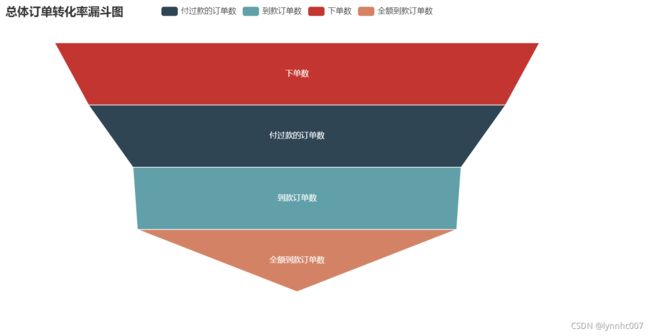 分析:根据TrustData的报告显示,淘宝2015年平时的订单成功率(指提交订单支付的支付成功率)为97.4%。此次分析转化率情况:付款成功率为85.99%,低于行业水平的97.4%,实际成交和全额成交的转化率分别为67.67%和65.83%。若以此作为标准,本次分析当中的付款转化率85.994%低于预期标准,实际成交及全额成交的环节转化率甚至不到7成。属于比较低的水平。
分析:根据TrustData的报告显示,淘宝2015年平时的订单成功率(指提交订单支付的支付成功率)为97.4%。此次分析转化率情况:付款成功率为85.99%,低于行业水平的97.4%,实际成交和全额成交的转化率分别为67.67%和65.83%。若以此作为标准,本次分析当中的付款转化率85.994%低于预期标准,实际成交及全额成交的环节转化率甚至不到7成。属于比较低的水平。
4. 地区分布图
用groupby方法计算各省订单量,处理各省名字段
total_amount_prov = tmall.groupby(by=['收货地址'])['订单编号'].count()
strip_index = []
for region in total_amount_prov.index:
if region == "内蒙古自治区" or region == '黑龙江省':
region = region[:3]
strip_index.append(region)
else:
region = region[:2]
strip_index.append(region)
total_amount_prov.index = strip_index
total_amount_prov_tuple = []
for i in total_amount_prov.items():
total_amount_prov_tuple.append(i)
map = (
Map()
.add(series_name='订单数', data_pair=total_amount_prov_tuple, maptype='china' )
.set_global_opts(
title_opts=opts.TitleOpts(title="各省下单数地理分布图"),
visualmap_opts=opts.VisualMapOpts(max_=3500,
is_piecewise=True,
pieces=[
{"max": 3000, "min": 2000, "label": ">=2000", "color": "#B40404"},
{"max": 1999, "min": 1000, "label": "1000-1999", "color": "#DF0101"},
{"max": 999, "min": 500, "label": "500-999", "color": "#F78181"},
{"max": 499, "min": 200, "label": "200-499", "color": "#F5A9A9"},
{"max": 199, "min": 0, "label": "0-199", "color": "#FFFFCC"},
]
)
)
)
map.render('中国地图.html')
运行结果如图:图片连接:地域图

分析:沿海和经济发达地区订单数比中西部,西部地区多,上海的订单数最多,达3353
对于此种情况:继续保持东部地区订单量,大力发掘中西部,完善物流系统,尽量做到偏远地区包邮,对于西部的新客户,开展优惠活动等