天猫订单数据综合分析
一、项目介绍
本项目通过对天猫成交数据的探索,通过python对数据预处理,整个项目分为项目目的的确定、数据的预处理、对数据的分析和项目总结这五个部分。(本项目参考凹凸数据)
二、项目流程
项目目的
从结果指标出发确定目标,通过过程指标定位问题,提出合理建议
数据来源
本数据集来源于和鲸社区
一共收录了发生在一个月内的28010条数据
数据字段:'订单编号', '总金额', '买家实际支付金额', '收货地址 ', '订单创建时间', '订单付款时间 ', '退款金额'共7个字段
-
买家实际支付金额:最终成交金额,分为已付款和未付款两种情况
-
已付款情况下:买家实际支付金额 = 总金额 - 退款金额
-
未付款情况下:买家实际支付金额 = 0
-
-
收货地址:买家的收货地址,记录维度为省市,共记录了31个省市
-
订单创建时间:2020年2月1日 至 2020年2月29日
-
订单付款时间:2020年2月1日 至 2020年3月1日
-
退款金额:付款后申请退款的金额,如果没有退款,退款金额为0
指标维度梳理
通过上面的字段梳理可知,除了成交金额作为结果指标外,还有一系列的过程指标,那么就需要对指标间的关系做逻辑梳理。
这里我们引入电商的分析中最经典的公式:销售额 = UV * 转化率 * 客单价
-
指标梳理:
-
UV:一般指独立访客,在本数据集中,没有客户id作为UV数据,但我们可以把订单创建数量作为UV的数据
-
转化率:转化流程为订单创建 -> 订单付款 -> 订单成交 -> 订单全额成交
-
客单价:平均每单的售价,在本数据集当中,亦可以理解为各个产品的销量情况
-
-
维度梳理:
-
时间维度:(周/日)订单创建/付款时间
-
地域:各省市
-
产品:假设每一种金额对应唯一的产品时,总金额便可以作为产品品类的标识
-
数据预处理
主要是运用python预处理。
导入模块

读取数据

整体观察
重复值处理

缺失值处理

字段处理

日期格式提取

结果指标
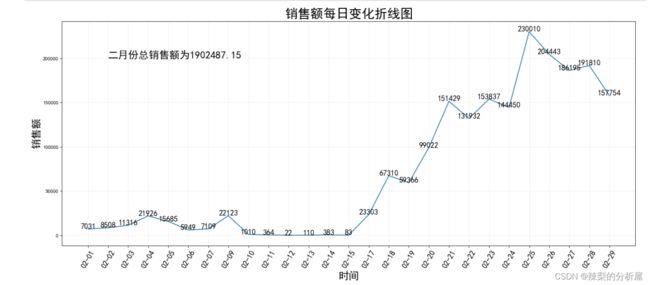
#销售额图df_true_money=df.groupby('订单创建月日')['买家实际支付金额'].sum()x1=df_true_money.indexy1=df_true_money.valuesdf_true_money_sum=df['买家实际支付金额'].sum()picture_size=plt.figure(figsize=(20,8),dpi=80)#设置绘图大小plt.text(1, 200000, '二月份总销售额为{}'.format(df_true_money_sum),fontsize=20)#不能将图表中的内容移动至图片大小设置前面plt.rcParams['font.sans-serif']=['SimHei']#设置字体样式plt.xticks(range(len(x1)),x1,rotation=60,size=15)plt.xlabel('时间',size=20)plt.ylabel('销售额',size=20)plt.title('销售额每日变化折线图',size=25)for i,j in zip(x1,y1): plt.text(i,j+70,'%s'%int(j),ha='center',size=15)#为折线图将各坐标点标上数值plt.plot(x1,y1)plt.grid(alpha=0.2)plt.show()
-
整体的销售额为190万
-
4号出现局部峰值,5-8号持续型下降,每日成交额低于万级水平
-
10-16日共一周时间的销售额几乎低于千级,需要特别留意数据的真实性
-
17日后出现持续型增长,25日出现本月峰值
但仅凭上面的信息并不足以支撑决策,因此我们对案例增加些背景假设:
-
本月的销售额目标是230万
-
除10-16日之外,所有数据的采集均没有错误
-
10-16日的实际日均销售额为2万
在增加假设后,我们可以得知本月的真实销售额为200万,距离目标还差30万。接下来将从公式中的三个指标来拆解是什么环节出现问题,应该如何提升销售额。
查看过程指标,进一步锁定问题
用户行为路径整体转化率
从字段梳理中可以得知用户行为路径为:订单创建 -> 订单付款 -> 订单成交 -> 订单全额成交。而转化率的计算方法有两种:
-
绝对转化率:每一个环节的订单数除以初始环节的订单数
-
相对转化率:每一个环节的订单数除以上一个环节的订单数
dict_convs = dict()key_1 = '总订单数'dict_convs[key_1] = len(df) #总订单key_2 = '付款订单数'df_payed = df[df['订单付款时间'].notnull()] # 付款时间不为空的,表示付过款dict_convs[key_2] = len(df_payed)key_3 = '到款订单数'# 买家实际支付金额:总金额 - 退款金额(在已付款的情况下)# 买家实际支付金额不为0的,说明订单商家收到过款df_trans = df_payed[df_payed['买家实际支付金额'] != 0]dict_convs[key_3] = len(df_trans)key_4 = '全额到款订单数'# 在付款的订单中,退款金额为0的,说明没有退款,表示全额收款df_trans_full = df_payed[df_payed['退款金额'] == 0]dict_convs[key_4] = len(df_trans_full)df_convs = pd.Series(dict_convs, name='订单数').to_frame()df_convs['总体转化率']=df_convs['订单数'].apply(lambda x: round(x*100/df_convs.iloc[0,0],3))name = '总体转化率'funnel = Funnel().add( series_name = name, data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ], is_selected = True, label_opts = opts.LabelOpts(position = 'inside',formatter='{b}:{c}%') )funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}
{b}:{c}%'))funnel.set_global_opts( title_opts = opts.TitleOpts(title = name) ) funnel.render_notebook()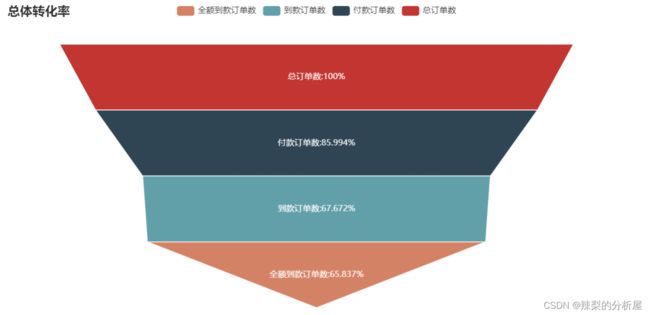
根据TrustData的报告显示,淘宝平时的订单成功率(指提交订单支付的支付成功率)为97.4%[2]。若以此作为标准,本次分析当中的付款转化率85.99%低于预期标准,实际成交及全额成交的环节转化率甚至不到7成。属于比较低的水平。
#5.制作漏斗图picture_size=plt.figure(figsize=(20,8),dpi=80)#设置绘图大小plt.rcParams['font.sans-serif'] = ['SimHei']#设置字体样式width=0.55#矩形宽度x0=np.array(df_convs['单一环节转化率'])#数据labels=['总订单数','付款订单数','到款订单数','全额到款订单数']#标签N=x0.size#获取数据长度max_value = x0.max()#获取数据最大值x = x0*np.eye(N)#形成1*4矩阵blank= np.array((x0.max()-x0)/2) # 占位y = np.arange(N-1,-1,-1) # 倒转y轴 [3,2,1,0]ax = picture_size.add_subplot(111)#绘制条幅zeros = np.zeros(N)#形成用0填充的数组,长度为Nalpha_step = (1-0.3)/(N-1)for i in range(N-1): ax.barh(y,x[i],width,tick_label=labels, color='cornflowerblue',alpha=0.3+alpha_step*i,left=blank)ax.barh(y,x[N-1],width,tick_label=labels, color='crimson',alpha=0.3+alpha_step*(N-1),left=blank) #绘制最后一层的条幅#绘制边线rightblank = np.array([i+j for i,j in zip(blank,x0)])ax.plot(blank,y,'crimson',alpha=0.7)ax.plot(rightblank,y,'crimson',alpha=0.7)#绘制转换率标签x1=np.array(df_convs['订单数'])transform = ['%.2f%%'%((x1[i+1]/x1[i])*100) for i in range(N-1)]l = [(max_value/2,i) for i in range(N-2,-1,-1)] #for a,b in zip(transform,l): offsetbox = TextArea(a, minimumdescent=False) ab = AnnotationBbox(offsetbox, b, xybox=(0, 40), boxcoords="offset points", arrowprops=dict(arrowstyle="->")) ax.add_artist(ab)ax.set_xticks([0,max_value])ax.set_yticks(y)plt.title('各环节转化率图',size=25)plt.show()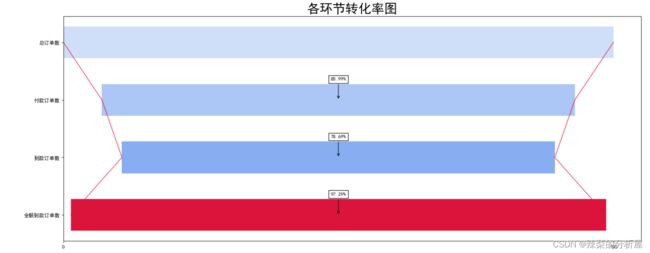
由各环节转化率可看到,全额付款相对于上一环节转化率达到97.29%,而付款订单数和到款订单数相对于上一环节的转化率的相对较低,重点关注付款订单数和到款订单数的转化。
#实际转化率随时间变化折线图df_day=df.groupby(by=['订单创建月日']).agg( 订单创建数=('订单付款时间', 'count'), 订单成交数=('成交情况', 'sum'))df_day['实际成交转化率']=round(df_day['订单成交数']/df_day['订单创建数'],2)df_dayx3=df_day.indexy3=df_day['实际成交转化率'].values# df_order_sum=df.shape[0]picture_size=plt.figure(figsize=(25,8),dpi=80)#设置绘图大小# plt.text(1, 3000, '二月份总订单量为{}'.format(df_order_sum),fontsize=20)plt.rcParams['font.sans-serif']=['SimHei']#设置字体样式plt.xticks(range(len(x3)),x3,rotation=60,size=15)#设置x轴坐标plt.xlabel('时间',size=20)plt.ylabel('转化率',size=20)plt.title('订单成交转化率每日变化折线图',size=25)for i,j in zip(x3,y3): plt.text(i,j+0.01,'%s'%j,ha='center',size=15)#为折线图将各坐标点标上数值plt.plot(x3,y3) plt.grid(alpha=0.2)plt.show()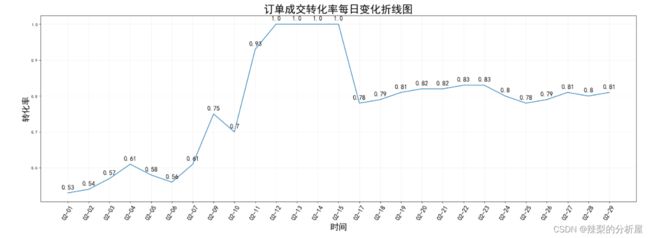
忽略2月10号到2月16号,可以看到转化率在2月6号出现明显上升趋势,可能是疫情稳定,订单成交开始回暖,2月17号在0.8附近波动,2月23号转化率出现明显下移。
订单量增长情况
#订单量折线图df_order_num=df.groupby('订单创建月日')['订单编号'].count()x2=df_order_num.indexy2=df_order_num.valuesdf_order_sum=df.shape[0]picture_size=plt.figure(figsize=(20,8),dpi=80)#设置绘图大小plt.text(1, 3000, '二月份总订单量为{}'.format(df_order_sum),fontsize=20)plt.rcParams['font.sans-serif']=['SimHei']#设置字体样式plt.xticks(range(len(x2)),x2,rotation=60,size=15)#设置x轴坐标plt.xlabel('时间',size=20)plt.ylabel('订单量',size=20)plt.title('订单量每日变化折线图',size=25)for i,j in zip(x2,y2): plt.text(i,j+70,'%s'%j,ha='center',size=15)#为折线图将各坐标点标上数值plt.plot(x2,y2) plt.grid(alpha=0.2)plt.show()
按照现有的转化率情况进行估算,10-16日的日均订单创建量约为167+(190/200=2.8/x),即2月的整体订单创建数为2万9千左右。在转化率及客单价均不变的情况下,订单创建数至少要增加多4k才能达到目标值。
现在假设消费额作为商品类别,查看各品类数据
品类数据占比情况
df1=df[df['买家实际支付金额']>0]hot_=pd.DataFrame({ '销量':df1['总金额'].value_counts(), '全额付款销量':df1[df1['买家实际支付金额']==df1['总金额']]['总金额'].value_counts()}).sort_values(by='销量',ascending=False)hot_['总销量占比(%)']=hot_['销量'].apply(lambda x : round((x/hot_['销量'].sum())*100,2))hot_['销售额']=df1.groupby(by='总金额')['买家实际支付金额'].sum()hot_['销售额占比(%)']=hot_['销售额'].apply(lambda x : round((x/hot_['销售额'].sum())*100,2))print(f'{"-"*20}热卖前20{"-"*20}')print(hot_.head(20))plt.figure(figsize=(8, 6),dpi=160)# 将销售量前10之外的品类归为其他a=hot_.iloc[10:].sum().to_frame('其他').unstack().unstack()hot_=pd.concat([hot_.head(10), a])# 色板color=sns.color_palette('hls',11)# 画图plt.pie(hot_['总销量占比(%)'], autopct='%3.1f%%', labels=hot_.index, startangle=45,colors=color)plt.title('各品类销量情况')plt.show()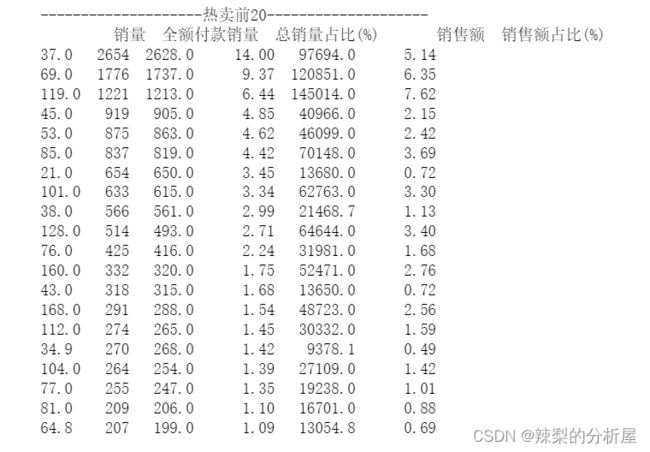
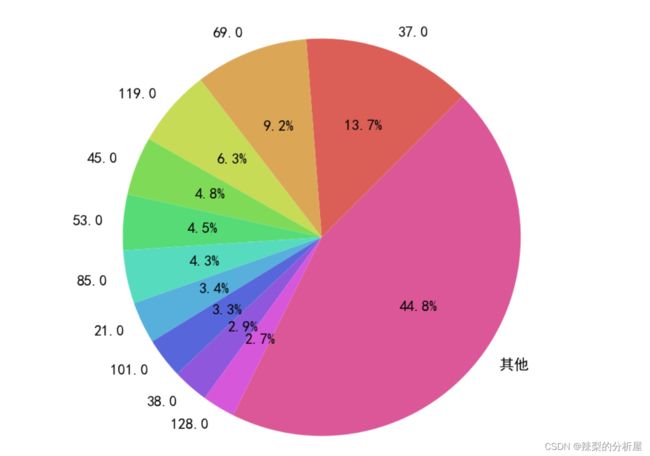
销量前10的产品销量已经占到了总销量的55%。在分析这类榜单类或者占比类的图表时,以下信息非常关键:
-
整体排行:是否有哪些产品排在前列/没有排在前列是出乎意料的事
-
趋势:销量排行变化情况,什么产品增长最快,什么产品表现平庸,什么产品开始下滑
-
产品布局:
-
走量类的产品销量是否多于品牌类产品
-
同一产品线的高中低端产品的销量分布情况,探究客户的消费需求偏向。
-
查看各省市的销售额情况
各省市订单分布图#对省市地域名进行处理,(列如将浙江省的‘省’去掉)df_province=[]for i in df['收货地址']: df_province.append(i)for i in df_province: if i[2:3]=='省'or i[3:4]=='省': if len(i)==3: df_province[df_province.index(i)] =i[0:2] if len(i)==4: df_province[df_province.index(i)] = i[0:3] if i=='内蒙古自治区': df_province[df_province.index(i)] = '内蒙古' if i=='广西壮族自治区': df_province[df_province.index(i)] = '广西' if i=='新疆维吾尔自治区': df_province[df_province.index(i)] = '新疆' if i=='宁夏回族自治区': df_province[df_province.index(i)] = '宁夏' if i=='西藏自治区': df_province[df_province.index(i)] = '西藏'df['收货地址']=df_provincedf.head(10)df_province_order=df.groupby('收货地址')['订单编号'].count().sort_values(ascending=False)province=[]for i in df_province_order.index: province.append(i)data=[]for i in df_province_order.values: n=int(i) data.append(n)c=[list(z) for z in zip(province,data)]c = ( Map() .add("",c, "china",is_map_symbol_show=False) .set_global_opts( title_opts=opts.TitleOpts(title="各省市订单分布"), visualmap_opts=opts.VisualMapOpts(max_=4000, ) ) )c.render_notebook()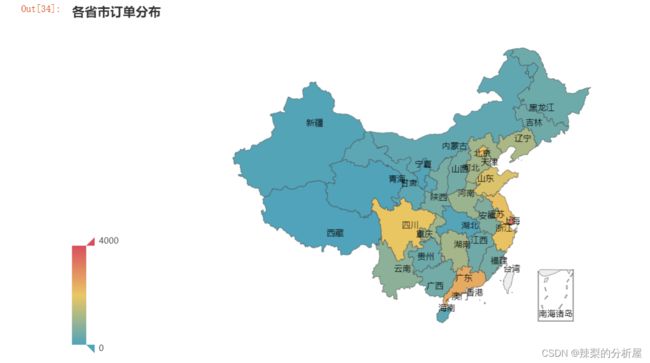
从图及数据可以得知,销售额前5分别为上海、北京、江苏省、广东省、浙江省
重点城市各项指标变化情况
# 找到有实际成交的所有行df['成交情况']=0df.loc[df[df['买家实际支付金额']>0].index.to_list(),'成交情况']=1df.loc[df[df['买家实际支付金额']==df['总金额']].index.to_list(),'全价成交']=1# 分组求和df_=df.groupby(by=['收货地址',pd.Grouper(key='订单付款时间',freq='W')]).agg( 订单创建数=('订单创建时间', 'count'), 订单成交数=('成交情况', 'sum'))df_time=df.groupby(pd.Grouper(key='订单付款时间',freq='W')).agg( 订单创建数=('订单创建时间', 'count'), 订单成交数=('成交情况', 'sum'))df_time['实际成交转化率']=round(df_time['订单成交数']/df_time['订单创建数'],2)df_head3=df_.loc[['上海','广东','北京','江苏','浙江']]# 求转化率df_head3['实际成交转化率']=round(df_head3['订单成交数']/df_head3['订单创建数'],2)print(f'{"-" * 15}销量前5的省市订单创建量量情况{"-" * 15}
')print(df_head3['订单创建数'].unstack()) print(f'{"-" * 15}整体转化率情况{"-" * 15}
')print(df_time['实际成交转化率']) print(f'
{"-" * 15}销量前5的省市的转化率情况{"-" * 15}
')print(df_head3['实际成交转化率'].unstack()) 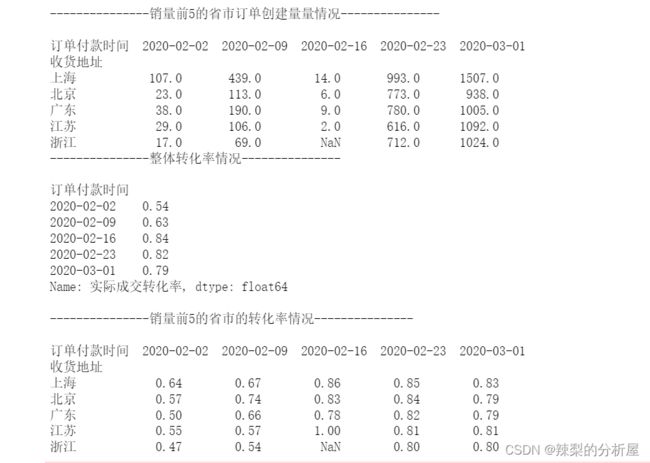
-
在春节过后,疫情最为严重的那段时间,每座城市的订单创建数及最终成交的转化率都是非常低,几乎是每创建两个订单,就有一个订单被退回。而在疫情逐渐明朗后,各项指标均有回升,但依然低于标准值97%。
-
上海的订单创建数及实际成交数都是最多的,转化率的表现也是最好的,因此作为标杆。
-
北京及广东是重点区域。两个区域是除上海之外销量最多的,但转化率基本低于平均值,特别是广东,虽订单创建量排名第二,但销售额却排名第四。
-
江苏和浙江为次重要区域。两个区域虽订单创建量相对较低,但转化率接近均值,销售额情况也较为乐观,江苏的销售额甚至高于广东。
结合产品维度交叉分析
df_food=df[(df['收货地址'].isin(['北京','上海','广东']))&(df['订单创建时间']>'2020-02-16')]df_food['成交情况']=0df_food.loc[df_food[df_food['买家实际支付金额']>0].index.to_list(),'成交情况']=1df_food_=df_food.groupby(by=['收货地址','总金额']).agg( 订单创建数=('订单创建时间', 'count'), 订单成交数=('成交情况', 'sum'))# 筛选每个省市的销量前5df_food1=df_food_.reset_index().groupby('收货地址').apply(lambda x: x.nlargest(5,'订单创建数',keep='all')).set_index(['收货地址','总金额'])# 求转化率df_food1['实际成交转化率']=round(df_food1['订单成交数']/df_food1['订单创建数'],2)print(f'{"-" * 15}重点省市销量前5产品的订单创建量量情况{"-" * 15}
')print(df_food1['订单创建数'].unstack()) print(f'
{"-" * 15}销量前5的省市的转化率情况{"-" * 15}
')print(df_food1['实际成交转化率'].unstack())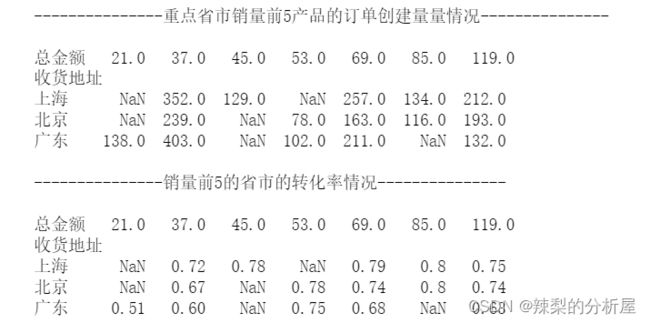
对照我们的标杆上海区域,为北京、广东两个区域的不同产品提出不同的优化目标,例如:
北京:
-
针对37产品:在价格不变的情况下,提升10个订单创建数,成交转化率提升至70%
广东:
-
针对69产品:在价格不变的情况下,提升21个订单创建数,提升成交转化率至75%
结论
这次项目结合python,对数据拆解,初窥数据分析,新人博主,还有做得不对的地方还望指出