Python机器学习基础教程——鸢尾花分类
Python机器学习基础教程——鸢尾花分类
-
- 初识数据
- 训练数据与测试数据
- 观察数据—数据可视化
- 模型的建立与评估——K近邻算法
她还有一些鸢尾花的测量数据,这些花之前已经被植物学专家鉴定为属于 setosa、versicolor 或 virginica 三个品种之一。对于这些测量数据,她可以确定每朵鸢尾花所属的品种。我们假设这位植物学爱好者在野外只会遇到这三种鸢尾花。我们的目标是构建一个机器学习模型,可以从这些已知品种的鸢尾花测量数据中进行学习,从而能够预测新鸢尾花的品种。因为我们有已知品种的鸢尾花的测量数据,所以这是一个 监督学习问题。在这个问题中,我们要在多个选项中预测其中一个(鸢尾花的品种)。这是一个 分类(classification)问题的示例。可能的输出(鸢尾花的不同品种)叫作类别(class)。数据集中的每朵鸢尾花都属于三个类别之一,所以这是一个 三分类问题。
初识数据
from sklearn.datasets import load_iris
iris_dataset=load_iris()
iris_dataset.keys()
dict_keys([‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
分别查看每个键下数据类型:
iris_dataset[‘filename’]
‘C:\Users\DELL\Anaconda3\lib\site-packages\sklearn\datasets\data\iris.csv’
发现‘filename’键对应的值为文件存放地点,‘DESCR’键对应的值为数据简要说明,‘target’和‘target_names’分别对应的为花品种编号和花名,'feature_names‘为花的特征名,每朵花的具体特征存放在‘data’中。
iris_dataset[‘target’].shape
(150,)
iris_dataset[‘data’].shape
(150, 4)
可以看出,数组中包含 150 朵不同的花的测量数据。前面说过,机器学习中的个体叫作**样本**(sample),其属性叫作**特征**(feature)。 data 数组的形状(shape)是**样本数**乘以**特征数**。这是 scikit-learn 中的约定,你的数据形状应始终遵循这个约定。下面给出前 5 个样本的特征数值:
iris_dataset[‘data’][:5]
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2]])
训练数据与测试数据
scikit-learn 中的 train_test_split 函数可以打乱数据集并进行拆分。这个函数将 75% 的行数据及对应标签作为训练集,剩下 25% 的数据及其标签作为测试集。训练集与测试集的分配比例可以是随意的,但使用 25% 的数据作为测试集是很好的经验法则。
from sklearn.model_selection import train_test_split
X_train,X_test,Y_tarin,Y_test=train_test_split(iris_dataset[‘data’],iris_dataset[‘target’],random_state=0)
X_train.shape
(112, 4)
X_test.shape
(38, 4)
X_train,X_test, y_train, y_test =train_test_split(X,y,test_size, random_state)
test_size 若在0~1之间,为测试集样本数目与原始样本数目之比;若为整数,则是测试集样本的数目。
观察数据—数据可视化
pd.plotting.scatter_matrix
from pandas.plotting import scatter_matrix
import pandas as pd
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
iris_data_df = pd.DataFrame(X_train,columns=iris_dataset.feature_names)
scatter = pd.plotting.scatter_matrix(iris_data_df,c=y_train,figsize=(15,15),marker=‘o’, hist_kwds={‘bins’:20},s=60,alpha=0.8)
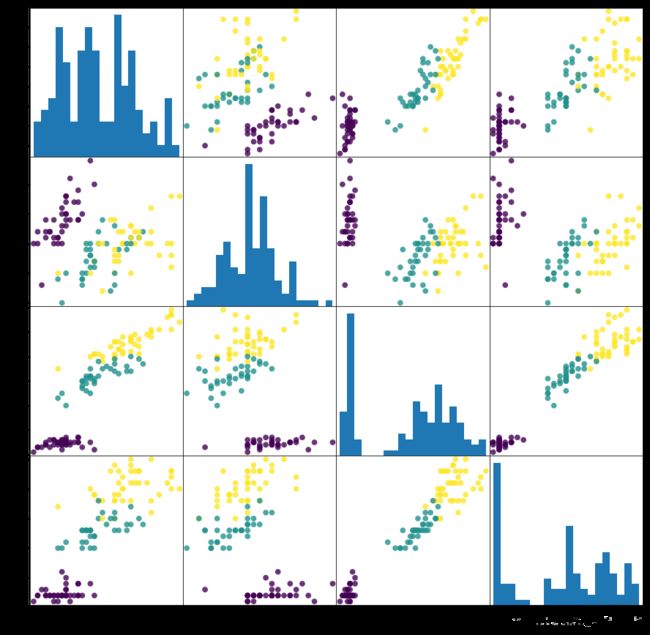
从图中可以看出,利用花瓣和花萼的测量数据基本可以将三个类别区分开。这说明机器学习模型很可能可以学会区分它们。
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15,15), marker=‘0’, hist_kwds={‘bins’:50},s=60,alpha=.8, cmap=mglearn.cm3)
1、pd.scatter_matrix若不可用。
用pd.plotting.scatter_matrix替换掉pd.scatter_matrix即可。
一: dataframe:iris_dataframe 按行取数据
二: c=y_train 颜色,用不同着色度区分不同种类
三:figsize=(15,15) 图像区域大小,英寸为单位
四:marker=‘0’ 点的形状,0是圆,1是¥
五: hist_kwds={‘bins’:50} 对角线上直方图的参数元组
六:s=60 描出点的大小
七:alpha=.8 图像透明度,一般取(0,1]
八:cmap=mglearn.cm3 mylearn实用函数库,主要对图进行一些美化等私有功能,可见https://github.com/YifengChu/introduction_to_ml_with_python
sns.pairplot
y_dataframetrain=pd.DataFrame(y_train,columns=[‘target’])
test=pd.concat([iris_data_df,y_dataframetrain],axis=1)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
0 5.9 3.0 4.2 1.5 1
1 5.8 2.6 4.0 1.2 1
2 6.8 3.0 5.5 2.1 2
3 4.7 3.2 1.3 0.2 0
4 6.9 3.1 5.1 2.3 2
gr=sns.pairplot(test,hue=‘target’,markers=‘o’,kind=‘scatter’,diag_kind=‘hist’,vars=[‘sepal length (cm)’,‘sepal width (cm)’,‘petal length (cm)’,‘petal width (cm)’])

seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind=‘scatter’, diag_kind=‘hist’, markers=None, size=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None)
数据指定
vars : 与data使用,否则使用data的全部变量。参数类型:numeric类型的变量list。
{x, y}_vars : 与data使用,否则使用data的全部变量。参数类型:numeric类型的变量list。
dropna : 是否剔除缺失值。参数类型:boolean, optional
特殊参数
kind : {‘scatter’, ‘reg’}, optional Kind of plot for the non-identity relationships.
diag_kind : {‘hist’, ‘kde’}, optional。Kind of plot for the diagonal subplots.
基础参数
size : 默认 6,图的尺度大小(正方形)。参数类型:numeric
hue : 使用指定变量为分类变量画图。参数类型:string (变量名)
hue_order : list of strings Order for the levels of the hue variable in the palette
palette : 调色板颜色
markers : 使用不同的形状。参数类型:list
aspect : scalar, optional。Aspect * size gives the width (in inches) of each facet.
{plot, diag, grid}_kws : 指定其他参数。参数类型:dicts
模型的建立与评估——K近邻算法
k 近邻算法中 k 的含义是,我们可以考虑训练集中与新数据点最近的任意 k 个邻居(比如说,距离最近的 3 个或 5 个邻居),而不是只考虑最近的那一个。然后,我们可以用这些邻居中数量最多的类别做出预测。
sklearn.neighbors. KNeighborsClassifier ( n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=1, **kwargs )
参数
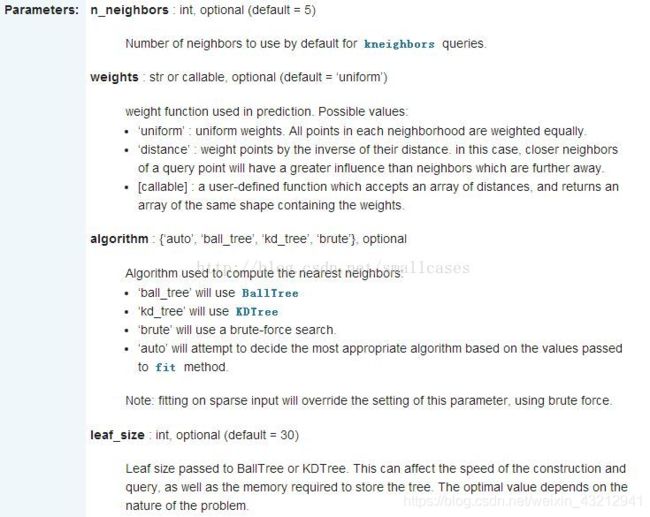

n_neighbors: 选择最邻近点的数目k
weights: 邻近点的计算权重值,uniform代表各个点权重值相等
algorithm: 寻找最邻近点使用的算法
leaf_size: 传递给BallTree或kTree的叶子大小,这会影响构造和查询的速度,以及存储树所需的内存。
p: Minkowski度量的指数参数。p = 1 代表使用曼哈顿距离 (l1),p = 2 代表使用欧几里得距离(l2),
metric: 距离度量,点之间距离的计算方法。
metric_params: 额外的关键字度量函数。
n_jobs: 为邻近点搜索运行的并行作业数。
Methods
fit(X, y)
Fit the model using X as training data and y as target values
get_params([deep])
Get parameters for this estimator.
kneighbors([X, n_neighbors, return_distance])
Finds the K-neighbors of a point.
kneighbors_graph([X, n_neighbors, mode])
Computes the (weighted) graph of k-Neighbors for points in X
predict(X)
Predict the class labels for the provided data.
predict_proba(X)
Return probability estimates for the test data X.
score(X, y[, sample_weight])
Return the mean accuracy on the given test data and labels.
**set_params(params)
Set the parameters of this estimator.
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier.fit
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
KNeighborsClassifier(algorithm=‘auto’, leaf_size=30, metric=‘minkowski’, metric_params=None, n_jobs=None, n_neighbors=1, p=2,weights=‘uniform’)
y_pred=knn.predict(X_test)
y_pred
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1,
0, 0, 2, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 2])
iris_dataset[‘target_names’][y_pred] knn.score(X_test,y_test)
array([‘virginica’, ‘versicolor’, ‘setosa’, ‘virginica’, ‘setosa’,
‘virginica’, ‘setosa’, ‘versicolor’, ‘versicolor’, ‘versicolor’,
‘virginica’, ‘versicolor’, ‘versicolor’, ‘versicolor’,
‘versicolor’, ‘setosa’, ‘versicolor’, ‘versicolor’, ‘setosa’,
‘setosa’, ‘virginica’, ‘versicolor’, ‘setosa’, ‘setosa’,
‘virginica’, ‘setosa’, ‘setosa’, ‘versicolor’, ‘versicolor’,
‘setosa’, ‘virginica’, ‘versicolor’, ‘setosa’, ‘virginica’,
‘virginica’, ‘versicolor’, ‘setosa’, ‘virginica’], dtype=’
0.9736842105263158