Python数据分析入门笔记9——数据预处理案例综合练习(男篮女篮运动员)
系列文章目录
Python数据分析入门笔记1——学习前的准备
Python数据分析入门笔记2——pandas数据读取
Python数据分析入门笔记3——数据预处理之缺失值
Python数据分析入门笔记4——数据预处理之重复值
Python数据分析入门笔记5——数据预处理之异常值
Python数据分析入门笔记6——数据清理案例练习
Python数据分析入门笔记7——数据集成、变换与规约
Python数据分析入门笔记8——Pandas处理日期时间类型数据
Python数据分析入门笔记
- 系列文章目录
- 前言
-
- 预备知识:
- 一、任务说明
-
- 1. 数据文件下载:
- 2. 任务要求:
- 二、任务分析与预处理
-
- 1. 数据分析流程
- 2. 数据获取与初步处理
-
- (1)文件的读取——read_csv()和read_excel()
- (2)文件的合并——merge()
- (3)数据的筛选
- 3. 数据清理
-
- (1)检测与处理重复值——duplicated()和drop_duplicates()
- (2)处理缺失值,统一单位——fillna()
- (3)检测与处理异常值——3σ和箱型图
- 三、 任务执行:分析运动员数据
-
- 1. 计算中国男篮、女篮运动员的平均身高与平均体重,保留一位小数
- 2. 分析中国篮球运动员的年龄分布
- 3. 计算中国篮球运动员的体质指数
- 总结
前言
前面学过了pandas数据清理、数据集成、数据变换和数据规约相关知识,今天用一个运动员基本信息的案例来练习删除重复值、填充缺失值、确认异常值、分组与聚合、轴向旋转和降采样等操作,以达到清理数据、整合数据、减少数据量、变换数据形式的目的。
预备知识:
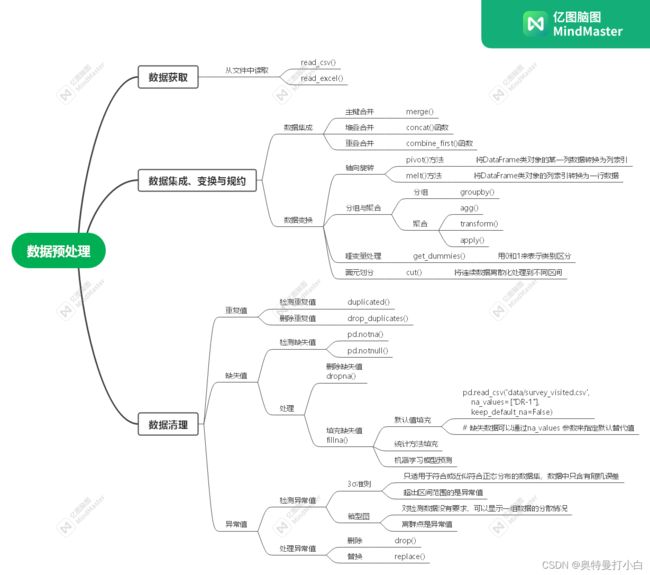
一、任务说明
1. 数据文件下载:
运动员信息采集01.csv
运动员信息采集02.xlsx
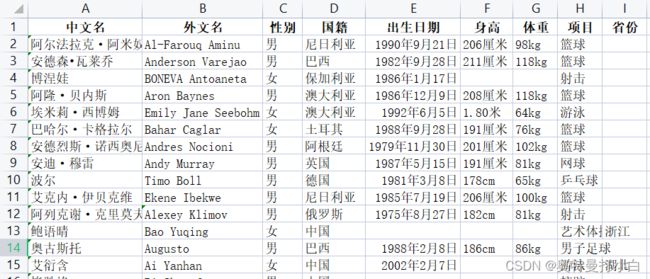
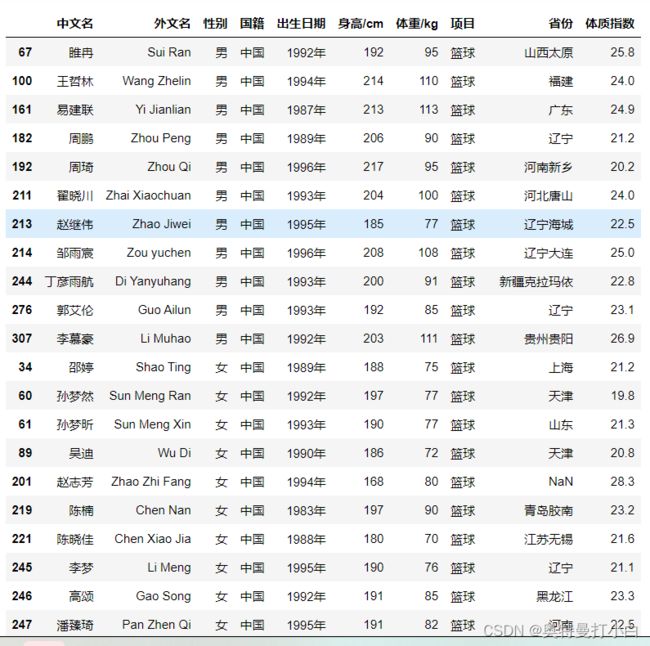
运动员信息采集01.csv文件部分内容如下:

运动员信息采集02.xlsx
2. 任务要求:
(1)计算中国男篮、女篮运动员的平均身高与平均体重。
(2)分析中国篮球运动员的年龄分布
(3)计算中国篮球运动员的体质指数
二、任务分析与预处理
1. 数据分析流程
在进行数据分析之前,必须事先对数据进行预处理。
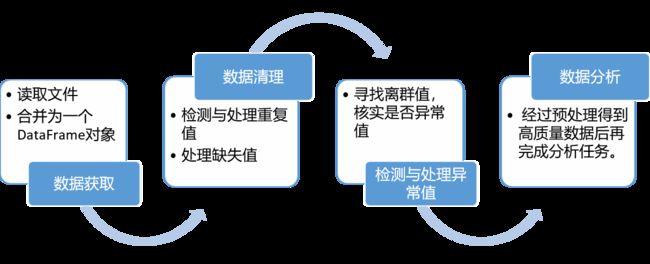
2. 数据获取与初步处理
(1)文件的读取——read_csv()和read_excel()
首先读取这两个文件,由于文件中含有中文,因此读取csv文件时需要设置编码为‘gbk’。
代码如下:
import pandas as pd
file_one=pd.read_csv('data/运动员信息采集01.csv',encoding='gbk')
file_two=pd.read_excel('data/运动员信息采集02.xlsx')
- 报错说明——若读取csv的时候未设置中文编码,会报如下错误:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd6 in position 0: invalid continuation byte - 报错说明——若读取excel的时候,设置了encoding,会报如下错误:
TypeError:read_excel() got an unexpected keyword argument ‘encoding’ - 一点疑问——读取中文必须gbk吗?为什么utf-8也不识别?read_excel方法中原来是有encoding参数的,取消掉以后如果再遇到编码问题要如何处理?
(2)文件的合并——merge()
首先观察两个文件中的列索引,万幸的是,两张表中的列索引完全一致,也就是属性方面是匹配的,因此,我们可以直接进入数据集成环节。
这个案例中的合并类似于两个班级表的合并,因此,主键合并可直接用merge方法,选用outer全外连接的方式,保留两张表中所有原始数据。
代码如下:
all_data=pd.merge(left=file_one,right=file_two,how='outer')
all_data
合并后的数据如下:

(3)数据的筛选
由于题目要求对中国篮球运动员进行分析,因此需要根据国籍筛选一下,只保留国籍为中国的运动员。
我又忘记怎么写了,先单独筛选国籍看看?
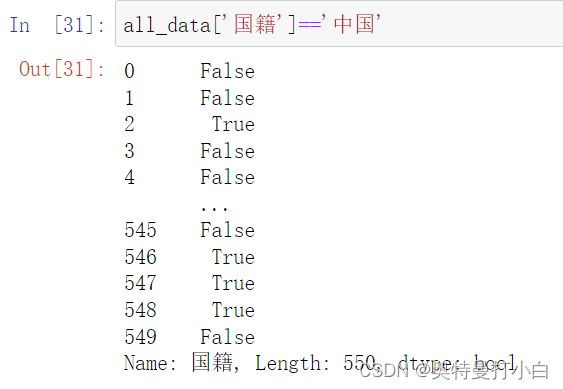
一堆布尔值,所以,我想要的应该是all_data中,布尔值为True的那些数据。
完整代码如下:
# 筛选出国籍为中国的运动员
all_data=all_data[all_data['国籍']=='中国']
# 查看DataFrame类对象的摘要,包括索引、各列数据类型、非空值数量、内存使用情况等
all_data.info()

观察输出结果可知,数据中后5列的非空值数量不等,说明可能存在缺失值、重复值等;所有列的数据类型均为Object型,因此后续需要先对部分列进行数据类型转换操作,之后才能计算要求的统计指标。
进入下一步,数据清理。
3. 数据清理
在对数据进行分析之前,我们需要先解决前面发现的数据问题,包括重复值、缺失值和异常值的检测与处理,从而为后期分析工作提供高质量的数据。
(1)检测与处理重复值——duplicated()和drop_duplicates()

如图,执行all_data.duplicated()方法只能拿到一堆布尔值,True代表重复,False代表没重复,要想看到里面到底有哪些重复值,需要筛选all_data中检测值为True的项。
因此,检测重复值的代码如下:
all_data[all_data.duplicated().values==True]
找到以下五条重复值

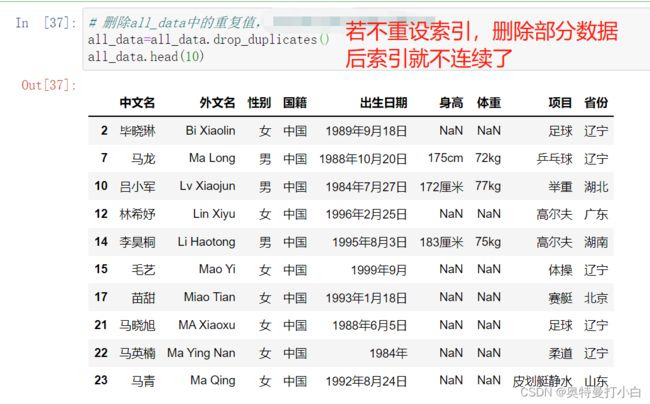
调用drop_duplicates()方法删除重复值,ignore_index参数设置为True,删除重复值后重新设置索引,代码如下:
# 删除all_data中的重复值,并重新为每行数据设置索引
all_data=all_data.drop_duplicates(ignore_index=True)
all_data.head(10)
运行结果如图:

- 常见错误:
(2)处理缺失值,统一单位——fillna()
由于本例只需要分析中国篮球运动员,因此需要进一步筛选项目为“篮球”的数据。
# 筛选出项目为篮球的数据
basketball_data = all_data[all_data['项目']=='篮球']
运行结果部分数据如下:

①处理“出生日期”列的缺失值
单独查看“出生日期”列的数据,看是否有缺失?
# 访问“出生日期”一列的数据
basketball_data['出生日期']
发现“出生日期”这一列没有缺失值,但包含“X年X月X日”、“X年X月”、“X年”和“X”等多种类型的数据。
为保证“出生日期”一列数据的一致性,这里统一将数据修改为“X年”格式,代码如下(虽然要素过多,但研究了半小时后我顿悟了,所以不要直接放弃,加油!):
import datetime
# ?????这句我不懂
basketball_data=basketball_data.copy()
# 将以“X”显示的日期转换成以“X年X月X日”形式显示的日期
# 小白碎碎念:这里的数字值“X”,比如32599、33757等,指的是与1900年1月1日相差的天数,这一句里的第一个datetime是模块名,第二个datetime是里面的对象,strptime是方法名,意为将基准日期转换为年月日的形式
initial_time=datetime.datetime.strptime('1900-01-01','%Y-%M-%d')
# 访问“出生日期”一列的数据
# 小白碎碎念:这个冒号很玄妙,loc[行号, 列号],行号这里的冒号代表全部,列号这里指定了“出生日期”,因此basketball_data.loc[:,'出生日期']取到的是“出生日期”这一列中的所有行的数据
for i in basketball_data.loc[:,'出生日期']:
# 只处理纯五位数字的日期,其他X年X月类似文本日期都跳过
if type(i)==int:
# 基准日期加上偏移天数,再转换为XXXX年XX月XX日的形式,这里必须是大写的Y,如果小写的话输出格式会变成XX年,后面的.format是格式化输出,花括号里的y,m,d都是占位置用的,实际值是format中的值
new_time=(initial_time+datetime.timedelta(days=i)).strftime('%Y{y}%m{m}%d{d}').format(y='年',m='月',d='日')
# 调用replace函数,将原来的数字替换为转换好的新日期
basketball_data.loc[:,'出生日期']=basketball_data.loc[:,'出生日期'].replace(i,new_time)
# 为保证出生日期的一致性,这里统一使用只保留到年份的日期,lambda是一个特殊函数,x[:5]意为取前5个字符,即XXXX年
basketball_data.loc[:,'出生日期']=basketball_data['出生日期'].apply(lambda x:x[:5])
# 展示前10条出生日期数据
basketball_data['出生日期'].head(10)
检验出生日期格式转换结果,运行如下:

到此出生日期转换完毕。
②处理“身高”列的缺失值
“身高”一列存在多个缺失值,建议用填充缺失值——统计方法填充。由于男篮和女篮运动员体质不同,所以这里需要先以“性别”做区分,男性缺失值用男性的平均值填充,女性缺失值用女性的平均值填充。
此处要素过多,待研究。
# 筛选男篮运动员数据
# male_data=basketball_data[basketball_data['性别']=='男']
# 疑问1:为何要用lambda?
male_data=basketball_data[basketball_data['性别'].apply(lambda x:x=='男')]
# 疑问2:为什么要拷贝一下这个对象?用它本身不可以吗?
male_data=male_data.copy()
# 计算身高平均值(四舍五入取整)
# 小白解读:计算平均身高前,要先删掉空值数
male_height=male_data['身高'].dropna()
# 小白解读:round方法是四舍五入,astype(int)是类型转换,mean()是求平均数
fill_male_height=round(male_height.apply(lambda x:x[0:-2]).astype(int).mean())
# 小白解读:上一步求出来的是小数,先强制转化成int整数,再转换成字符串型,才能在最后加上同为字符串类型的“厘米”单位
fill_male_height = str(int(fill_male_height))+'厘米'
# 填充缺失值
# 小白解读:将“身高”一列中,所有的缺失值都填充为男性身高平均值
male_data.loc[:,'身高']=male_data.loc[:,'身高'].fillna(fill_male_height)
# 为方便后期使用,这里将身高数据转换为整数
male_data.loc[:,'身高']=male_data.loc[:,'身高'].apply(lambda x:x[0:-2]).astype(int)
# 重命名列标签引用
male_data.rename(columns={'身高':'身高/cm'},inplace=True)
male_data
接下来处理女篮数据
import numpy
# 筛选女篮运动员数据
female_data=basketball_data[basketball_data['性别'].apply(lambda x:x=='女')]
female_data=female_data.copy()
# 由于身高数据格式差异大,也没有现成工具,所以只能用字典手动处理
data={'191cm':'191厘米', '1米89公分':'189厘米','2.01米':'201厘米','187公分':'187厘米','1.97M':'197厘米','1.98米':'198厘米','192cm':'192厘米'}
female_data.loc[:,'身高']=female_data.loc[:,'身高'].replace(data)
# 计算女篮运动员平均身高
female_height=female_data['身高'].dropna()
fill_female_height=round(female_height.apply(lambda x:x[0:-2]).astype(int).mean())
# 强制转换成整数,再转换成字符串,最后加上单位“厘米”
fill_female_height=str(int(fill_female_height))+'厘米'
# 填充缺失值
female_data.loc[:,'身高']=female_data.loc[:,'身高'].fillna(fill_female_height)
# 为方便后期使用,这里将身高数据转换为整数
female_data['身高']=female_data['身高'].apply(lambda x:x[0:-2]).astype(int)
# 重命名列标签索引
female_data.rename(columns={'身高':'身高/cm'},inplace=True)
female_data
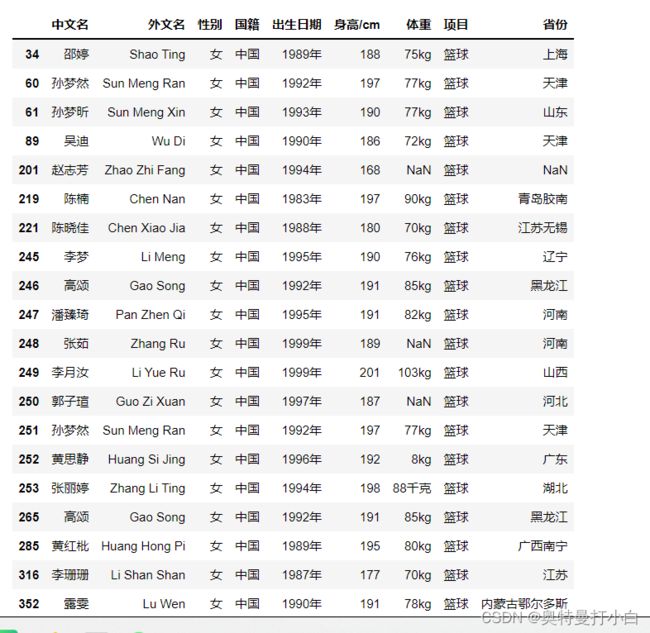
③处理“体重”列的缺失值
观察前面两次的输出结果,发现女篮运动员数据中“体重”一列存在缺失值,且该列中行索引为253的数据与其他行数据的单位不统一。
- 因此,这里先替换行索引为253的数据使之与其他数据具有相同的单位,代码如下:
# 先统一数据单位
female_data.loc[:,'体重']=female_data.loc[:,'体重'].replace({'88千克':'88kg'})
female_data

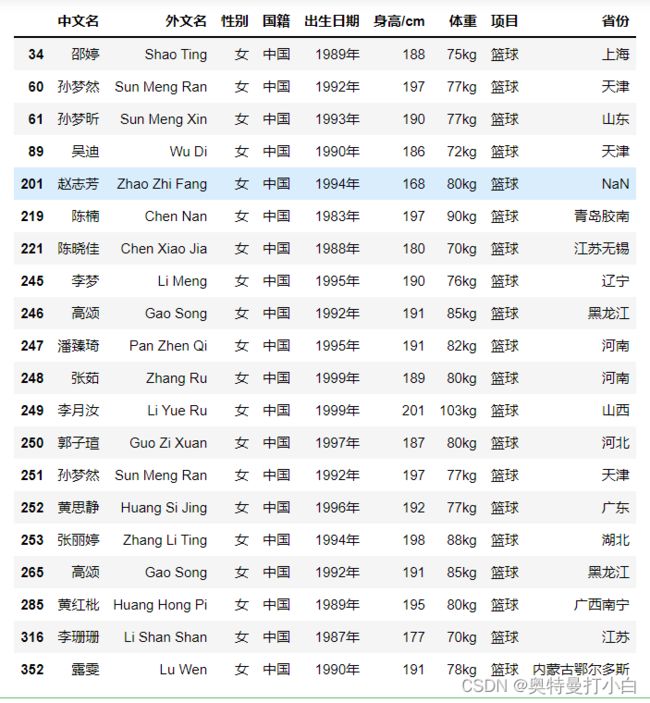
- 从数据可以看到,体重列存在NaN缺失值,252行还存在一个8kg的值明显也不符合实际,因此,直接用向前填充的方式替换,使之拥有与上一行相同的数值。
# 采用向前填充的方式,替换体重为8kg的值
female_data['体重'].replace(to_replace='8kg',method='pad',inplace=True)
female_data

- 接下来就可以处理缺失值NaN了。这里用正常体重数据的“平均值”来填充。
还是熟悉的流程,先清除所有缺失值,再将数据类型转换为int型后计算平均体重,然后通过得到的平均体重填充缺失值,代码如下:
# 计算女篮运动员的平均体重——先清除缺失值,再转换数据类型,最后计算平均值
female_weight=female_data['体重'].dropna()
# lambda x:x[0,-2]意为删掉最后两个字符,即去除单位,astype(int)意为将去除kg这个单位后的体重数据转换为整数类型
female_weight=female_weight.apply(lambda x:x[0:-2]).astype(int)
# mean()意为求平均数,round代表四舍五入
fill_female_weight=round(female_weight.mean())
# 将平均体重的小数点舍弃,只保留整数,转换为str字符串类型之后就可以把kg这个单位拼接回来了
fill_female_weight=str(int(fill_female_weight))+'kg'
# 填充缺失值,inplace=True这句待消化。。。
female_data.loc[:,'体重'].fillna(fill_female_weight, inplace=True)
female_data
对比可知,248和250行的缺失数据已填充成功。
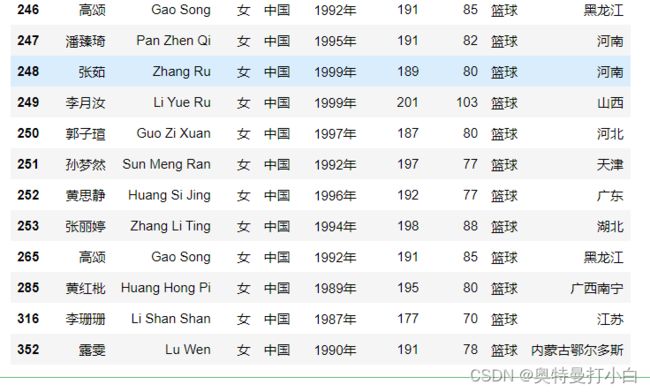
- 最后合并男篮运动员和女篮运动员的数据,转换体重一列为int类型,并将该列的索引重命名为“体重/kg”
basketball_data=pd.concat([male_data,female_data])
basketball_data['体重']=basketball_data['体重'].apply(lambda x:x[0:-2]).astype(int)
basketball_data.rename(columns={'体重':'体重/kg'},inplace = True)
basketball_data
体重列缺失值处理完后的完整数据如下图所示:

(3)检测与处理异常值——3σ和箱型图
为提高后期计算的准确性,需要对整租数据做异常值检测,这里通过箱型图和3σ原则两种方式分别检测“身高/cm”和“体重/kg”两列数据。
- 使用箱型图检测男篮运动员的身高数据
from matplotlib import pyplot as plt
# 设置中文显示
plt.rcParams['font.sans-serif']=['SimHei']
# 使用箱型图检测男篮运动员“身高/cm”一列是否有异常值
male_data.boxplot(column=['身高/cm'])
plt.show()

- 使用箱型图检测女篮运动员的身高数据
# 使用箱型图检测女篮运动员“身高/cm”一列是否有异常值
female_data.boxplot(column=['身高/cm'])
plt.show()
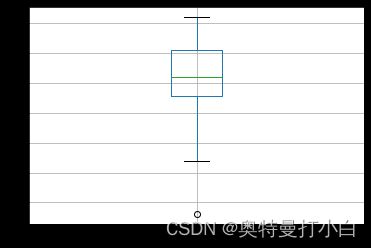
观察以上两个箱型图可知,女篮运动员的身高数据中存在一个小于170的值,经核实后确认该值为非异常值,可直接忽略。
- 使用3σ原则分别检测女篮和男篮运动员的体重数据
import numpy as np
# 定义基于3σ原则检测的函数
def three_sigma(ser):
# 计算平均值
mean_data=ser.mean()
# 计算标准差
std_data=ser.std()
# 数值小于μ-3σ或大于μ+3σ均为异常值
rule=(mean_data-3*std_data>ser) | (mean_data+3*std_data<ser)
# 返回异常值的位置索引
# 这一句待研究,又忘了
index=np.arange(ser.shape[0])[rule]
# 获取异常值
outliers=ser.iloc[index]
return outliers
# 使用3σ原则检测女篮运动员的体重数据
female_weight=basketball_data[basketball_data['性别']=='女']
three_sigma(female_weight['体重/kg'])

再使用3σ原则检测男篮运动员的体重数据
# 使用3σ原则检测男篮运动员的体重数据
male_weight=basketball_data[basketball_data['性别']=='男']
three_sigma(male_weight['体重/kg'])

从两次输出结果可知,女篮运动员的体重数据中存在一个离群值,即行索引为249对应的值103,经核实后确认该离群值为非异常值,可直接忽略。
特别注意:缺失值是否要删除或填充,异常值是否要处理,都要视情况灵活而定
三、 任务执行:分析运动员数据
1. 计算中国男篮、女篮运动员的平均身高与平均体重,保留一位小数
方法提示:求平均mean(),分组groupby(),保留小数round()
# 以“性别”一列分组,对各分组执行求平均值操作,并要求平均值保留一位小数
basketball_data.groupby('性别').mean().round(1)

2. 分析中国篮球运动员的年龄分布
方法提示:
- apply()和lambda根据出生年份计算年龄
- plot()绘制直方图,及坐标轴标签和刻度的设置
import matplotlib.pyplot as plt
# 设置图中文字的字体为黑体
plt.rcParams['font.sans-serif']=['SimHei']
# 根据出生日期计算年龄
ages=2022-basketball_data['出生日期'].apply(lambda x:x[0:-1]).astype(int)
# 根据计算的年龄值绘制直方图
ax=ages.plot(kind='hist')
# 设置直方图中x轴、y轴的标签为“年龄(岁)”和“频数”
ax.set_xlabel('年龄(岁)')
ax.set_ylabel('频数')
# 设置x轴的刻度为ages的最小值,ages的最小值+2,...,ages的最大值+1
ax.set_xticks(range(ages.min(),ages.max()+1,2))

从图中可以看出,篮球运动员的年龄主要分布在21-37岁,其中年龄分布在26-29岁的运动员居多。
3. 计算中国篮球运动员的体质指数
体质指数(Body Mass Index,BMI)是国际上常用的度量体重与身高比例的工具,它利用体重与身高之间的比例来衡量一个人是否过瘦或过胖。体质指数的计算公式如下:
体质指数(BMI)=体重(kg)÷ 身高²
由于亚洲人和欧美人的体质存在一些差异,世界卫生组织制订了符合亚洲人的体质指数参考标准,具体如下表所示:
| 体质指数 | 男性 | 女性 |
|---|---|---|
| 过轻 | 低于20 | 低于19 |
| 正常 | 20~25 | 19~24 |
| 过重 | 25~30 | 24~29 |
| 肥胖 | 30~35 | 29~34 |
| 极度肥胖 | 高于35 | 高于34 |
接下来,根据篮球运动员的信息及体质指数公式,统计所有篮球运动员的体质指数。
- 首先,在basketball_data基础上增加“体质指数”一列,暂时设置该列的初始值为0。代码如下:
# 增加“体质指数”一列
basketball_data['体质指数']=0
basketball_data.head(5)
- 然后,定义一个计算体质指数的函数,代码如下:
# 计算体质指数
def outer(num):
def ath_bmi(sum_bmi):
weight=basketball_data['体重/kg']
height=basketball_data['身高/cm']
sum_bmi=weight/(height/100)**2
return num+sum_bmi
return ath_bmi
- 最后,根据身高与体重数据计算每个篮球运动员的体质数据,并将所得的结果赋值给“体质指数”一列,代码如下:
basketball_data['体质指数']=basketball_data[['体质指数']].apply(outer(basketball_data['体质指数'])).round(1)
basketball_data
部分数据如下:
- 由于“体质指数”一列数据量比较大,无法直接看出哪些运动员的体质指数超过标准范围,因此这里分别将女篮和男篮运动员的体质指数与正常体质指数范围进行比较,凡是体质指数超出正常体质指数范围的篮球运动员均被视为体质指数为非正常的篮球运动员。代码如下:
#首先按性别分组
groupby_obj=basketball_data.groupby(by='性别')
# 以下为女篮运动员体质指数的统计,不在19~24范围内的都视为非正常
# dict是字典,有key和value两个属性,此句用法尚待研究
females=dict([x for x in groupby_obj])['女']['体质指数'].values
# 统计体质指数为非正常的女篮运动员的数量
count=females[females<19].size+females[females>24].size
print(f'体质指数小于19:{females[females<19]}')
print(f'体质指数大于24:{females[females>24]}')
print(f'非正常体质指数范围的总人数:{count}')
# 以下为男篮运动员体质指数的统计,不在20~25范围内的都视为非正常
males=dict([x for x in groupby_obj])['男']['体质指数'].values
# 统计体质指数为非正常的男篮运动员的数量
count=males[males<20].size+males[males>25].size
print(f'体质指数小于20:{males[males<20]}')
print(f'体质指数大于25:{males[males>25]}')
print(f'非正常体质指数范围的总人数:{count}')
运行结果如下:

从两次输出结果可以看出,个别篮球运动员的体质指数过高,其余大果树篮球运动员的体质指数正常。
总结
经过本案例练习,我发现数据分析思路不难,但数据切片、嵌套函数、格式化输出、apply和lambda的用法还非常生疏,阻挡我的不是pandas,而是Python基础。。。
啥也不说了,慢慢学吧。。。
参考资料:
黑马程序员的《Python数据预处理》