Python数据分析入门笔记10——简单案例练习(学生信息分析)
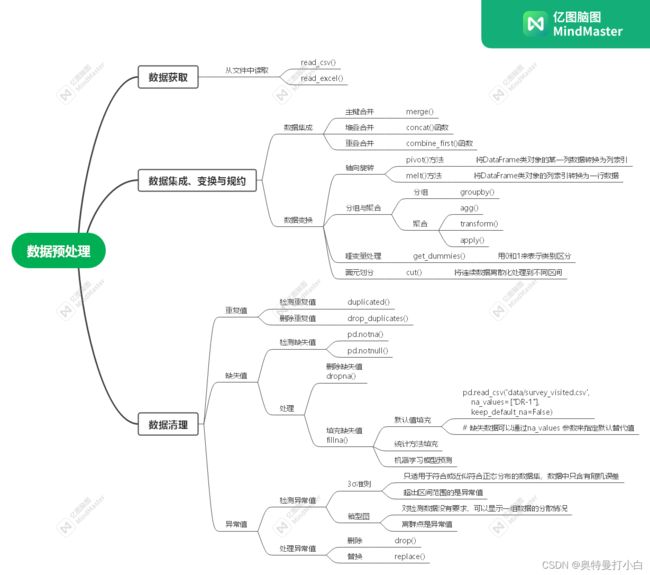
系列文章目录
Python数据分析入门笔记1——学习前的准备
Python数据分析入门笔记2——pandas数据读取
Python数据分析入门笔记3——数据预处理之缺失值
Python数据分析入门笔记4——数据预处理之重复值
Python数据分析入门笔记5——数据预处理之异常值
Python数据分析入门笔记6——数据清理案例练习
Python数据分析入门笔记7——数据集成、变换与规约
Python数据分析入门笔记8——Pandas处理日期时间类型数据
Python数据分析入门笔记9——数据预处理案例综合练习(男篮女篮运动员)
文章目录
- 系列文章目录
- 预备知识:
- 一、任务说明
- 二、任务分解
-
- 1. 根据表数据创建一个DataFrame类对象
- 2. 根据“年级”分组,并输出大一同学信息——groupby()
- 3. 输出每个年级中身高最高的学生信息——max和apply
- 4.计算大一学生与大三学生的平均体重——平均数mean()和四舍五入round()
- 三、参考答案(书中配套答案)
- 总结
预备知识:
一、任务说明
现有一张保存了学生信息的表格,具体如下所示:

按要求操作表格中的数据,具体如下:
(1) 根据表格,创建一个DataFrame类对象。
(2) 根据“年级”列分组,并输出大一年级的学生信息。
(3) 计算出每个年级中身高最高的学生。
(4) 计算大一学生与大三学生的平均体重。
二、任务分解
1. 根据表数据创建一个DataFrame类对象
提示:构造方法如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
其中,data表示传入的数据,columns表示列索引,index表示行索引,这是最常用的三个参数,行索引和列索引默认为从0开始的整数。
抛砖引玉案例:若有表格如下:
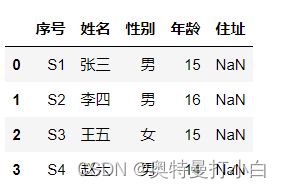
(1)方法1:先观察,有列标题,没有特定行标题,因此只需要传入data和columns即可。参考代码如下:
import pandas as pd
import numpy as np
df=pd.DataFrame(columns=['序号','姓名','性别','年龄','住址'],
data=[['S1','张三','男',15,np.nan],
['S2','李四','男',16,np.nan],
['S3','王五','女',15,np.nan],
['S4','赵六','男',14,np.nan]
]
)
(2)方法2:由于只有列标题,因此,还可以用逐列的方式来创建,参考代码如下:
import pandas as pd
import numpy as np #要使用NaN,NAN或nan都必须导入Numpy库
df=pd.DataFrame({'序号':['S1','S2','S3','S4'],
'姓名':['张三','李四','王五','赵六'],
'性别':['男','男','女','男'],
'年龄':[15,16,15,14],
'住址':[np.nan,np.nan,np.nan,np.nan]
})
思考1:对于本例学生信息表,要用哪种方式创建呢?要怎样改?
2. 根据“年级”分组,并输出大一同学信息——groupby()
抛砖引玉案例:以上示例中根据性别分组的代码如下:
groups1=df.groupby("性别")
# 注意,分组之后得到的结果,需要用一个for循环遍历读取
for i in groups1:
print(i)
运行结果如下:

思考2-1:对于本例学生信息分析,要如何按年级分组,如何验证分组是否正确?
思考2-2:若只想拿到大一年级的数据,如何筛选出来呢?
3. 输出每个年级中身高最高的学生信息——max和apply
抛砖引玉案例:按性别分组之后,需要取“年龄”列,然后就可以用内置函数输出每个组中的最小年龄了。
- 方法1:直接调用min函数
df.groupby(by="性别")['年龄'].min()
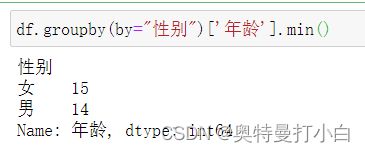
注意:若min()函数无法使用,可以用df.info()来查看各属性的数据类型,必须是数值类型才可以进行最大值max、最小值min、平均值min等统计操作。
- 方法2:用apply方法,使用内置函数,单独把年龄列拿出来再调用min函数
groups2=df.groupby(by="性别")['年龄']
groups2.apply(min)
【拓展】apply函数用法待补充。
思考3:对于本例,要如何输出每个年级中身高最高的学生信息?
4.计算大一学生与大三学生的平均体重——平均数mean()和四舍五入round()
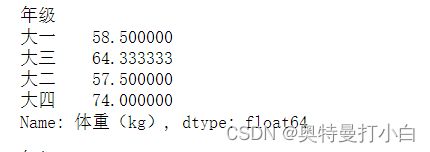
【子任务1】用mean()函数来计算每个年级学生的平均体重。
data2 = student_info.groupby(by='年级')['体重(kg)'].mean()
print(data2)
【子任务2】对平均体重进行四舍五入操作。
提示:round(要操作的数据列.mean(),2)代表四舍五入保留两位小数。

【子任务3】若要针对大一和大三这两个年级计算,怎么取到对应数据呢?
提示:可以用get_group()方法。也可以用字典dict。
【子任务4】格式化输出,例如:大一学生平均体重为:58.50kg。
提示:格式化输出待补充。
三、参考答案(书中配套答案)
(1)根据表格,创建一个DataFrame类对象。
import pandas as pd
student_info = pd.DataFrame({"年级":['大一','大二','大三','大四',
'大二','大三','大一','大三','大四'],
"姓名":['李宏卓','李思真','张振海','赵鸿飞',
'白蓉','马腾飞','张晓凡','金紫萱','金烨'],
"年龄":[18,19,20,21,19,20,18,20,21],
"性别":['男','女','男','男','女',
'男','女','女','男'],
"身高(cm)":[175,165,178,175,160,180,167,170,185],
"体重(kg)":[65,60,70,75,55,70,52,53,73]})
print(student_info)
(2)根据“年级”列分组,并输出大一年级的学生信息。
data = student_info.groupby(by='年级')
result = dict([x for x in data])['大一']
print(result)
(3)计算出每个年级中身高最高的学生。
data.apply(max)
(4)计算大一学生与大三学生的平均体重。
# 大一学生平均体重
freshmen = dict([x for x in data])['大一']
freshmen_weight = str(freshmen['体重(kg)'].mean())+'kg'
print(f"大一学生平均体重为:{freshmen_weight}")
# 大三学生平均体重
junior = dict([x for x in data])['大三']
# 保留一位小数
junior_weight = str(round(junior['体重(kg)'].mean(),2))+'kg'
print(f"大三学生平均体重为:{junior_weight}")
总结
(2)中的字典,和(4)中的这个数字转字符串再加kg的操作,我有点看不太明白,(4)的代码总觉得复杂化了。
本文中任务分解部分为原创,案例及参考答案来自:人民邮电出版社,黑马程序员主编的《Python数据预处理》
新手上路,如有疏漏,欢迎指正!