余弦相似度计算的实现方式
目录
一、余弦相似度计算方式
1、python
2、sklearn
3、scipy
4、numpy
5、pytorch
6、faiss
二、规模暴增计算加速
1、numpy矩阵计算GPU加速——cupy
2、pytorch框架cuda加速
3、faiss的加速方法
总结
在做文本匹配、文本推荐的时候需要用到文本相似性的评估,一般都采用比较简单的cos_similarity——余弦相似度(值越大,两者越相似,向量夹角越小,极限是重合,夹角为0,此时余弦相似度是1)。在计算余弦相似度的时候就有很多中方法和工具了,下面就我所知道的或者用过方法和工具做一个简单的总结。
一、余弦相似度计算方式
1、python
自己实现一个,按照cos的计算公式——向量的内积除以向量模长的积代码如下:
def python_cos(q_vec,b_vec):
"""
计算余弦相似度
:param q_vec: 一维数组
:param b_vec: 一维数组
:return:
"""
dot_q_b = 0
q_vec_length = 0
b_vec_length = 0
for q, b in zip(q_vec, b_vec):
dot_q_b += q * b
q_vec_length += q * q
b_vec_length += b * b
length = (q_vec_length ** (1 / 2)) * (b_vec_length ** (1 / 2))
cos_sim = dot_q_b / length #向量的内积除以向量模长的积
print('cos_sim',cos_sim)
return cos_simq_vec,b_vec都是一维数组,如果需要计算多个的向量的话就需要进行循环处理了
2、sklearn
sklearn机器学习算法常用库,这个就比较简单了只需要直接调用sklearn中相关的API即可:
from sklearn.metrics.pairwise import cosine_similarity
"""
a和b都要是2维
"""
a = [[1,2,3],[3,2,1]]
b = [[3,2,1],[1,2,3]]
cos = cosine_similarity(a,b)
print(cos)注意这里的参数,a和b都必须是二维的,不然会报错;a和b中的元素个数不定。
3、scipy
这也是一个库,提供了各种科学计算的API
import scipy.spatial
"""
a和b都要是2维
"""
a = [[1,2,3]]
b = [[3,2,1],[4,5,6]]
dis = scipy.spatial.distance.cdist(a,b,'cosine')
cos = 1 - dis[0]
print(cos)注意这里的参数,a和b的数据类型可以是数组、np.array();a和b都必须是二维的;a和b中的元素个数不定。这里dis可以理解为余弦距离,要用1-dis才是余弦相似度。
4、numpy
numpy这里计算余弦相似度就稍微麻烦了一点,要把相应的公式用numpy去实现一遍。
def numpy_cos(a,b):
dot = a*b #对应原始相乘dot.sum(axis=1)得到内积
a_len = np.linalg.norm(a,axis=1)#向量模长
b_len = np.linalg.norm(b,axis=1)
cos = dot.sum(axis=1)/(a_len*b_len)a,b的数据类型只能是np类型
5、pytorch
使用pytoch中的张量也能完成余弦相似度的计算,代码如下:
def torch_cos(a,b):
d = torch.mul(a, b)#计算对应元素相乘
a_len = torch.norm(a,dim=1)#2范数,也就是模长
b_len = torch.norm(b,dim=1)
cos = torch.sum(d, dim=1)/(a_len*b_len)#得到相似度
def torch_cos_new(a,b):
cos = torch.cosine_similarity(a,b,dim=1)
print(cos)a,b必须是tensor张量;torch_cos中有个bug,a和b的第一维只能是1,不然会出现错误结果。
6、faiss
这个是facebook公司提供的一个快速搜索用的算法库,其加速原理这里不介绍了,感兴趣的自己去看相关论文。还有一个就是这个算法库安装比较麻烦!
一般安装的时候采用conda来安装
#安装faiss-cpu
conda install faiss-cpu=1.4 -c pytorch
目前安装1.4 1.5 之类的版本比较好。另外安装GPU版本的就的和cuda版本对应上,还要把faiss的版本别弄得太高了,一般不要装最新的,容易出错。
conda install faiss-gpu cuda10.0 -c pytorch关于怎么计算向量之间的距离并找出最近的那几个向量,怎么使用呢?github有相应的教程。关于怎么计算余弦相似度这里不能直接给出要经过中间计算,类似上面numpy的方法。下文在给出代码展示
二、规模暴增计算加速
上面就两个向量直接如何进行cos_similarity给出了一些方法和具体的代码以及简单的注意事项,现假设有这样一个需求——一个query向量需要和reference向量库计算余弦相似度,并要求得出topk;而reference向量库是几万几十万几百万几千万几亿的这种怎么应对呢?这个时候我们就需要考虑上面每一种算法的速度和性能了。来先来测试一下上述方法的性能。
测试代码全部在CPU上运行,测试CPU型号是AMD Ryzen 5 2600X Six-Core Processor
具体代码如下:
from examples.knncuda_faiss_torch_numpy_test.cos_sklearn import *
from examples.knncuda_faiss_torch_numpy_test.cos_numpy import *
from examples.knncuda_faiss_torch_numpy_test.cos_torch import *
from examples.knncuda_faiss_torch_numpy_test.cos_python import *
from examples.knncuda_faiss_torch_numpy_test.cos_scipy import *
import numpy as np
import time
import torch
if __name__ == '__main__':
np.random.seed(1234)
query = np.random.randn(1,768)
reference = np.random.randn(10000,768)
print('query',query.shape,'reference',reference.shape)
print('*' * 130)
a = query.tolist()[0]
bs = reference.tolist()
cos_sims = []
t = time.time()
for b in bs:
cos_sim = python_cos(a,b)
cos_sims.append(cos_sim)
print('python_cos time is ', time.time() - t)
t = time.time()
cos_sklearns = cosine_similarity(query, reference)[0]
cos_sklearns = np.sort(cos_sklearns)[::-1]
print('cos_sklearn time is ', time.time() - t)
t = time.time()
dis = scipy.spatial.distance.cdist(query, reference,'cosine')[0]
cos_scipy = 1 - dis
print('cos_scipy time is ', time.time() - t)
t = time.time()
cos_numpy = numpy_cos(query, reference)
print('cos_numpy time is ', time.time() - t)
query = torch.from_numpy(query)
reference = torch.from_numpy(reference)
t = time.time()
cos_torch = torch_cos(query, reference)
print('cos_torch time is ', time.time() - t)
t = time.time()
cos_torch_new = torch_cos_new(query, reference)
print('torch_cos_new time is ', time.time() - t)
print('*' * 130)
cos_sims.sort(reverse=True)
print('python_cos top_5 result', cos_sims[0:5])
print('cos_sklearn top_5 result', cos_sklearns[0:5])
np.sort(cos_numpy)[::-1]
print('cos_numpy top_5 result', cos_sims[0:5])
np.sort(cos_scipy)[::-1]
print('cos_scipy top_5 result', cos_sims[0:5])
cos_torch = torch.topk(cos_torch, 5, dim=0).values.tolist()
print('cos_torch top_5 result', cos_torch)
cos_torch_new = torch.topk(cos_torch_new, 5, dim=0).values.tolist()
print('torch_cos_new top_5 result', cos_torch_new)
print('*' * 130)结果如下所示
query (1, 768) reference (500000, 768)
**************************************************
python_cos time is 38.49528908729553
cos_sklearn time is 2.067091464996338
cos_scipy time is 0.380265474319458
cos_numpy time is 1.0932965278625488
cos_torch time is 0.4933135509490967
torch_cos_new time is 0.9776747226715088
计算的具体cos结果也是如下:
cos_sklearn top_5 result [0.16645179 0.16303576 0.16036169 0.16000034 0.15938602]
cos_numpy top_5 result [ 0.06810486 0.01430677 -0.01578631 0.09859463 0.00912929]
cos_scipy top_5 result [ 0.06810486 0.01430677 -0.01578631 0.09859463 0.00912929]
cos_torch top_5 result [0.16645179271825364, 0.16303576001992812, 0.16036168851422455, 0.16000033948033635, 0.1593860198744479]
torch_cos_new top_5 result [0.16645179271825356, 0.1630357600199281, 0.1603616885142245, 0.1600003394803363, 0.15938601987444787]说明都没有问题。从速度来看scipy提供的接口在100W级别是最快的,使用torch计算的速度次之;faiss的比较特殊,后面再进行单独演示。
就目前的速度对于用户的体验肯定不好,就要想办法进行计算加速了。最容易想到的就是利用GPU来进行加速计算了,因为它有多个核心,能并行计算和处理。先有一个简单的需求,就是100W向量0.1s内计算出相似度呢?下面一个一个方法的尝试。
测试机器配置
CPU:AMD Ryzen 7 2700X Eight-Core Processor
GPU: GeForce RTX 3090
初始状态图
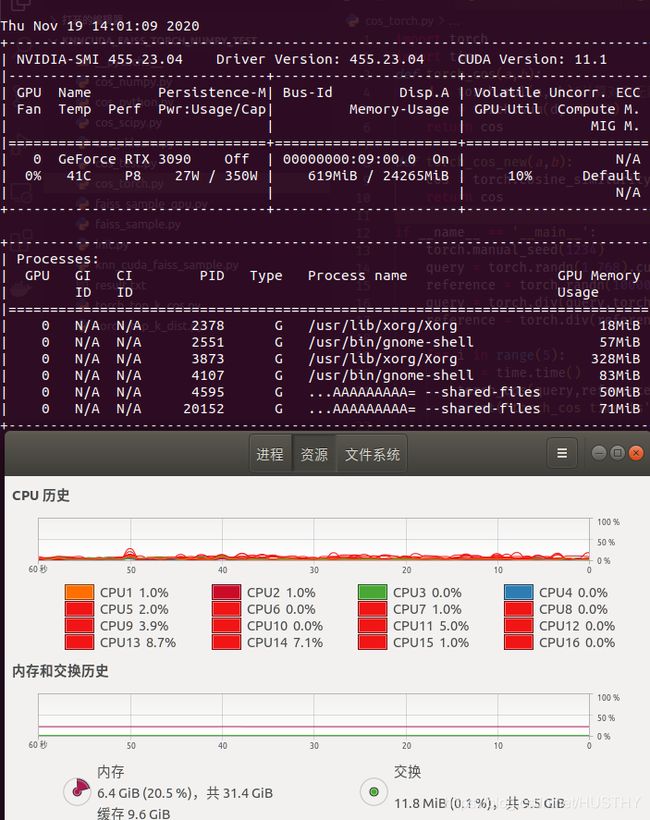
显存占用600M,内存占用6.4G
1、numpy矩阵计算GPU加速——cupy
这里也用到了一个矩阵计算通过cuda加速库——cupy安装方式如下:
# For CUDA 10.2
pip install cupy-cuda102它的使用方法和numpy类似
上代码:
import numpy as np
import time
import cupy as cp
def numpy_cos(a,b):
dot = a*b #对应原始相乘dot.sum(axis=1)得到内积
cos = dot.sum(axis=1)
return cos
def cupy_cos(a,b):
dot = a * b
cos = dot.sum(axis=1)
return cos
if __name__ == '__main__':
np.random.seed(1234)
query = np.random.randn(1, 768)
reference = np.random.randn(1000000, 768)
query = query/np.linalg.norm(query,axis=1)#得到单位向量
reference = reference/np.linalg.norm(reference,axis=1).reshape(-1,1)#得到单位向量
t = time.time()
for i in range(5):
cos_numpy = numpy_cos(query,reference)
print('numpy_cos average time is ',(time.time()-t)/5)
cp.random.seed(1234)
query = cp.random.randn(1, 768)
reference = cp.random.randn(1000000, 768)
query = query/cp.linalg.norm(query,axis=1)#得到单位向量
reference = reference/cp.linalg.norm(reference,axis=1).reshape(-1,1)#得到单位向量
t = time.time()
for i in range(5):
cos_cupy = cupy_cos(query, reference)
print('cos_cupy average time is ', (time.time() - t)/5)
time.sleep(5000)
结果如下所以:
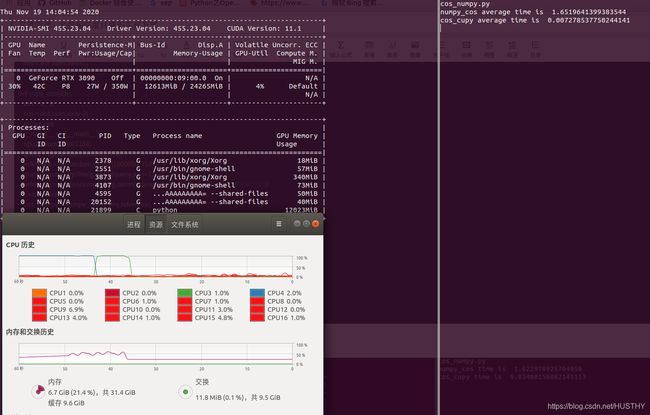
numpy计算100W*768维和1*768维向量的时间是1.65s,而cupy是0.0073s,cupy使用的是GPU也耗掉了12G显存;内存方便cupy几乎不占用,但是numpy占用的比较多,计算过程中numpy内存占用达到18G,总体耗用就是12G
2、pytorch框架cuda加速
同样的这里torch里面也内置了矩阵运算模块儿。而且也可以使用cuda进行加速!代码和结果如下:
import torch
import time
def torch_cos(a,b):
d = torch.mul(a, b)#计算对应元素相乘
cos = torch.sum(d, dim=1)
return cos
def torch_cos_new(a,b):
cos = torch.cosine_similarity(a,b,dim=1)
return cos
if __name__ == '__main__':
torch.manual_seed(1234)
query = torch.randn(1,768).cuda()
reference = torch.randn(1000000, 768).cuda()
query = torch.div(query,torch.norm(query, dim=1).reshape(-1,1))
reference = torch.div(reference,torch.norm(reference, dim=1).reshape(-1,1))
t = time.time()
for i in range(5):
torch_cos(query,reference)
print('torch_cos time is',time.time()-t)
t = time.time()
for i in range(5):
torch_cos_new(query, reference)
print('torch_cos_new time is', time.time() - t)
time.sleep(20000)结果如下图
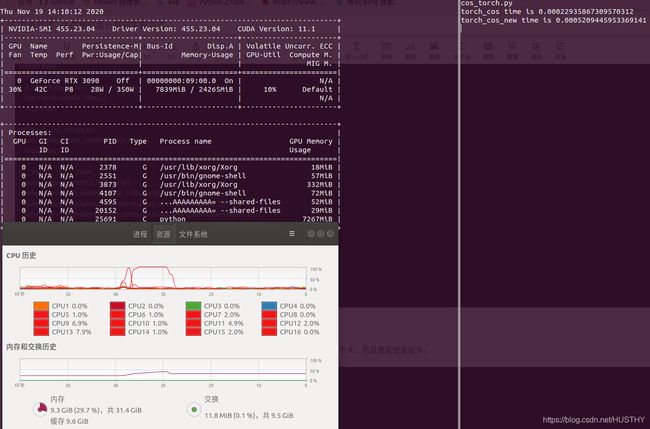
这样是比较快了,torch.mul()和torch.sum()结合的方法是0.0002s,torch.cosine_similarity()则是0.0005s;显存占用(主要是数据和中间结果在显存中占用)7G,内存占用3个G,但是当数据量更大的时候也是比较吃显存的,你那么可以降低精度,由fp32到fp16,对cos相似度结果影响不大,而且速度也会提升。看看效果:
import torch
import time
def torch_cos(a,b):
d = torch.mul(a, b)#计算对应元素相乘
cos = torch.sum(d, dim=1)
return cos
def torch_cos_new(a,b):
cos = torch.cosine_similarity(a,b,dim=1)
return cos
if __name__ == '__main__':
torch.manual_seed(1234)
query = torch.randn(1,768).cuda()
reference = torch.randn(1000000, 768).cuda()
query = torch.div(query,torch.norm(query, dim=1).reshape(-1,1))
reference = torch.div(reference,torch.norm(reference, dim=1).reshape(-1,1))
t = time.time()
for i in range(5):
cos = torch_cos(query,reference)
print('fp32 torch_cos time is',time.time()-t)
print('fp32 result is ',cos[0:5])
del query
del reference
del cos
torch.cuda.empty_cache()
print("*"*100)
torch.manual_seed(1234)
query = torch.randn(1,768).half().cuda()
reference = torch.randn(1000000, 768).half().cuda()
query = torch.div(query,torch.norm(query, dim=1).reshape(-1,1))
reference = torch.div(reference,torch.norm(reference, dim=1).reshape(-1,1))
t = time.time()
for i in range(5):
cos = torch_cos(query,reference)
print('fp16 torch_cos time is',time.time()-t)
print('fp16 result is ',cos[0:5])
time.sleep(20000)结果如下图
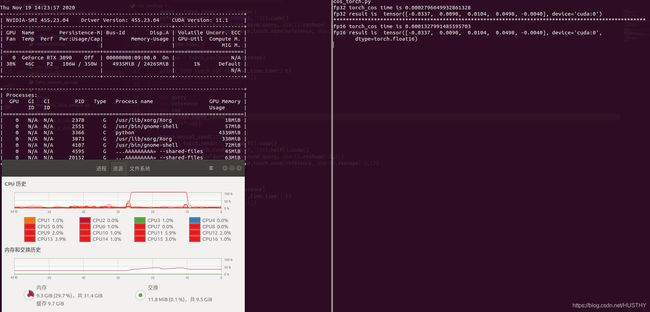
可以看到时间变为0.00028s变为0.00013s,显存占用由7G变为4.3G;而且cos准确率在小数点后4位都是一样的,提升比较明显.
3、faiss的加速方法
faiss是支持CPU和GPU的,也是支持多种索引的。暴力搜索索引IndexFlatL、加速搜索的方法的索引IndexIVFFlat(倒排文件缩小范围进行加速)以及IndexIVFPQ(Produce Quantizer)在IndexIVFFlat做了速度和内存方面的优化。faiss的具体原理有点复杂,想要详细的理解细节可自行查阅相关资料——如PQ和IVF介绍、Faiss基于PQ的倒排索引实现、facebookresearch / faiss等等。本文就简单的使用faiss来计算cos相似度进行展示。
faiss支持欧式距离和向量内积,可以利用向量内积来计算cos相似度——把向量先化为单位向量。
cpu版本:
import numpy as np
import time
import faiss
if __name__ == '__main__':
d = 768 # dimension
nb = 1000000 # database size
nq = 1 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb_len = np.linalg.norm(xb, axis=1, keepdims=True)
xb = xb/xb_len
xq = np.random.random((nq, d)).astype('float32')
xq_len = np.linalg.norm(xq, axis=1, keepdims=True)
xq = xq/xq_len
t1 = time.time()
nlist = 10 # we want to see 4 nearest neighbors
for i in range(5):
# CPU
index = faiss.IndexFlat(d, faiss.METRIC_INNER_PRODUCT) # 建立索引
index.add(xb) # add vectors to the index
D, I = index.search(xq, nlist) # actual search
t2 = time.time()
print('faiss spend time %.4f'%((t2-t1)/5))GPU版本:
import numpy as np
import time
import faiss
if __name__ == '__main__':
d = 768 # dimension
nb = 1000000 # database size
nq = 1 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb_len = np.linalg.norm(xb, axis=1, keepdims=True)
xb = xb/xb_len
xq = np.random.random((nq, d)).astype('float32')
xq_len = np.linalg.norm(xq, axis=1, keepdims=True)
xq = xq/xq_len
nlist = 10 # we want to see 4 nearest neighbors
res = faiss.StandardGpuResources() # use a single GPU
t1 = time.time()
index = faiss.IndexFlat(d,faiss.METRIC_INNER_PRODUCT)
# make it a flat GPU index
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, index)
gpu_index_flat.add(xb)
D, I = gpu_index_flat.search(xq, nlist) # actual search
t2 = time.time()
print('faiss-gpu spend time %.4f' % (t2 - t1))
print('I', I)
print('D', D)注意的是faiss支持fp32这种数据类型。
结果如下图:
cpu:AMD 2600x
faiss spend time 0.9918GPU版本的faiss这台机器没有安装,给不了具体结果,但是也不会太快,以前测过一次100W大概1.5s(也有可能记错了),以后机器有空了再测。主要耗时是faiss gpu需要把数据从cpu传到GPU上,这个过程我们前面代码没有算进来,因为实际中可以预先处理,使用faiss库的话就不能了除非更改它的代码。
| 方法 | CPU毫秒 | GPU毫秒 | 显存 |
| python | 76000 | - | - |
| scklearn | 4100 | - | - |
| scipy | 760 | - | - |
| numpy/cupy | 1652 | 73 | 12G |
| pytorch-cuda | 1000(torch-cos) | 0.28(torch-cos/fp32)、0.13(torch-cos/fp16) | 7.3G/4.3G |
| faiss | 992 | 1500(不确定) | - |
总体而言可以看到以上所有方式能使用GPU进行并行计算的,计算速度大为提升,当然这也是要消耗硬件资源的,在显卡资源有限的情况下,推荐使用torch框架来进行相似度计算加速,这个效果最好,显存占用少,灵活而且100W只要0.13毫秒(RTX-3090和fp16)。
500W的情况下可以做到14毫秒,显存也是占用了16G:

当然在不需要使用到GPU加速的场景下,优先推荐scipy这个科学计算库来进行计算,快速简单!
如果设计到上亿、10亿、百亿的怎么快速计算,我也不知道,如果有知道的人,可以讲解一下方案或者原理之类的,拜谢!
总结
计算向量之间的余弦相似度然后做搜索,在数据量很大的情况下,可以优先利用业务规则去掉很大一部分数据;在去掉数据以后还是比较大量的话,就需要使用一些加速算法(例如knn_cuda和faiss里面的算法)和硬件的支持了。当然也可以从数据精度的角度来考虑,降低数据的精度表示来进行计算。技术和成本都可以的话是可以利用超级计算机或者分布式或者云计算平台来解决。