一、定义Pytorch模型
目录
1. PyTorch模型定义的方式
1.1 torch.nn.Sequential
以上两种方式的唯一区别在于:
1.2 torch.nn.ModuleList
1.3 torch.nn.ModuleDict
1.4 实战
2. 用模型块快速搭建复杂网络
2.1 卷积神经网络基础
2.1.1 卷积层
2.1.2 池化层
2.1.3 全连接层
2.2 U-Net模型
2.3 U-Net模型块分析
2.4 U-Net模型块实现
2.5 U-Net模型块组装
3. PyTorch修改模型
3.1 修改模型层
3.2 添加外部输入
3.3 添加额外输出
1. PyTorch模型定义的方式
- 基于nn.Module,我们可以通过Sequential,ModuleList,ModuleDict三种方式来定义Pytorch模型。
- torch.nn.Module是所有网络的基类,在Pytorch实现的Model都要继承该类。而且,Module是可以包含其他的Module的,以树形的结构来表示一个网络结构
1.1 torch.nn.Sequential
- torch.nn.Sequential 类是 torch.nn 中的一种序列容器,通过在容器中嵌套各种实现神经网络中具体功能相关的类,来完成对神经网络模型的搭建,最主要的是,参数会按照我们定义好的序列自动传递下去。
- 我们可以将嵌套在容器中的各个部分看作是不同的模块,这些模块可以自由组合。
方式一:直接排列
import torch.nn as nn
hidden_layor = 256
input_data = 784
output_data = 10
net = nn.Sequential(
nn.Linear(input_data,hidden_layor), #完成从输入层到隐藏层的线性变换
nn.ReLU(), #激活层
nn.Linear(hidden_layor,output_data), #隐藏层到输出层的线性变换
)
print(net)

方式二:使用OrderDict有序字典进行传入搭建的模型
hidden_layor = 256
input_data = 784
output_data = 10
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict
([
('Line1',nn.Linear(input_data,hidden_layor)),
('Relu1',nn.ReLU()),
('Line2',nn.Linear(hidden_layor,output_data))
]))
print(net2)
以上两种方式的唯一区别在于:
- 使用第二种方式搭建的模型,每一个模块都可以自定义名字
- 第一个方式搭建的模块是默认从0开始的数字序号作为每一个模块的名字
1.2 torch.nn.ModuleList
- ModuleList是以list的形式保存sub-modules或者网络层,这样就可以先将网络需要的layer构建好保存到一个list,然后通过ModuleList方法添加到网络中。
import torch.nn as nn
hidden_layor = 256
input_data = 784
output_data = 10
net = nn.ModuleList([nn.Linear(input_data,hidden_layor),nn.ReLU()])
net.append(nn.Linear(hidden_layor,output_data))
print(net) # 类似List的索引访问
print(net[0])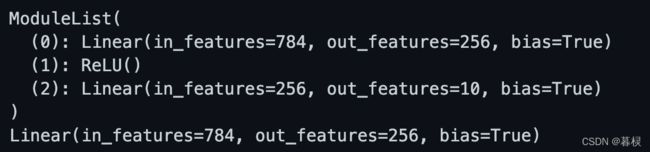
nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。ModuleList中元素的先后顺序并不代表其在网络中的真实位置顺序,需要经过forward函数指定各个层的先后顺序后才算完成了模型的定义。如下:
class model(nn.Module):
def __init__(self):
super(model,self).__init__()
# 构建layer的list
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self,x):
# 正向传播,使用遍历每个Layer
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x1.3 torch.nn.ModuleDict
- ModuleDict和ModuleList的作用类似,只是ModuleDict能够更方便地为神经网络的层添加名称。
import torch.nn as nn
hidden_layor = 256
input_data = 784
output_data = 10
net = nn.ModuleDict({
'Line1':nn.Linear(input_data,hidden_layor),
'ReLu':nn.ReLU()})
net['Line2'] = nn.Linear(hidden_layor,output_data)
print(net)
print(net['Line2'])
print(net.Line2)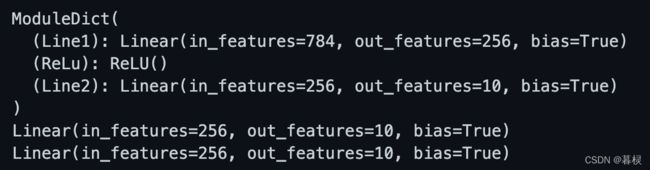
1.4 实战
import torch
import torch.nn as nn
from torch.autograd import Variable
batch_n = 100 #? 一个批次中输入数据的数量,意味着在一个批次中输入100个数据
hidden_layer = 100
input_data = 1000 #? 1000个特征
output_data = 10
#! 输入输出
x = Variable(torch.randn(batch_n,input_data),requires_grad=False) #? 输入层纬度(100,1000)
y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #? 输出层维度(100,10)
models = nn.Sequential(
nn.Linear(input_data,hidden_layer),
nn.ReLU(),
nn.Linear(hidden_layer,output_data)
)
#! 训练次数,学习速率
epoch_n = 10000
learning_rate = 1e-4
loss_fn = nn.MSELoss()
optimzer = torch.optim.Adam(models.parameters(),lr=learning_rate)
for epoch in range(epoch_n):
y_pred = models(x)
loss = loss_fn(y_pred,y)
print("Epoch:{}, Loss:{:.4f}".format(epoch,loss.data[0]))
optimzer.zero_grad()
loss.backward()
optimzer.step()2. 用模型块快速搭建复杂网络
当模型的深度非常大时候,使用Sequential定义模型结构需要向其中添加几百行代码,使用起来不甚方便。
对于大部分模型结构(比如ResNet、DenseNet等),我们仔细观察就会发现,虽然模型有很多层, 但是其中有很多重复出现的结构。考虑到每一层有其输入和输出,若干层串联成的”模块“也有其输入和输出,如果我们能将这些重复出现的层定义为一个”模块“,每次只需要向网络中添加对应的模块来构建模型,这样将会极大便利模型构建的过程。
我们以U-Net为例,介绍如何构建模型块,以及如何利用模型块快速搭建复杂模型。
2.1 卷积神经网络基础
2.1.1 卷积层
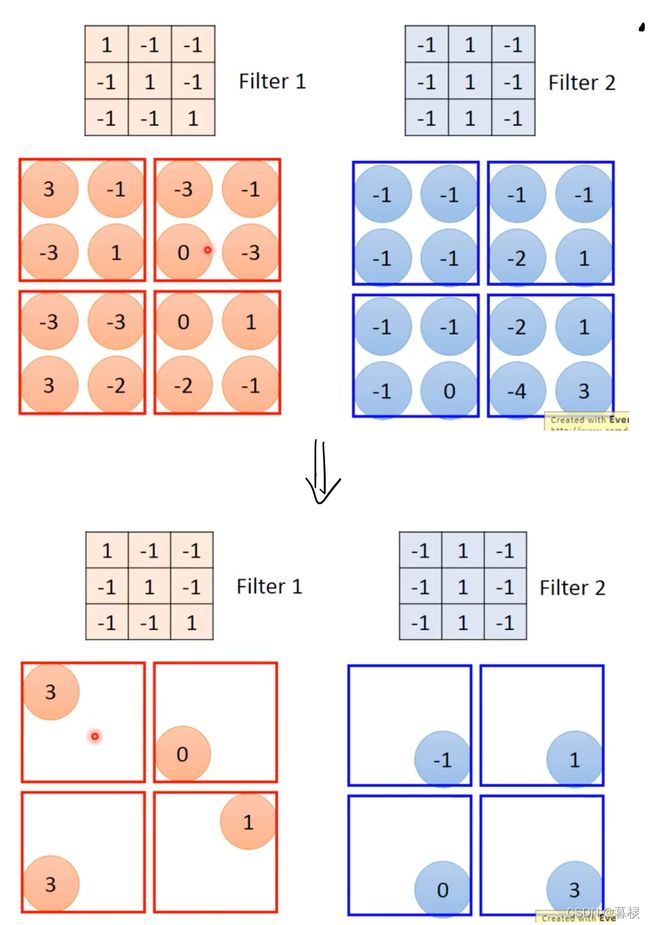
卷积层(Convolution Layer)的主要作用是对输入的数据进行特征提取,而完成该功能的是卷积层中的卷积核(Filter)。可以将卷积核看成是一个指定窗口大小的扫描器,扫描器通过一次又一次地扫描输入的数据,来提取数据中的特征。
例如:
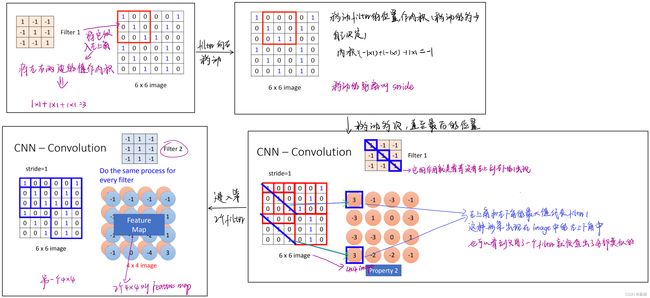
通过对卷积过程的计算 ,我们可以总结出一个通用公式,用于计算输入图像经过一轮卷积操作后的输出图像的宽度和高度的参数,公式如下:
![]()
![]()
通用公式中的W和H分别表示图像的宽度和高度的值;下标input表示输入图像的相关参数;下标output表示输出的图像的相关参数;下标filter表示卷积核的相关参数;S表示卷积核的步长;P表示在图像边缘增加的边界像素层数,如果图像边界像素填充的方式选择的是Same模式,那么P的值就等于图像增加的边界层数,如果选择的是Valid模式,那么P=0。
2.1.2 池化层
卷积神经网络中的池化层可以被看作卷积神经网络中的一种提取输入数据的核心特征的方式,不仅实现了对原始数据的压缩,还大量减少了参与模型计算的参数,从某种意义上提高了计算效率。
其中,最常被用到的池化层方法是平均池化层和最大池化层,池化层处理的输入数据在一般情况下是经过卷积操作之后生成的特征图。
如下为最大池化层:
通过池化层的计算,也能总结出一个通用公式,可以用来计算输入的特征图经过一轮池化操作后输出的特征图的宽度和高度:
![]()
![]()
其中,W和H分别表示特征图的宽度和高度值,下标inout表示输入的特征图的相关参数,下标output表示输出的特征图的相关参数,下标filter表示滑块窗口的相关参数,S表示滑动窗口的步长,并且输入的特征图的深度和滑动窗口的深度保持一致。
2.1.3 全连接层
全连接层的主要作用是将输入图像在经过卷积和池化操作后提取的特征进行压缩,并且根据压缩的特征完成模型的分类功能,如下是一个全连接层的简化流程。

上图中input是通过卷积层和池化层提取的输入图像的核心特征,与全连接层中定义的权重参数相乘,最后被压缩成只有10个输出参数,这10个输出参数其实已经是一个分类的结果,再经过激活函数的进一步处理,就能使分类预测结果更加明显。将10个参数输入到Softmax激活函数中,激活函数的输出结果就是模型预测的输入图像对应的各个类别的可能值。
2.2 U-Net模型
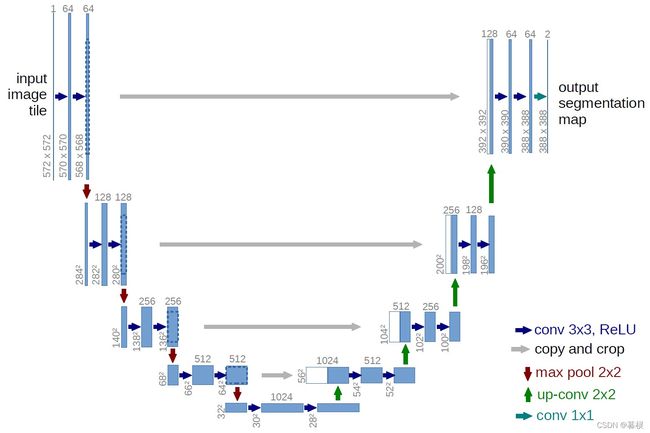
它的输入是一个维度为572x572x1的图像,即输入的是高度和宽度都为572的单通道图像。
经过两次卷积,使用的卷积核滑动窗口为3x3x1,步长为1,套用卷积通用公式,可以得出第一次卷积得出的特征图的高度和宽度均为570=(572-3-0)/1+1,第二次卷积得出的特征图的高度和宽度均为568=(570-3-0)/1+1。同时可以看到这个第一次的卷积层要求最后输出深度为64的特征图,所以需要进行64次同样的卷积操作,第一次卷积输出的特征图的维度为570x570x64,第二次卷积只需要对每一层进行1次卷积操作,输出的特征图维度为568x568x64。其中每次卷积都紧接着一个ReLu激活函数。
接下来是使用最大池化层进行下采样,下采样要完成的功能是缩减输入的特征图的大小,选择最大池化层的滑动窗口为2x2x64,因为输入的特征图的高度和宽度均为568,所以套用池化通用公式,可以得到最后输出的特征图的高度和宽度均为284=(568-2)/2+1,所以池化后输出的特征图的维度为284x284x64。再经过两次卷积,最后输出的特征图维度为280x280x128。
扩展路径包含一个上采样(2x2上卷积),这样会减半feature channel,接着是一个对应的收缩路径的feature map,然后是2个3x3卷积,每个卷积后面跟一个RELU,因为每次卷积会丢失图像边缘,所以裁剪是有必要的,最后来一个1x1的卷积,用来将有64个元素的feature vector映射到一个类标签,整个网络一共有23个卷积层。
可以看出来,就是一个全卷积神经网络,输入和输出都是图像,没有全连接层。较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。
2.3 U-Net模型块分析
从上图中可以看到,U-Net模型具有良好的对称性。模型从上到下分为若干层,每层由左侧和右侧两个模型块组成,每侧的模型块与其上下模型块之间有连接;同时位于同一层左右两侧的模型块之间也有连接,称为“Skip-connection”。此外还有输入和输出处理等其他组成部分。由于模型的形状非常像英文字母的“U”,因此被命名为“U-Net”。
U-Net的模块主要有以下几个部分:
- 每个子块中进行两次卷积(Double Convolution)
- 左侧模块为向下采样连接,即最大池化(Max Pooling)
- 右侧模块为向上采样连接
- 输出层的处理
2.4 U-Net模型块实现
将以上四个模块分别起名:DoubleConv,Down,Up,OutConv。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DdoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None):
#hs 初始化PyTorch父类
super().__init__() #? super().__init__()是调用了父类的构造函数
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
#? 二维卷积nn.Conv2d用于图像数据,对宽度和高度都进行卷积
nn.BatchNorm2d(mid_channels),
#? 在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
nn.ReLU(inplace=True),#? 运算后覆盖
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
#? 我们只将输入传递给self.double_conv(),它由nn.Sequential()定义,模型的输出直接返回给forward()主调函数
return self.double_conv(x)class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DdoubleConv(in_channels,out_channels)
)
def forward(self,x):
return self.maxpool_conv(x)class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
#? dilation:控制 kernel 点之间的空间距离,
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
#? torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
#? size:据不同的输入制定输出大小;
#? scale_factor:指定输出为输入的多少倍数;
#? mode:可使用的上采样算法,有nearest,linear,bilinear,bicubic 和 trilinear。默认使用nearest;
#? align_corners :如果为 True,输入的角像素将与输出张量对齐,因此将保存下来这些像素的值。
self.conv = DdoubleConv(in_channels, out_channels, in_channels//2)
else:
self.np = nn.ConvTranspose2d(in_channels,in_channels//2,kernel_size=2,stride=2)
self.conv = DdoubleConv(in_channels,out_channels)
def forward(self,x1,x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1,[diffX//2,diffX - diffX//2,
diffY//2,diffY - diffY//2])
x = torch.cat([x2,x1],dim=1)
return self.conv(x)class OutConv(nn.Module):
def __init__ (self,in_channels, out_channels):
super(OutConv,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=1)
def forward(self,x):
return self.conv(x)2.5 U-Net模型块组装
class UNet(nn.Module):
def __init__ (self, n_channels, n_classes, bilinear=True):
super(UNet,self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DdoubleConv(n_channels,64)
self.down1 = Down(64,128)
self.down1 = Down(128,256)
self.down3 = Down(256,512)
factor = 2 if bilinear else 1
self.down4 = Down(512,1024//factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits3. PyTorch修改模型
3.1 修改模型层
先查看模型的定义:
import torchvision.models as models
net = models.resnet50()
print(net)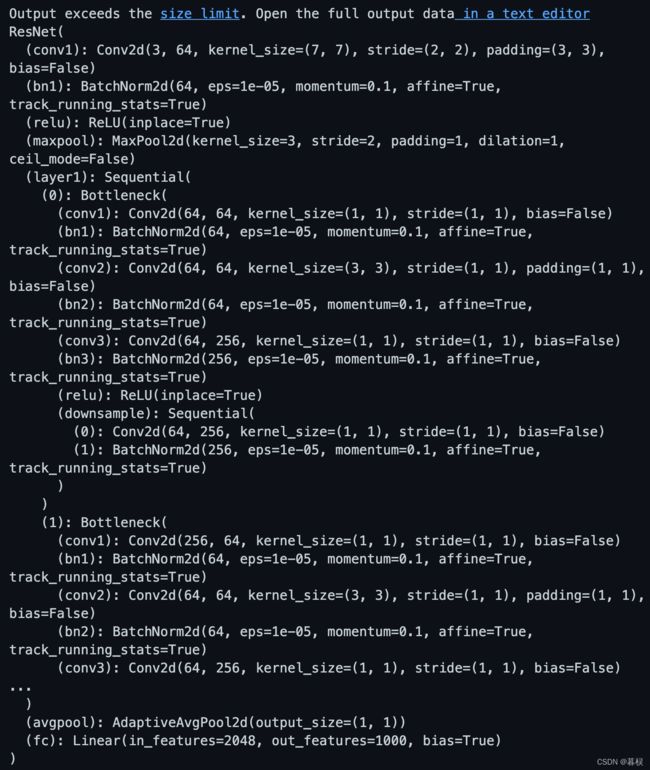
假设我们要用这个resnet模型去做一个10分类的问题,就应该修改模型的fc层,将其输出节点数替换为10。另外,我们觉得一层全连接层可能太少了,想再加一层。可以做如下修改:
from collections import OrderedDict
classifier = nn.Sequential(
OrderedDict([('fc1', nn.Linear(2048, 128)),
('relu1', nn.ReLU()),
('dropout1',nn.Dropout(0.5)),
('fc2', nn.Linear(128, 10)),
('output', nn.Softmax(dim=1))
]))
net.fc = classifier3.2 添加外部输入
基本思路是:将原模型添加输入位置前的部分作为一个整体,同时在forward中定义好原模型不变的部分、添加的输入和后续层之间的连接关系,从而完成模型的修改。
我们希望利用已有的模型结构,在倒数第二层增加一个额外的输入变量add_variable来辅助预测。
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc_add = nn.Linear(1001, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x, add_variable):
x = self.net(x)
x = torch.cat((self.dropout(self.relu(x)), add_variable.unsqueeze(1)),1)
x = self.fc_add(x)
x = self.output(x)
return x3.3 添加额外输出
基本的思路是修改模型定义中forward函数的return变量。
在已经定义好的模型上,同时输出了1000维的倒数第二层,还有10维的最后一层结构。
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(1000, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x, add_variable):
x1000 = self.net(x)
x10 = self.dropout(self.relu(x1000))
x10 = self.fc1(x10)
x10 = self.output(x10)
return x10, x1000