跟踪工作Siam+时序
siamese框架分为了三个部件:特征提取模块、相关性模块、任务模块。
在训练中将其转化为相似性学习,所以只需要构建模板、搜索图像和对应任务模块输出的label即可。
在测试中还会涉及到图像裁剪尺寸、以及后处理模块。
我的思考:
1、回顾以前的方法,无论是单帧还是多帧记忆的时序建模方法,都缺乏对帧之间的建模,而最近提出的transfomer很好的解决了这个问题。我们进一步对transfomer结构进行解析,用于模板特征增强的部分,attention-map是nHM*nHM也就是说在空间和时间上计算的相似度。
2、今年的CVPR涨点都是transformer密集建模,如pixel层,还很粗糙,总体给我的下一步的工作感觉是关系建模。
3.每个视频序列的目标都有独特的尺寸信息,包括长宽比。
除了引入时序后,每个模板都会做resize,那么前景和背景都有变形,也丢掉了目标在视频中长宽比的变化;学习模板帧之间的联系,resize后再concatenate会不会引入特征对齐的问题,在空间pixel维度上。
motivation:
(背景):在线学习的方法通过复杂的效率低的优化方法导致应用场景受限,而最近基于Siamese的离线学习的方法在效率和精度上能够取得有效的平衡,所以拟采用基于Siamese的框架。由于单帧模板的信息有限,并且为了适应视频目标和背景的变化,在Siamese的框架也有很多利用时序信息的方法。
(分析):经过分析,基于Siamese进行时序关系建模的方法没有有效地利用前背景信息,大多只使用前景crop进行相似性学习,而抛弃了背景中有用的信息,导致模型在嘈杂或者变化复杂的环境下表现得不好,而背景信息对提高模型的判别力有潜在的帮助。
(现有方法):在线学习的方法在跟踪过程中通过采样正负样本学习一个更优的模型参数。最近也有一些基于Siamese进行时序关系建模的方法将背景信息考虑进来,但是应用都比较粗糙,有的通过加mask-label进行监督,或者收集负样本做线性减法,在嘈杂的背景下跟踪器表现得不好,还可以有很大挖掘空间。
总结起来就是:怎么有效地利用历史帧中前后景信息提高模型的判别力和泛化性?
(我们的方法):
1、前后景关系建模
2、历史帧关系建模
下一步:基于Siamese进行时序关系建模的方法有transfomer,用于模板特征增强的部分,attention-map是nHM*nHM也就是说在空间和时间上计算的相似度。首先进行时间和空间的结构,那么他对前后景都是pixel-level平等的对待,而缺乏对前后景的关系建模。再然后对时序上前后景的关系也可以进行建模。
实验部分:先跑一遍transformertracking,训一遍。
设计部分:先设计单帧的前后景关系建模。
方法一二分别在两个维度上,一个是前后景关系建模,另一个是前后景分离做匹配。
方法一:
1、背景和前景特征进行增强。选做部分是因为可以不用选点,这样就可以对每个点进行加强。
- 在所有pix中根据self相关性HWHW,对背景/前景的pixel求平均得到HW,选择相关性更强的前个点做代表。(选做)
- 对选择的pixel计算与区域内其他点的相关性。
- 对选择的pixel计算与区域外其他点的相关性。
- 反作用与区域内所有点。(选做)
2、时序上的交互,前面的方法不仅可以在空间上做,也可以在历史帧上做交互,当然也可以决定到底需不需要选点。

方法二:在自己做完增强后,用各个前景和背景分别对搜索图像作交互,再concatenate起来。(分别交互感觉很粗糙,是否有效需要验证)(可以和方法一结合起来,在整体增强后的前后景特征分别交互)

动机和方法再思考
动机:在目标跟踪中,绝大部分可观测的信息来自背景,如果利用背景信息,对跟踪性能有着很大影响。
早期跟踪主要使用生成式模型,不使用背景信息,直到判别式方法出现,跟踪问题成为了区别目标与背景的分类问题,判别式模型将背景当作负样本进行训练。
现有的深度学习方法一般采用判别式架构,又分为在线学习和离线学习的方法,在线学习在跟踪过程中利用目标和背景学习跟踪参数,而离线学习在跟踪过程中不更新参数,缺乏对背景信息的利用,对未知环境未知目标的适应性差。
目前比较热门的研究是孪生网络,其本质类似于相似性匹配,通过提取第一帧目标特征,对搜索图像做密集匹配。现有的基于孪生网络的利用背景信息的方法主要是抑制之前帧出现的背景信息,例如学习一个负样本记忆网络,但是抑制背景信息并没有充分发挥背景信息在目标跟踪全过程中的作用。近期也有一些方法将目标及其周围背景看作一个整体,线性乘一个高斯mask来潜在的利用目标与背景的联系,但是这些方法都缺乏在有效的监督下直接利用目标周围的上下文信息探索目标和背景联系,导致对未知环境、未知目标的适应性差。
为了进一步提高孪生网络在跟踪过程中的适应性,在建立目标和背景联系的基础上,还需要建立起时序上的关系。
比之前的说法:已经有时序上的关系了,但是缺乏目标和背景的联系。这里是直接说缺乏目标和背景的联系。实际应用上也是这样。
贡献:
1.提出了前后景关系建模的方法,利用背景信息辅助增强前景特征。
2.提出了目标和背景协同建模的时序模型,学习目标个背景之间的关系随时间变化的规律。
3.在实验上,取得了不错的成绩。
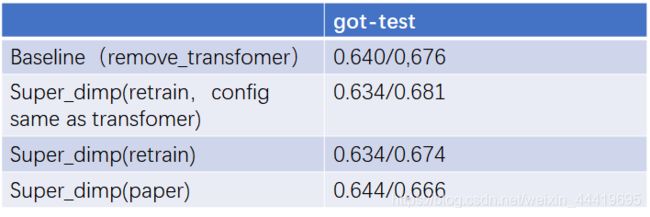
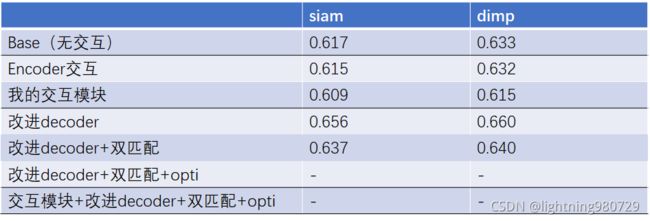
第一部分:对比baseline和原始版本的super_dimp

移开transfomer就是Baseline-SuperDimp,按理说应该水平差不多,实际上把差距拉开了,这是为什么呢,参数都是一样的。唯一的区别就是Super_dimp我要自己训一次看看。除此之外就是代码的问题,两者还有不同。
而且本身我的baseline训出来的结果就比原文好一个点,虽然原文的点和Super_dimp给的模型也不一样。
重要发现:训练参数不一致,原文把训练的batch_size改到40,samples_per_epoch,max_gap都更大。
下一部分工作:按bathc_size=40训Super_dimp。
在我跑的实验结果该不该这些条件都差不多,没有明显的波动,但是和Super_dimp放出来的模型还是稍微有区别。
也说明了作者对super_dimp基本没有大的改动。涨点确实是由模块产生的作用。
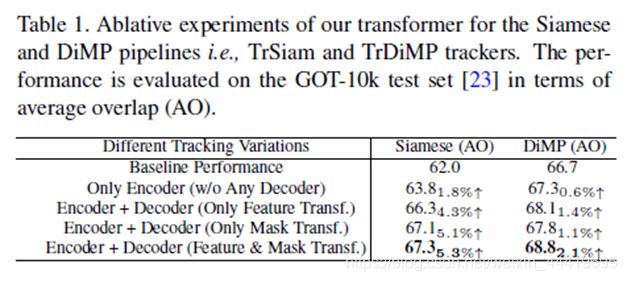
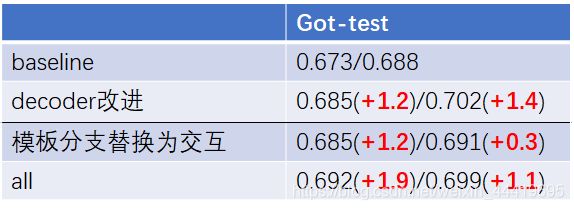
第二部分:原文的消融实验(探究encoder的作用)
论文的消融实验
我跑的消融实验:
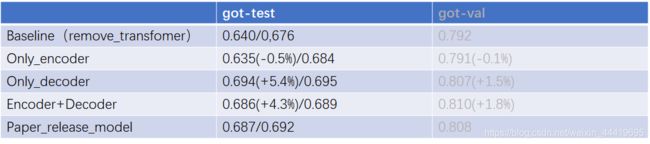
我补充了一个只有decoder的工作,原文没给,从这个实验看encoder的作用和原文不一致没有,在siam和dimp下表现不一致,但整体是没有太多的作用,反而可能掉点。原文只给了encoder和baseline的对比涨点也不多。
补充:为了统一结果,全部换成running_tracker.py生成结果提交官网,结果同一个模型涨点很明显,对比表格如下。

探究在线训练和不在线训练的区别(filter_upd),全部替换siamese,可以先和TransT的代码对比。
探究测试和训练不一致,测试过程中没有对encoder后的特征再decoder,可以在训练中去掉encoder。
结果发现是一致的,这是因为对encoder后的特征生成了memory,再decoder是为了初始化filter,测试过程中filter只用到了第一帧来生成,所以后续不再对模板进行decoder操作,而只保留了memory。
第三部分:改进baseline(和Transt对比)
1.学习TransT怎么转化为Siamese的训练结构,看代码,学习可以参考的地方。
2.重点研究classer是怎么取代的,这样就可以不做迭代了,和Dimp划分关系。
3.重点研究回归是怎么做的,是否比现在的ATOM好。
第四部分:改进encoder替换relation_encoder
前面说到自监督一点用没有。那么我就可以主攻这一点,提我的encoder有用的点。
实验:
对各个图单独的建立前后景关系,舍弃了时序信息。
1.1、不选点。
1.2、选点,先选每个区域选8个试试。
改进,除了各个图,还要把时序引进来,建立时序上的前后景关系。
2.2、历史帧所有前后景的点建模。
实验过程:训练方式提升了一个量级,用torch.where替换检索的方式。
结果如下:

整体感觉没有太大的作用。当然是对比实验设计的也不好。
结论:
- 目前的方式前后景关系建模没有明显的作用。
- 选top8导致性能下降。
- 加上decoder指标下降了,decoder部分是涨点的关键,需要联合重点研究。
后续改进:
- 只在有decoder下进行训练
- 分别对siam和dimp进行测试
- 不考虑top8
探究实验:加上decoder指标下降了

Ori_encoder loss曲线:

MIne_encoder loss曲线:

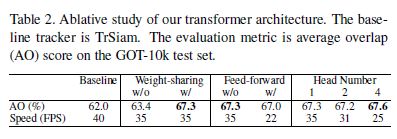
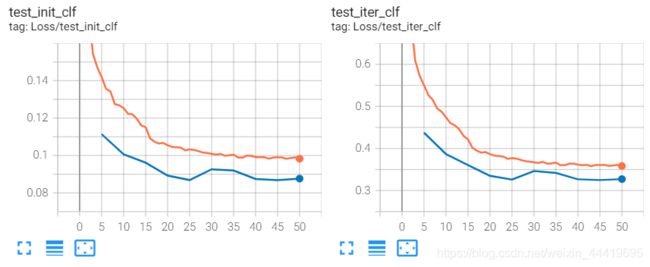
对比loss曲线,回归分支都收敛到了同一个位置,但是clf有差距,主要是init_clf有差距,说明加了encoder不好。
消融实验(都在有decoder情况下实验)
1. concat替换成加


在第40到50个epoch,init_loss上升,有点过拟合的征兆。
2. 单帧替换成多帧


多帧的前后景特征点更多了,这种交互越多反应在实验上效果就越差,也越容易过拟合,loss的波动更明显了。是因为选特征点或者结构设计不合理吗?
从上面的loss曲线上看都没有解决本质问题,还是应该从数据本身入手,去了解它的训练和测试图像是怎么生成的,为什么会导致loss的上升。
第五部分:对训练流程的研究
1.总的训练流程
分类和回归是两个分支,所以这里不考虑回归分支。
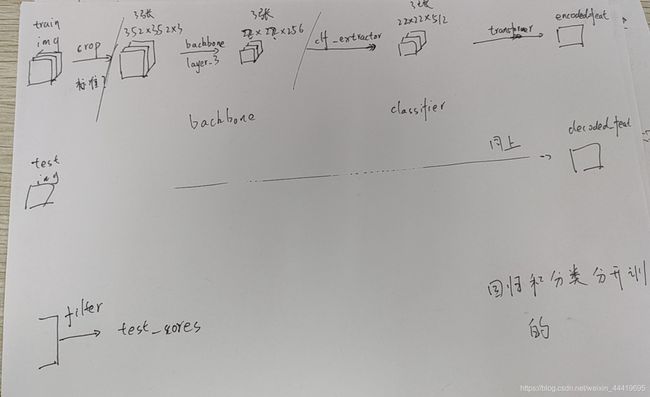
2.图像预处理
sampler复制从图片中读取数据和标注信息,没有任何处理。只是先选base_ids,然后再选择train_img和test_img的序号。
先统一转化为灰度图,然后stack成3维,随后按照一定的概率随机翻转。
crop:允许最大放大原图的1.5倍
对训练图像,scale_jitter=0.25, center_jitter=3,离目标中心最大3倍长宽的偏移,最后已这个bbox放大6倍作为crops图像。
对测试图像,scale_jitter=0.5, center_jitter=5.5,离目标中心最大5.5倍长宽的偏移,最后已这个bbox放大6倍作为crops图像。
transformer:转tensor,jitter brightness=0.2,随机翻转,正则化。
测试集:基本一致,只少了一些数据增强,每隔5帧测试一次。
感想:这个训练图像放大倍数为6,包含了很多背景信息,这也是super_dimp涨点的地方。但我这里需不要这么多背景,导致前景比例变小了很多,可能导致类别不平衡的问题。
3.特征提取
输入为预处理后的图片,分辨率为3523523。
- backbone采用res50,提取的是layer_3的特征,分辨率为22X22X256。
- clf_head采用res结构,分辨率为22X22X512。
4.transfomer_encoder
输入22X22,原来是在thwXthw做个self-attention

1完成了前后景特征相似分数的计算,具有指导后续特征重要性的意义。rcb部分没有提前用卷积指导。
2.完成重要性分数对初始特征的指导,并不断用前后景特征进行交互。
3.本质是计算比较重要的点之间的交互,但这里没有选点,所以还是所有点之间的交互,感觉有些重复。
4.利用前一部分的特征,完成对初始特征的增强。
5.transfomer_decoder

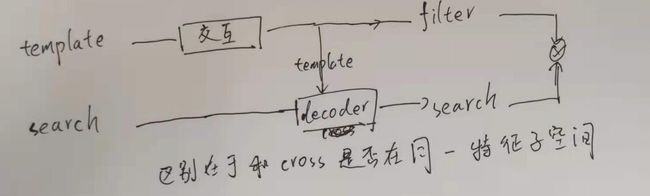
训练图像和测试图像都会过同一个attention模板,这是为了在做cross-attention之前都在同一特征子空间。
ins norm可以参考。
说明在做decoder之前保证训练图像和测试图像在同一特征子空间比较重要。这也是因为他们的图像所有参数基本是一致的,不像其他的siamese网络,模板会更小,可能不同的网络更好。
感想:1.一个重要的点就是需不需要保证训练图像和测试图像在同一子空间?不需要的话,就可以同时调整训练图像中目标的占比,调整训练头分开训。
2.目前看来encoder后面再加mask有带你重复,可以考虑改进一下decoder。
6.filter_init\update
init实际上是RrROlPool,在在所有图像上求平均。
update就是利用init_weigt在训练图像上计算loss,迭代五次。
7.final_scores
最后在测试图像上计算得分。完成一次前传
8.总结主要流程

从这个图可以看出在模板分支过了encoder之后还过了一次decoder,是否有必要?直观上需要的,因为这样才对前后景加mask进行监督了。
而且原文是和测试时保持一致,如果有新的图片,也会过一次decoder然后更新,所以模板分支后面这部分必须和搜索图像分支一致。
其实也可以改动,就是在测试的时候不能直接用测试图像decoder出来的特征,而是要重新走一遍encoder分支。
9.调整
1.网络上既然要动self-attention,那么必然涉及到两个分支特征子空间的不一致,所以clf_head网络结构最好要分开训,然后替换encoder部分的self-attention。其次我的前后景交互需要改进结构,加conv和减第4步。
2.是否需要简化decoder?encoder使用label监督了两次,是否会造成不稳定,直观上不会,因为就把训练图像当作测试图像过decoder,也会引入mask。如果简化的话,测试的时候,如果用dimp的方法,需要调整一下update,和测试时encoder部分保持一致。
接第四部分:encoder探究
1. cls_label对不对
对Roi-pooling和ROI-Align基本原理学习,避免特征无法对齐的问题。
之前抽取的前后景特征点没有考虑特征对齐的问题,存在较大的偏差,所以现在需要先做特征对齐,将前后景的特征前分离再计算相似rib,rcb。
参考ROI-Align或者将边界的特征点当作另外一类,分为前后景和边界特征。
实验过程中出现梯度消失的问题,原因是label生成的有误(没有label=1),主要原因是我写的方法没有考虑到:
1.边界是负数的情况
2.目标很窄,例如使用3:3是没有值的,
已修正,不考虑目标。
结果如下:


没有实质性的变化,loss还是降不下去,但也没有那种过拟合的现象。
思考,后面改结构是否可以修正一下,排除掉框在外部的训练数据,这样就剔除了脏数据。这个是对第三部分原始框架的改进。
2.对结构的改进,是分支头的问题
前面分析了encoder是为了确保训练和测试数据在同一特征子空间,为了替换掉encoder,引入前后景建模的事项,所以将前面的卷积头不共享权重。
同时在encoder结构上剪掉了冗余的第三部分。
根据不共享权重的部分,一共训练了三组:

结果如下

0.ori_encoder

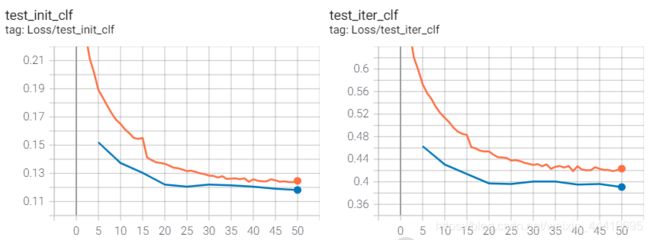
1.encoder-decoder head
实验结果最高,但siam情况不好。loss也没有下降到比较好的位置。
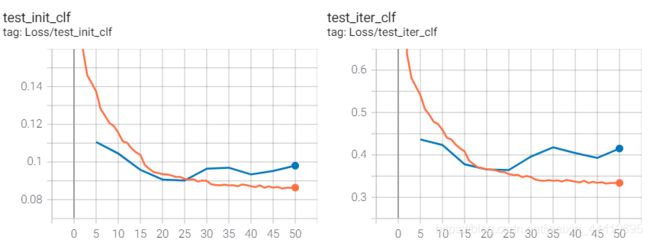
2.train-test head
结果不好,loss上看有点过拟合了,train_loss降到了很低的水平,但是val_loss却在上升。
3.Trihead and train-test decoder head
其中第三组收敛的结果最好,但是测试结果还没有第二组好,没有达到理论的水平,需要进一步研究。
检查了一下流程,没有错误,就是更加复杂了,encoder直走encoder-head,train_img走train_img-head,然后走decoder-train,再过filter,test_img走test_img-head,然后走decoder-test。

对比原始的dimp:
最终的loss位置都差不多,收敛的比较好,除了test_iter_clf稍微高了0.015个点,其他loss都一致。
但整体上看在0-10个epoch存在震荡的现象,在第40-50个epoch下降很平缓。
4.加上时序

40个epoch时val_loss出现了一个震荡,但是不影响,在45和50个epoch属于正常。结果基本上和不加时序一致。
3.补充实验:对训练数据的改进
时序上目前loss下降情况不是很好,我认为是由于数据前后景的数量不平衡导致的,所以可以将训练数据的放大比例缩小。当然还要评估这样对训练数据的影响,例如生成filter的影响,可以先减小区域在v1上试一试。
1.生成新的有待crop的jittered_anno时,减少偏移量。保证目标在视野范围中。例如TransT全改为0,都在中心。
2.训练图像改为目标的3倍,但尺寸还是和训练图像一样为352。
3.测试时,添加params.template_area_scale = 3,修改self.init_sample_scale(第414行),就完成了初始模板的修改。
4.测试更新时,需重新crop和生成bbox指引生成scale=3的模板更新。

结果还较差,还要看看测试时是否有问题,可以看一下loss
1.ori_encoder上加改动
loss收敛的还可以,虽然val-loss高了一点。
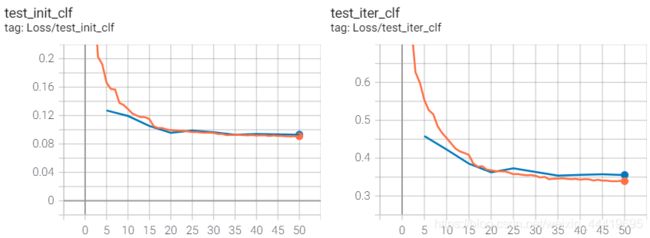
2.mine_encoder(trihead and duel-decoder)上加改动
也还可以。
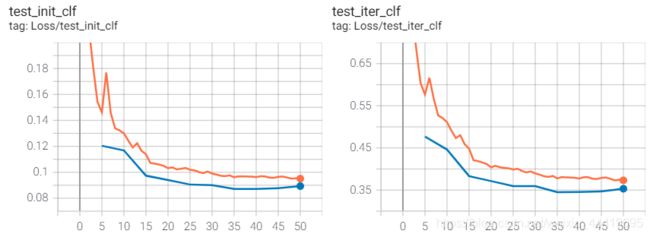
loss看起来都还可以,我怀疑是测试的部分哪里出现了问题。
除了分类的loss,修改模板尺寸还对回归的loss加粗样式造成了影响,变得更高了。
4.补充实验:对是否采用dimp在线更新的探究实验
在后面实验结果上看,init_loss的结果就很好,使用了更新之后反而结果表现得更差。
那么在训练时,是否还需要进行迭代就可以进一步研究。

不利用在线更新siam结果也下降了
接第四部分:探究不tri-head和train-test-head
1.tri-head结果不好的原因
目前情况是loss下去了,结果不好。
说明训练是没有问题的,那就只有测试时可能出现问题。
- 第一:检查不同epoch结果是否一致

在第45个epoch最好,但是dimp普遍也都不高。即使可能存在波动也很难上到0.68。
测试第45个epoch的波动性:
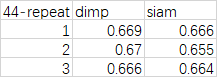
结合最开始的结果差距还挺大的,为什么波动这么大?是因为还是要测三组吗?

dimp分数更高了,但还是有一定的波动性。
打算拿GOT本身的模型试试。
结果仍然一样,都差不多,表现得不好。
- 第二:流程是否正确
检查了一遍,没有问题,保持和测试时一致。
- 第三:数据是否正确
检查更新时图像和bbox和cls_label是否对齐。
有一个问题,在于生成cls_label没有使用深拷贝,导致在初始化时filter有偏差。
所有的v2、v3、v4、v5都要重新测试。
- 第四:表现较差的结果是哪些,对这些做一点可视化,或者放入val集
结论
测试时由于target_box没有深拷贝,导致后面生成filter的位置出错,所以初始化结果很差,之前几个重要的消融实验都是重新测试的。


再测试波动性

没有提升。
2.train-test-head
思考:
tri-head和train-test-head对比:
虽然train-test-head的train-loss降得很低,但是val-loss一直在上升,tri-head的val-loss收敛更好,但是结果表现得更差,只有可能是这样训练出来的泛化性能较差,在train数据集上过拟合了。
那么可以比较一下两者在val集上是不是tri-head更好。

结果在val测试集上,traintesthead表现得比原来的文章的self-attention好,有1%的提升,但是在test测试集上点不高,但从结果上来看是泛化性不高,可以再在其他的数据集上测试一下。
1.虽然val-loss没有收敛,但前面已经在got10k_val数据集上验证了方法的有效性,下面在更多的数据集上进行测试结果如下:

在trackingnet数据集上有所涨点
2.疑惑:traintesthead的train-loss降得更低,但是val-loss还是飘得,怀疑是震荡的原因,再重复训练实验。

重复训练后的loss曲线如下:
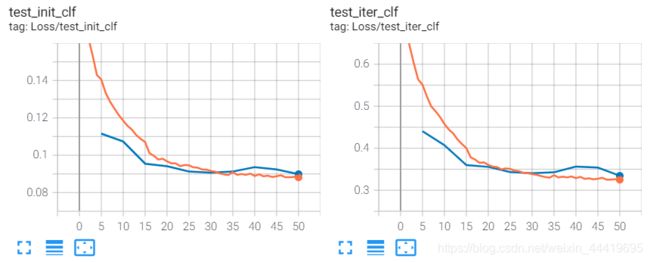
和之前的大差不多,val稍微平稳一点。
3.train-test-head-decoder
改进加入train-test decoder

loss也降得足够低,基本和不区别decoer的一致,并且val也表现的很平稳,但是在test数据集上实验结果没有不区分decoder好。和loss曲线表现的不一致。
思考,loss曲线好像不是很有指导意义,总是出乎我的意料。
4.消融实验

5.训练不迭代会对siam的结果有影响吗
结果如下

loss曲线如下:
6.加时序

loss曲线如下:
接第四部分:基于RANET改进train-test-head encoder
RIB:计算attention_table,在特征图2222上计算每个点的相关性,本质上就是self-attention中key-value的点乘,最后的尺寸是484484。计算过程是,先在维度上过一个mlp生成key-value,同时也完成降维,然后点乘,最后过一个softmax。
怀疑attention_table是否有指导意义,做个可视化。
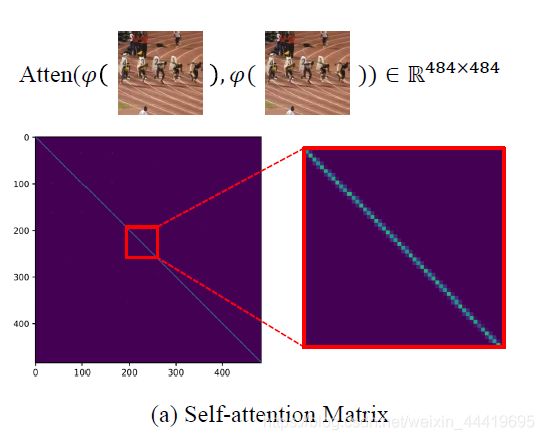
我测试结果和论文一致:

我的attention_map学出来的可视化:

可以说获取的有用的信息很少。
RCB:前后景区域的相关建模。
首先从attention_table和foreground_tables,区分前后景的相似性,只计算各个点对同一区域点的相似性,做累加,得到各个点在区域内重要性,得到代表性分数representative_score。
然后就是将特征点乘相似性分数(反复4次),之后过一个卷积,相当于各个点通过重要性进行了加权。
将加权后的分数点乘相似性分数,再和初始特征进行反复点乘,最后再过一次卷积。
其中的反复点乘是为什么?需要深入理解RANet的公式。
1改进attention_map生成方式
一开始是我拍脑袋自己想的,所以结果看上去很差。现在应该完全参照self-attention的方式生成。
完全参照self-attention只有在temporal下可以实现。
结果同上:

下面通过直接调用RANet的生成方式,(主要解决了之前无法导入cuda函数的问题)
通过可视化可以看到attention_table有比较丰富的信息了
但结果仍不好,怀疑是后面需要调整两点因素,一方面是RCB的结构,另一方面是RIB和RCB的学习率。

总体来说,改进RIB的实验,主要是先对attention_map的生成方式进行了改进,呈现出如图所示的效果,但是从实验结果上来看,导致loss上升,实验结果也不好。所以是一个负反馈。
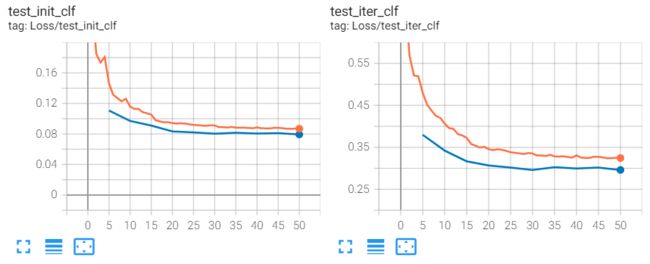
init_clf_loss橙色的train线最后是0.14,而原版的在0.088左右,所以收敛结果不理想。

2改进后续RCB点乘
在RIB和前面一致的基础上,RCB的结构保持和RANet一致,结果如下

可视化图:

loss曲线如下:
相比于前一阶段的成果,这里是比之前做的了正反馈。
尤其是val_Loss蓝色的收敛比较好,保持在橙色的trian_loss下面。但是橙色的train_loss比原版还是高0.01个点,但val_loss差不多。
思考,在原版和现在RANet的版本中学习率是否要精调以去的好的结果。
下一步,将负反馈的RIB去掉,看看直接上原版RCB会不会更好:
3不改attention_map生成方式,直接加原版RCB
结果如下:

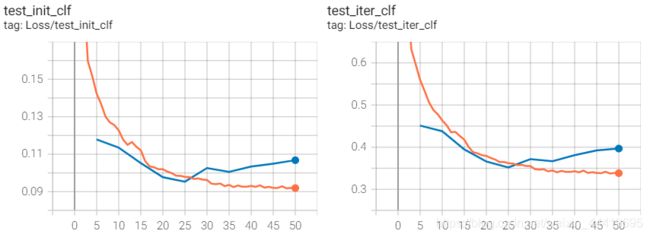
val_loss开始上升,但是train_loss收敛的更好,主要表现在iter上面。但是train_loss在init上表现没有最开始的train-test-head好,而且val-loss没有下降了。
结论:改进RIB可以让val-loss不上升,但是会让trian-loss下限升高一点点,导致结果变差一点点。
在前面三组实验中,只有RIB和RCB结合的第二组实验最接近baseline,可以调整。
8.使用原版Vcount
不做其他的改进,只将vcount替换成RANet的方式

依旧不痛不痒
9.回归train-test-head 解决过拟合的问题,调整超参(同下)

结论:不理想,本质上还是模型的问题
第六部分 对decoder的研究
6.1decoder分开匹配前景和后景(直接在baseline上面实验)
先对decoder具体作用进行研究
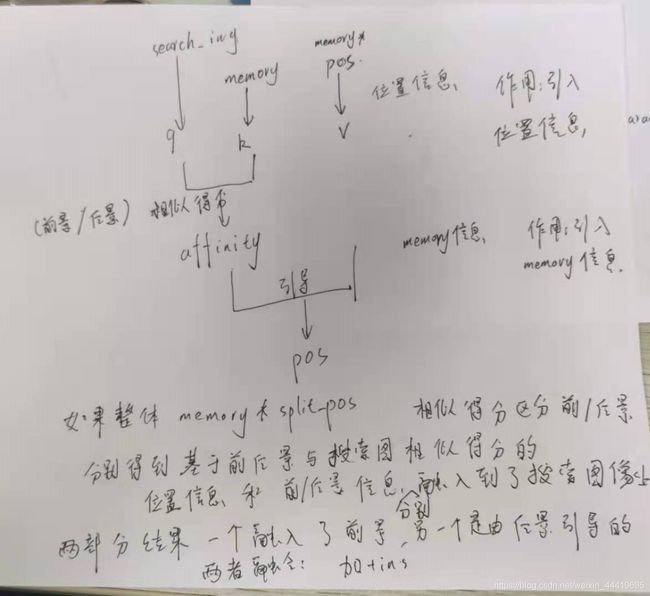
只需要在特征层面乘上mask和(1-mask)就可以区分然后再分别匹配得到结果。
原来时通过memory可以直接生成decoder_feat,现在memory*label可以只传导前、后景的特征值引导生成decoder_feat,所以生成两部分。
下一步的工作是需要进行融合
baseline的loss曲线:
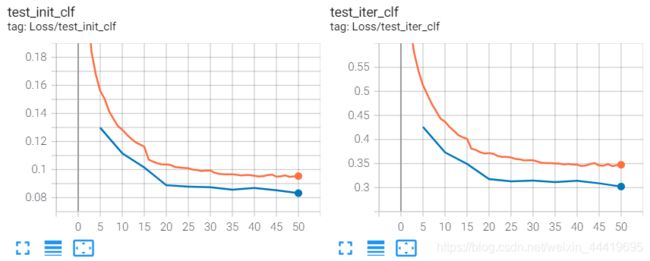
方法有add,结果如下。
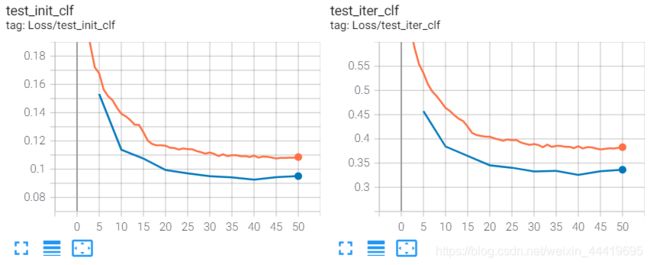
方法有concat和conv降维,结果如下。

还可以引入前后景信息指引,前后景像素点通过avapooling生成通道级权重,对decoder_feat加权,之后再add和insnorm,或者concat和conv降维。

总体结果上来看,conv比add好,加入attention后,loss比baseline更低了。

实验结果不如人意,loss虽然低,但是结果反而更差了,需要进一步研究,过拟合的原因。
从来loss看唯一不合理的地方就是train-val-loss两者差距比较小。
Plus:最后再加上原特征形成一个残差连接的结构。
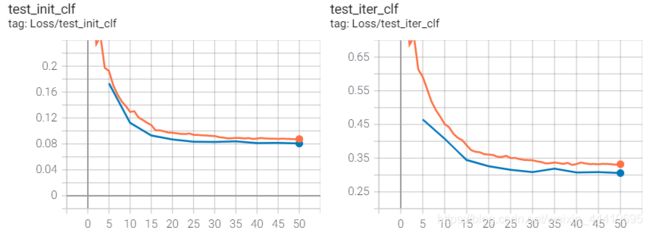
loss降得更低了。
重要分析
在对训练做改进前,应该分析结果为什么有所反差。
baseline和superdimp的训练方式没有差别,所以训练是没有问题。而baseline最大的区别就是训练时完全没有考虑多帧,但是在测试的时候可以利用多帧的时序信息,所以就会涉及到超参的问题。
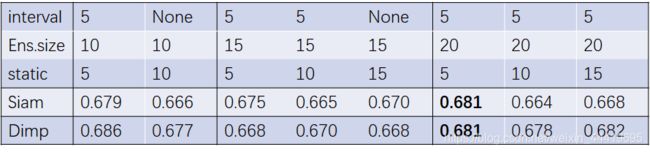
虽然我的设计loss降得更低,但是对比原文的消融实验和我自己消融实验可以看到,原文的方法可以有效地利用时序信息,所以在间隔为5更新模板能取得最好的效果。


我的方法在不更新时取得的结果是最好的,说明更新引入的模板会引起错误累计的后果,损害了模型的性能。
进一步分析我的对比实验可以看出,interval越大越好,因为这是趋于不更新是结果是最好的。size整体趋势也是越大越好。
下面就要针对错误累计的改进方法
-
测试时引入静态的模板,即保留一部分不更新模板。

从不更新的结果来看,增加静态模板数量提升空间并不大。
需要保持一定的更新模板的比例很重要。 -
筛选更可靠的模板:

结果都不是很好。 -
前景区域扩大,引入部分背景信息,提高误差的包容性。
loss如下,相比之前有所提升。
-
训练时引入噪声(center_jitter),中心的偏移噪声。
loss如下:
相比只加入尺寸的扩大,loss升高的更加明显。


结果仍旧不好。
对输入数据的探究
之前的文章对训练数据的采样间隔有所不同,所以这里设置了4组不同的值进行对比,结果如下。
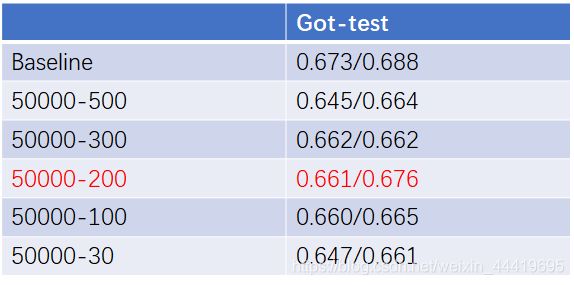
从loss曲线上看,间隔为100和30时最低,但是结果最差,这是因为test也是间隔比较小,更容易过拟合。但是200的loss结果并不好,目前结果最佳,当然也可能是由超参数共同影响。
这也说明loss下降,但是实验结果不好,其实loss不管上升或者在下降,本质上并没有较大的差距,有可能只是模型变大了,lloss降得比较低,但是测试并不见好。
完成的对比实验
1.50000-200的几组对比试验

2.jitter_center0.25_size1.5的几组对比试验
3.addnorm模型的对比实验

在其他数据集的测试

结论
做的几次实验表明结果都不理想,甚至重复实验结果都下降了。
不在这个模型上面继续研究了,我猜想的还是因为模型变复杂了,所以导致loss下降,但是测试并不好。
本质上还是模型设计的不科学。
第7部分 decoder再改进思考怎么和前后景融合
decoder需要进行大调整,不能把base的mask也融合混杂在一块。
思考每一部分的作用,decoder分为了两部分,feature transformer和mask transformer,这里不应该影响mask transformer,因为它的作用是预测下一帧目标的位置。
我这里本意是对前后景做特征上的加权,所以应该把feature transformer拆分为两部分,所以将其mask改为前后景的mask,从而实现三个分支的transformer。
原本是高斯核加权交互的feature transformer,原先乘mask是为了镇压模板背景,相当于舍弃了背景信息,我这里直接利用起来。一部分提高前景的响应,另一部分抑制背景的响应,最后再三个分支add_norm。
7.1.同一个corss-attention模型参数实现tgt = tgt2 + tgt4 - tgt6
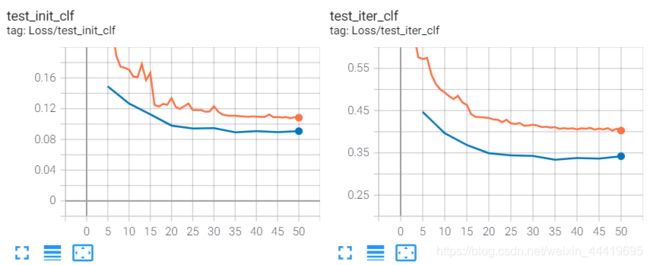
loss不是很好
7.2.不同的corss-attention模型参数实现tgt = tgt2 + tgt4 + tgt6

这个工作的loss看起来还可以
疑惑之处在于计算corss-attention,query是搜索图像,key是模板图像,value是模板图像乘mask。相似性矩阵是query*key,value才是加权后的相似性矩阵点成的对象。
我这里就是搜索图像和前景计算相似性,然后加权作用在整个模板图像上,得到前景和搜索图想的共同影响的模板图像,背景功能同理。得到加权的模板图像再和搜索图像相加得到更关心的权重。
那么重要的就是key和query的相似性计算,这里将前后景区分开了。

调节超参


涨点了!!!!!!!
7.3在decoder内部再引入instance-level attention
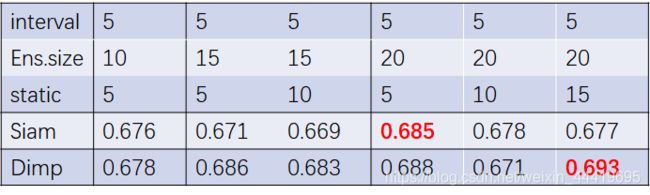
结果没有进一步的涨点,反而掉了,还需要再思考一下如何接入涨点。
loss稍微低了一点点,几乎可以忽略不计。
7.4 由于0-1的label会引入不确定性,且缺乏空间信息流动,所以在decoder部分换回原来的高斯label,
然后新增的那部分取反,多一个分支。
结果loss稍微低了一点,预计比原来结构还要好。

总结:改变的decoder比较有限,但是验证了有效性。
大的框架没有变,需要思考怎么和另一部分工作联系。
baseline做过的实验都可以验证,比如原来去掉encoder能涨点。
第七部分 思考各个部件的结构和关系
首先,我们只对分类分支做改动。
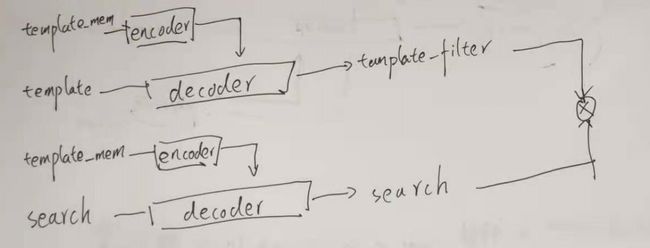
第一部分encoder完成模板图像的编码,为了在decoder做cross-attention在同一特征子空间。
第二部分模板和搜索图像经过decoder,本质上是一样的,这是为了在做互相关的时候也都在同一特征子空间,同时也为了后续在线更新的时候不需要做太多的改变。
其实训练和测试是这个图
改动1:确定有涨点的实验,decoder内部的分解,但是外面的所有结构都没有被打破。
改动2:encoder改动被我换成了bf_relation,那么在decoder内部cross-attention就不在同一特征子空间。
思考:
1 train-test head的作用,那这就把后续做互相关操作的模板和搜索图像分支在同一特征子空间破坏了,并且测试时没有简化了。
2 template分支decoder作用,既然都是自己和自己交互加mask,是不是可以直接替换到我的前后景交互分支。
3 search分支decoder作用,首先self-attention作用,前面说是为了在cross-attention在同一特征子空间,那么模板分支去掉了,搜图分支还需要保留吗?
之前的实验是
这样破化了decoder内部统一特征子空间结构。有个问题在于生成filter交互了两次,如果去掉template decoder就是下面的idea2
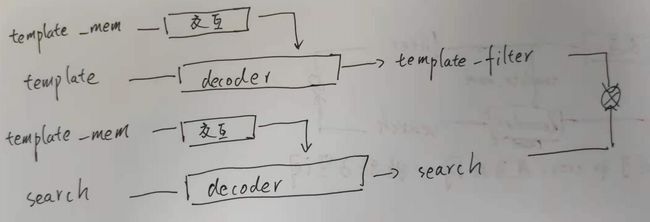
下面看idea1和2:
idea1、2区别在于要不要保留原有结构
idea1:保留原有在search分支的结构,encoder不变。
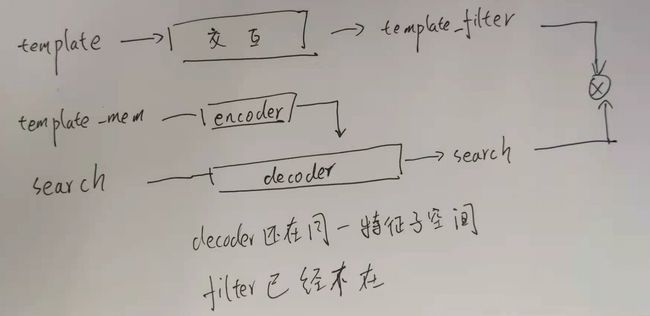
idea2:filter和mem都在加权了前后景信息之后和decoder交互。
第四部分: 针对encoder改进大的结构位置
1.按照idea1改进


两种结果对比下,还是ranet的结构更优,但是本质上涨点还是不明显。
2.按照idea2改进


idea2的实现结果普遍更差一点,怀疑模板在过完上下文交互后,再进入decoder对原有的特征空间破坏比较厉害。
总结:这两种大的结构,从loss曲线上看,都没有很显著的下降,感觉总体作用还是比较有限,需要进一步修改模型,可以直接核前面的decoder的改进放在一起再做改进了。
第八部分:融合两个模块
整体结果。
从loss来看,引入模板上下文交互的模板,反而有点拖累了原decoder的表现,原因还是模板1的网络结构设计不合理。一方面可以说是label的不准确导致的,有没有办法也用高斯mask来代替呢?另一方面,结构上,那些点乘运算还能不能坐进一步的优化。
难点还是在于模板分支,引入上下文信息和模板进行交互是否有帮助?
对上述问题的思考
1.原结构本质上也是对模板分支进行了前景加权的,只是文章中没有提到。我改进decoder后,两个分支都融入了前后景的注意力。
2.我的前后景交互模块和decoder相比,其实本质上差不多,只是方法上有些微的差别,想要改进很难绕过去一个问题,你为什么不用decoder来进行前后景交互。我可以说我将背景信息引入到前景特征中完成交互,是我的贡献点,但我的方法为什么不用decoder?不好解释。
所以前面的消融实验,后面两个才是整体结构的一致。

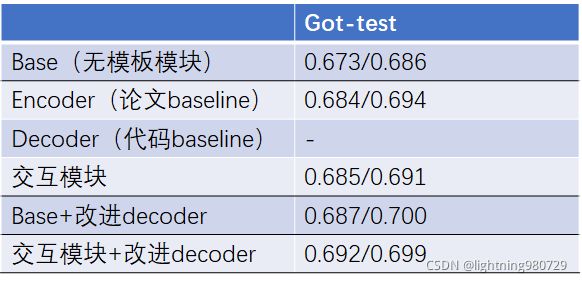
模板分支引入前后景交互模块到底有没有效果:
对比试验:在现有结构的基础上,搜索图像分支继续encoder、decoder。
1.模板分支不进入任何模块,直接进入直接进入filter。(验证用decoder或者bf_relation的有效性)
2.模板分支进入encoder(即baseline’论文’+decoder的改进)
3.模板分支进入bf_relation(总的实验)
4.模板分支进入encoder、decoder(和bf_relation的对比试验)
搜索图像分支引入
1.baseline‘论文’
2.baseline‘论文’+decoder(改进)
3.总的实验
4.总的框架+模板进如bf_relation
总结:
在整体框架做了改动的基础上,基于base所作的消融实验结果上,增加交互模块、改进decoder都取得了涨点,但两部分效果整体没有太大的提升空间。
在交互模块的对比实验没有体现我的方法比encoder的优越性
第八部分 从头开始
首先比较了一下两种不同的框架,虽然论文中的结构是

实际上是
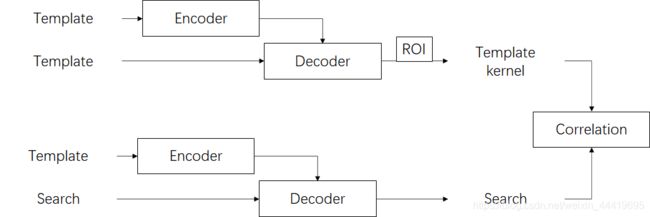
需要注意:模板一共有两个作用,一个是生成kernel,另一个是生成mem。
经过分析,还是应该按照原文的结构的结构来进行改进,提出了v15,也就是上图1的框架,只是把encoder换成了bf_relation,后面生成kernel和mem都单独再过一个卷积。
PLUS:改进匹配机制:
1.提取前景特征是通过ROI,后景特征额可以通过相似性计算得到代表性分数选topk个点。
2.将相关计算替换成concat,引入mask分别抑制前后景
结果很差很差,即使是换了训练数据集,对比sota也比较低。
后面探索了一下框架的因素。


结论:框架二的方式影响很大,低框架一2个点。

想得两个匹配策略,也都造成了明显的降点。
第九部分 回归idea1
改进bf_relation模块,结果都不好。并在decoder添加了一个对比实验

第十部分 回归原文baseline框架(v18-v19)
基于原文的encoder,类似position_embeding创建一个类别相关的embeding融合前后景信息完成全局的交互.
后面还有不同的head来改进,但是过拟合严重,loss都收敛的比较好。
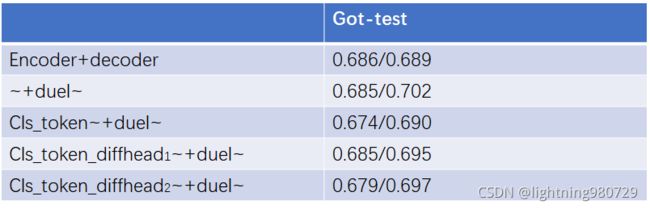
后面还针对decoder进行的了增强,用cls-token的方式,在v14上面。
第十一部分 回归idea1并总结(v20)
首先要完成所有的消融实验。
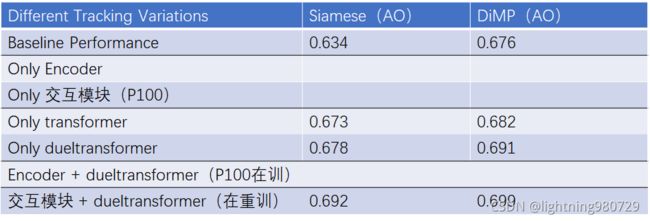
其次最终版只在got上的实验也要重新训。
然后,是所有数据集的实验。
论文:
1.卖点:利用背景信息-主流的Siamese方法抛弃了背景信息,这是Siamese离线学习的相似性匹配,利用背景可能引入噪声,在线跟踪的方法通过将背景作为负样本进行训练的方式,能够学习更鲁棒的特征,更好的适应视频所在的域。
2.但是在线学习的方式通过迭代反传会消耗大量的计算资源,所以在推理过程中利用背景做特征增强。
现有的方法在两个分支提取特征,所以各自有不同的特征增强的方式。
第一:模板特征大多利用时序信息做增强,结合历史帧或者光流信息,或者采集背景中的难负样本,和模板特征做线性求和或者残差连接,这种方式通过人工设置阈值的方式筛选负样本,较复杂无法进行端到端的训练,而且没有利用目标周围全局的上下文信息,效果不好。
第二:搜索图像特征大多利用空间上的变化抑制背景信息,或者近期比较火的transformer进一步融合模板特征,,但是都没有同等的对待背景进行交互学习
3.所以我们的方法能够充分利用背景信息,通过在两个分支提出的特征增强方式,实现端到端的学习。
第一:模板,我们采用了一个更大范围的模板特征没包含更加丰富的背景信息,通过划分前后景区域的方式学习代表性分数进行区域内外的交互学习,得到更加鲁棒的模板特征,用于生成匹配时的卷积核。
第二:搜图,我们采用现在比较transformer结构进行注意力学习,通过同等的对待前后景学习两部分的注意力。
4.实验结果证明了:
引言:详细介绍
1.视频跟踪任务难点和挑战(往背景信息上引)嘈杂背景、相似干扰物
2.引出离线学习的方式为什么和在线学习的差距,现有的离线学习方法缺乏对背景信息的有效利用,这是由于离线学习是通过相似性匹配的机制导致的,在提特征是只需要提取目标特征即可。现有的一些方法利用背景信息主要通过特征增强来实现,两个分支上一个生成kerenl,另一个生成搜索图像。
3.所以本文在模板分支,相比于本文的baseline,也用到了更大区域,但这是为了和搜索图像保持同一尺寸,并且为了在同一特征子空间下进行注意力学习。并且encoder的目的是加强跟踪过程中历史帧时序上的联系,这和只能利用第一帧生成更鲁棒的卷积核参数作用不同,所以本文也将其解耦开来,在第一帧生成参数的时候使用交互模块,在跟踪的过程中,利用encoder增强时序信息。不同的本文的baseline进行模板特征加权,这种像素级注意力方式可能也能构建像素之间的上下文关系,但是这种无监督的方式可能由于数据之前的关系引起网络的错分,所以本文引入了一种全新的前后景交互模块来实现模板特征增强,提高特征的鲁棒性。具体来说,我们在模板上建立起前后景区域之间信息交流的通道来增强整个图像上的像素的特征。
4.再说搜索图像分支,不同于之前的方法仅仅使用前景特征来进行嵌入学习和匹配,我们认为背景也应该被同等的对待,因此利用transformer decoder结构提出了对背景信息的注意力学习,并且通过相关性选出具有代表性的背景像素和搜索图像做匹配。
5.贡献:
1.提出了一种全新的框架,能够实现背景信息的充分利用。
2.模块1
3.模块2
4.实验
相关工作:
跟踪:
离线:特征增强手段
在线:
attention 机制:
方法:
1.框架流程
2.模块1:
代表性分数、区域内外内三层交互
3.模块2:
transformer结构图