【树莓派】基于树莓派的语音机器人
一、 概述
智能语音设备在生活中越来越常见,如智能手机(Cortana,Siri,Ok Google)、智能家居设备(Google Home,小米AI音箱),交互式语音应答设备(银行,应答机),语音机器人(电话机器人、客服机器人、电销机器人)。
众多语音交互设备采用同样的流程如下图:语音识别把人发出的声音转换为文字,经过自然语音处理得到意图,再输入数据库获取回答的文字,经过语音合成就能实现语音对话, 而后续这些功能可通过调用API来实现。

API(Application Programming Interface,应用程序接口)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问原码,或理解内部工作机制的细节。而图灵机器人和百度人工智能平台为我们提供了丰富的免费接口。
二、 系统架构
流程在树莓派上的体现是这样的,把录音的对话发给百度语音识别,它返回文字再发给图灵机器人,图灵机器人比对自己的数据库,再返回回答的文本,把文本经过语音合成后保存到本地,然后把它播放出来,整个流程是线性流程

物件清单(BOM):
- USB摄像头———1
- 树莓派—————1
- 音响——————1
三、 开发流程
1.准备对应应用程序编程接口API
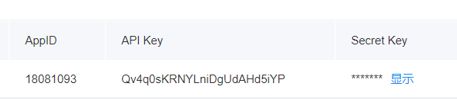
注册图灵机器人账号和百度语音识别账号获取API KEY
- 百度大脑:https://ai.baidu.com/
- 图灵机器人:http://www.turingapi.com/

2. 测试树莓派录音功能
采用树莓派自带的arecord来录音,16000的采样频率,保存为test.wav
arecord -D "plughw:1" -f S16_LE -r 16000 test.wav
其中,-D参数后接录制设备,连接麦克风后,树莓派上有2个设备:内部设备和外部usb设备,plughw:1代表使用外部设备。-f表示录制的格式,-r表示声音采样频率。由于后面提到的百度语音识别对音频文件格式是有要求的,我们需要录制成符合要求的格式。另外,在这里我没有指定录制的时间,它会一直录制下去,直到用户按下ctrl-c。录制后的音频文件保存为test.wav。
若耳机没有声音,则:
sudo raspi-config
找到advanced options>audio
设置成3.5mm接口
3. 调用百度语音识别的API进行语音识别
流程基本就是获取token,把需要识别的语音信息、语音数据、token等发送给百度的语音识别服务器,就能获取到对应的文字。
文档见:https://ai.baidu.com/ai-doc/SPEECH/6k38lxp0r
源码:asr.py
此部分为百度注册API。
client_id = "Qv4q0sKRNYLniDgUdA*****"
client_secret = "tX0SYY01H8sR3jhcl4*****"
# coding: utf-8
import urllib.request
import json
import base64
import sys
def get_access_token():
url = "https://openapi.baidu.com/oauth/2.0/token"
grant_type = "client_credentials"
client_id = "Qv4q0sKRNYLniDgUdA*****"
client_secret = "tX0SYY01H8sR3jhcl4*****"
url = url + "?" + "grant_type=" + grant_type + "&" + "client_id=" + client_id + "&" + "client_secret=" + client_secret
resp = urllib.request.urlopen(url).read()
data = json.loads(resp.decode("utf-8"))
return data["access_token"]
def baidu_asr(data, id, token):
speech_data = base64.b64encode(data).decode("utf-8")
speech_length = len(data)
post_data = {
"format" : "wav",
"rate" : 16000,
"channel" : 1,
"cuid" : id,
"token" : token,
"speech" : speech_data,
"len" : speech_length
}
url = "https://openapi.baidu.com/oauth/2.0/token"
json_data = json.dumps(post_data).encode("utf-8")
json_length = len(json_data)
#print(json_data)
req = urllib.request.Request(url, data = json_data)
req.add_header("Content-Type", "application/json")
req.add_header("Content-Length", json_length)
print("asr start request\n")
resp = urllib.request.urlopen(req)
print("asr finish request\n")
resp = resp.read()
resp_data = json.loads(resp.decode("utf-8"))
if resp_data["err_no"] == 0:
return resp_data["result"]
else:
print(resp_data)
return None
def asr_main(filename):
f = open(filename, "rb")
audio_data = f.read()
f.close()
token = get_access_token()
uuid = "1000"
resp = baidu_asr(audio_data, uuid, token)
print(resp[0])
return resp[0]
#words=asr_main("test.wav")
#print(words)
4.将百度语音识别返回的文本发送到图灵机器人
文档见:https://ai.baidu.com/ai-doc/SPEECH/hk38lxjye
树莓派安装相应库文件:
树莓派安装语音识别 Python SDK,对应Python2或Python3安装
Pip3 install baidu-aip
或
Pip install baidu-aip
通过发送Post请求获取图灵机器人返回的回答。
源码:robot.py apiKey部分为图灵机器人注册API。
import requests
import json
def robot_main(words):
url='http://openapi.tuling123.com/openapi/api/v2' #服务地址
params={
'reqType':0,
'perception':{
'inputText':{
'text':'' #询问的文本
}
},
'userInfo':{
'apiKey':'ef5c5039fe804f0d974910*********', #使用你自己申请的
'userId':'ROBOT'
}
}
params['perception']['inputText']['text']=words
response=requests.post(url,json=params)
#print(response.text)
answer=json.loads(response.text)
return answer['results'][0]['values']['text']
#word_robot=robot_main('Hello')
#print(word_robot)
5. 将图灵返回的文本发送到百度语音合成
文档见:https://ai.baidu.com/ai-doc/SPEECH/Gk38y8lzk
源码:tts.py 红色部分为百度注册API。
from aip import AipSpeech
#""" 你的 APPID AK SK """
APP_ID = '18081**'
API_KEY = 'Qv4q0sKRNYLniDg****'
SECRET_KEY = 'tX0SYY01H8sR3jhcl4******'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def tts_main(words):
result = client.synthesis(words, 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
#tts_main('你好')
6. 集成到MAIN程序和采用脚本调用
源码:main.py
import asr
import tts
import robot
words = asr.asr_main("test.wav")
print(words)
new_words = robot.robot_main(words)
print(new_words)
tts.tts_main(new_words)
集成到脚本中,采用树莓派自带的omxplayer播放合成的语音
源码:start.sh
#! /bin/bash
arecord -D "plughw:1" -f S16_LE -r 16000 test.wav
python3 main.py
omxplayer -o local test.mp3
使用方法:
运行脚本start.sh录音
Ctrl+C结束录音
四、 总结
这个项目虽参考了网上一些案例,真正自己编写的代码量虽然不是很多,但是要求看懂官方的技术文档,要求懂得如何结合课程所学的语音部分和Python编程能力才可进行成功调试,但出现问题时需要有合适的排查手段,找出硬件或者软件上的问题。通过这次项目,相信能够获益匪浅。而做到的语音对话还只是基础,后期可拓展为语音控制灯的开关,利用树莓派强大的功能做智能家居,或者采用Qtpy5做界面,通过声音大小实现唤醒等,实现更便捷的使用体验等等。
– 以上,这是博主课程作业,仅此分享一下。