人工智能(Artificial Intelligence,AI )计算的路线
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
1993年,当黄仁勋等三个电子工程师在加州圣何塞的一家餐馆碰头准备成立一家图形处理芯片公司时,他们还不知道20年后,他们做的这个芯片还能用来做人工智能、自动驾驶。
1985年,Xilinx创始人之一Ross Freeman发明FPGA芯片的时候,他也不会想到近30年后,FPGA芯片会被广泛应用于人工智能领域的计算。黄仁勋还能亲自带领NVIDIA参加人工智能芯片大战,而Ross Freeman在1989年年仅41岁就因肺炎不幸早逝。
目前人工智能的产业重心,已经从早期的深度学习算法和框架,转到了AI硬件平台。Google开发出专用的AI芯片——TPU,如下图。

可是,另一个巨头微软却全面拥抱FPGA作为AI计算平台。同时,亚马逊和百度也是FPGA路线。百度在一个电路板上集成了CPU、GPU和FPGA,称为“XPU”。亚马逊的云服务提供F1加速平台,提供FPGA计算加速。
微软为什么选择FPGA
下图是微软的FPGA扩展卡,叫做DPU,“Soft DNN Processing Unit”。

微软FPGA战略是成体系的,包括三个主要部分:
1. FPGA扩展卡能够互联、扩展,同时融入到数据中心服务中去,提供高带宽、低延迟的加速服务;
2. FPGA是可编程的,方便用户开发自己的程序;
3. 微软为自己的神经网络模型CNTK提供了编译器和开发环境。
为什么微软选择了FPGA?因为微软和Google是两种不同的基因,Google喜欢尝试新技术,所以自然要用TPU去追求最高的性能。但是,微软是一家商业文化很重的公司,选择一个方案看的是性价比和商业价值。做专用芯片尽管很炫,但是是否真的值得?
做芯片主要的缺点是投资大、时间周期长,芯片做好后里面的逻辑就不能修改。人工智能的算法一直在快速迭代,而做芯片至少要一两年的时间,意味着只能支持旧的架构和算法。如果芯片想要支持新的算法,就要做成通用型,提供指令集给用户编程,通用性又会降低性能,增加功耗,因为有些功能是浪费的。所以不少芯片公司尽管做了芯片,但是很多产品还是FPGA做的,比如比特大陆的挖矿机,芯片做出来就已经无法支持新的挖矿算法了。
阿呆8年前在微软亚洲研究院参与用FPGA+Open Channel SSD加速Bing搜索引擎的研究,那个时候FPGA做机器学习性能已经可以甩CPU几条大街了,同时还能节省购买服务器的成本,降低散热、土地等成本。所以微软选择FPGA是基于商业考虑和长期积累和探索的经验。
CPU、GPU、ASIC和FPGA横向对比
我们现在常见的硬件计算平台包括CPU、GPU、ASIC和FPGA。CPU是最通用的,有成熟的指令集,例如X86、ARM、MIPS、Power等,用户只要基于指令集开发软件就能使用CPU完成各种任务。但是,CPU的通用性决定了计算性能是最差的,在现代计算机中,很多计算都需要高度的并行和流水线架构,但是,CPU尽管流水线很长,计算核心数最多只有几十个,并行度不够。比如看一个高清视频,那么多像素要并行渲染,CPU就拖后腿了。
GPU克服了CPU并行度不够的缺点,把几百上千个并行计算核心堆到一个芯片里,用户用GPU的编程语言,比如CUDA、OpenCL等就可以开发程序用GPU来加速应用。但是,GPU也有严重的缺点,就是最小单元是计算核心,还是太大了。在计算机体系结构中,有一个很重要的概念就是粒度,粒度越细,就意味着用户可以发挥的空间越多。就跟盖楼一样,如果用小小的砖头,可以做出很多漂亮的造型,但是建设时间久,如果用混凝土预制件,很快就盖好大楼了,可是楼的样式就受到限制。如下图,就是预制件盖楼,搭积木一样,很快,可是都长得差不多,想盖的别的楼就不行。

ASIC克服了GPU粒度太粗的缺点,能让用户从晶体管级开始自定义逻辑,最后交给芯片代工厂生产出专用芯片。不管是性能还是功耗,都比GPU好很多,毕竟从最底层开始设计,没有浪费的电路,而且追求最高的性能。但是ASIC也有很大的缺点:投资大、开发周期长、芯片逻辑不能修改。现在做一款大规模芯片,至少需要几千万到几亿的投资,时间周期一两年左右,尤其是AI芯片,没有通用IP,很多要自己开发,时间周期更久。芯片做好后,如果有大问题或者功能升级(有些小问题可以通过预留的逻辑修改金属层连线解决),还不能直接修改,而要重新修改版图,交付工厂流片。
所以,最后就回到了FPGA:兼顾ASIC计算粒度细和GPU可编程的优点。FPGA的计算粒度很细,可以到与非门级别,但是逻辑还能修改,是可编程的。
FPGA入门
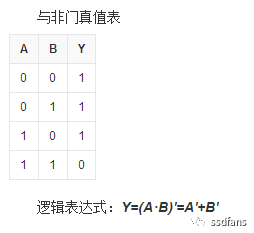
我们上大学学计算机,首先学习的基础知识是布尔代数,从与非门等逻辑门出发,可以搭出加法器、乘法器等数字逻辑,最后一级级组合,实现很复杂的计算功能(阿呆这里八卦一下,深度学习的泰斗Hinton教授是布尔的孙子的儿子)。在ASIC里面,与非门通过晶体管实现,但是晶体管无法做到可编程,必须要做成版图,送到芯片代工厂生产才能用。那怎样做到数字逻辑也能可编程呢?我们都知道,数字逻辑可以用真值表来表示,如下图就是与非门的真值表。
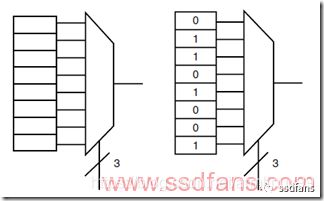
FPGA的发明人想了一个办法,就是用一个查找表来存储真值表的输出结果。如下图就是一个3bit的异或门查找表,3bit一共是8个状态,查找表保存了每个状态的结果,输入的3个bit作为索引,直接从表里读到计算结果,通过一个选择开关输出。这样避免了搭建计算逻辑,同时简化了芯片结构,只需要在芯片里面放许许多多的查找表,大家一起级联和组合就能实现复杂的逻辑和计算。目前主流的FPGA采用SRAM工艺,就是把查找表的状态都保存在SRAM里面,
但是,仅仅有查找表是不够的,数字集成电路的根是时钟,所有的逻辑按照时钟节拍来同步。举个例子,几个流氓打群架,是没有章法的,但是几万人的大军作战,如果还是各打各的,就发挥不了群体的优势。比如士兵与士兵之间如何配合?连与连之间如何分工合作?大军作战需要讲究阵法,中国古代的战神们就熟读兵书,会用八卦阵、长蛇阵等阵法,按照统一的号令指挥大军作战,无往不利。比如,法正和黄忠搭配,在定军山对山摆好阵势,法正站在山顶举令旗指挥,在他的号令下,最终老将黄忠把悍将夏侯渊劈作两半,就是靠阵法以弱胜强的例子。FPGA里面有几十万甚至百万个查找表,需要统一的号令来行动,这就是时钟。
下图是FPGA内部的基本单元,查找表+D触发器+选择开关。D触发器用来存储,查找表是组合逻辑。每个时钟周期会输出一个值,通过选择开关来选择用查找表还是D触发器。
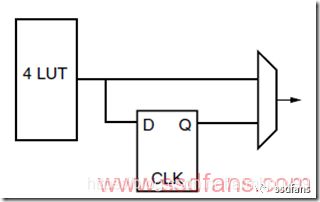
如果你看明白了上面FPGA的基本单元,你就理解了数字电路的基础——RTL,Register Transfer Level,寄存器传输级。数字电路包含两个基本部分:组合逻辑和时序逻辑,组合逻辑就是我们前面讲的布尔代数,可以做逻辑运算,但是没有记忆功能,上图中的查找表就是起了组合逻辑的作用。时序逻辑是带有记忆功能,可以按照时钟节拍控制输入输出,上图中的D触发器起了记忆功能,我们叫做寄存器。这样,组合逻辑和时序逻辑结合起来,我们就可以从这个层面设计大规模数字电路,叫做RTL设计,就是说从组合逻辑和时序逻辑级别来设计复杂的计算系统。
FPGA如何实现可编程?
那么问题来了,FPGA怎么实现可编程?如果要控制上面的基本单元,需要存好查找表的几个状态值,比如4输入查找表,就要存16bit,同时要存1个组合逻辑的选择bit和1个D触发器初始值bit。FPGA把这些配置数据保存在SRAM里面,并配置到每个基本单元中,通过写自定义数据到SRAM,就实现了对整个FPGA逻辑的可编程。
有了上面的基本逻辑单元还不够,多个基本逻辑怎么级联?级联的连接部分怎么可编程?
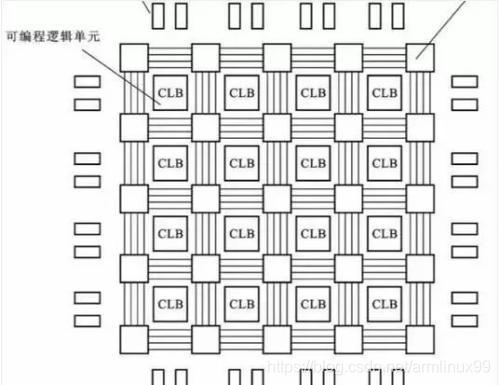
下图是FPGA内逻辑块之间互联的结构图。逻辑块的输入输出通过连接块Connection Block CB和交换块结合级联到其他的逻辑块,连接块决定逻辑块的信号连到哪根连接线上,交换块决定哪些连接线是通的,把逻辑块需要的信号连到相邻的逻辑块。连接块和交换块都是可以基于SRAM方法编程的,连接块里面是一些选择开关,交换块里面是一些交换器。
看得出来,连接线远比逻辑块更复杂,在现代FPGA芯片中,连线一般占了90%的面积,真正的逻辑部分只有10%左右面积。
FPGA的扩展资源
FPGA里面只是上面的组合逻辑是不够的,因为用户有时候不想自己搭逻辑,有些常用的逻辑希望直接用现成的。所以现代FPGA自带了很多常用的计算单元,比如加法器、乘法器、片上RAM,甚至嵌入式CPU,它们不是通过查找表搭的,而是跟ASIC一样,用晶体管搭成,这样更省芯片面积,同时性能更好。这些计算单元可以让用户配置和组合。
比如,深度学习中会使用大量的乘法器,这个时候,FPGA内部提供很多乘法器就发挥了很大的作用,这些乘法器和用户逻辑结合,可以实现很多人工智能计算,并达到高性能。
本文来源于 http://m.elecfans.com/article/691499.html